arXiv: 2604.18137 · PDF
Authors: Kosuke Matsushima, Yasuyuki Okoshi, Masato Motomura, Daichi Fujiki
Primary category: cs.AR · all: cs.AI, cs.AR, cs.LG
Matched keywords: large language model, llm, rag, kv cache, quantization, attention, transformer, gpu, latency
TL;DR
AQPIM is a PIM-aware activation quantization framework that applies Product Quantization (PQ) directly inside memory to shrink KV-cache footprint and accelerate LLM attention, achieving 3.4× speedup over SOTA PIM baselines while slashing GPU-CPU communication overhead.
Key Ideas
- Activation (KV cache) memory, not just weights, is the real PIM capacity wall for long-context LLMs.
- Clustering-based vector quantization (specifically PQ) aligns with activation statistics and PIM’s internal bandwidth.
- Quantization performed inside memory enables direct compute on compressed data.
- Algorithmic tweaks restore PQ accuracy for modern LLMs.
Approach
AQPIM builds a PIM-specialized activation quantization pipeline around Product Quantization. Activations are split into sub-vectors, clustered, and stored as codebook indices directly in PIM banks. Attention computation then operates on the compressed representation, exploiting PIM’s high internal bandwidth. Several (unspecified) algorithmic optimizations mitigate PQ’s accuracy loss on LLM activations.
Experiments
The abstract does not list datasets, specific LLMs, baselines, or metrics. It only references comparison against a “SOTA PIM approach” and measurements of GPU-CPU communication share of decoding latency. Details are thin.
Results
- 3.4× speedup vs. a SOTA PIM baseline.
- Reduces GPU-CPU communication, which otherwise consumes 90–98.5% of decoding latency.
- Accuracy impact quantified only qualitatively in the abstract.
Why It Matters
Long-context inference is increasingly memory-bound on KV cache rather than weights. AQPIM reframes PIM design around activation compression, potentially making PIM-augmented LLM serving viable for long contexts and reducing costly host-device traffic—relevant for AI-infra teams exploring heterogeneous memory/compute stacks for inference.
Connections to Prior Work
- Processing-in-Memory for ML (UPMEM, Newton, SK Hynix AiM, Samsung HBM-PIM).
- KV-cache compression and quantization (KIVI, H2O, SmoothQuant, AWQ).
- Product Quantization from ANN search (Jégou et al.) and its reuse in retrieval-augmented and attention approximations.
- Sparse/efficient attention (StreamingLLM, Longformer) — explicitly contrasted as locality-hostile for PIM.
Open Questions
- Which LLMs, context lengths, and tasks were tested, and what is the accuracy gap vs. FP16?
- How does AQPIM compare to KV-cache quantization methods running on GPUs directly?
- Are codebooks learned offline, online, or per-layer/head, and what is the calibration cost?
- Does the approach extend to prefill, MoE attention variants, or grouped-query attention?
- Hardware assumptions: does AQPIM require custom PIM instructions, and how portable is it across commercial PIM silicon?
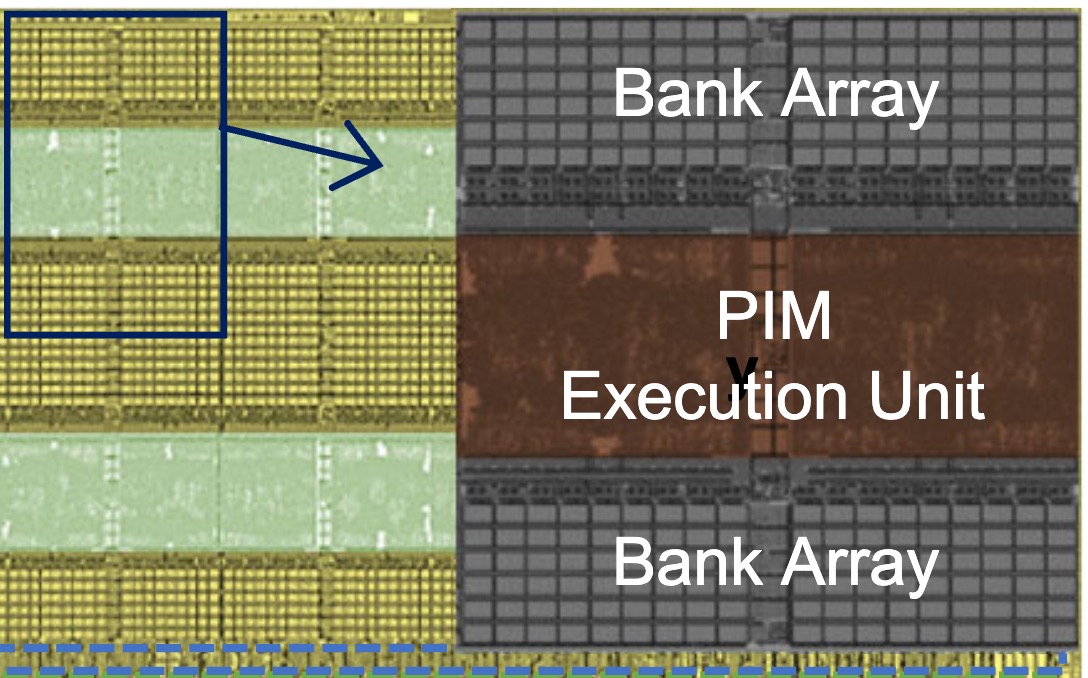
Figures
Figure 1: Figure 1 (extracted from PDF)
Original abstract
Processing-in-Memory (PIM) architectures offer a promising solution to the memory bottlenecks in data-intensive machine learning, yet often overlook the growing challenge of activation memory footprint. Conventional PIM approaches struggle with massive KV cache sizes generated in long-context scenarios by Transformer-based models, frequently exceeding PIM’s limited memory capacity, while techniques like sparse attention can conflict with PIM’s need for data locality. Existing PIM approaches and quantization methods are often insufficient or poorly suited for leveraging the unique characteristics of activations. This work identifies an opportunity for PIM-specialized activation quantization to enhance bandwidth and compute efficiency. We explore clustering-based vector quantization approaches, which align well with activation characteristics and PIM’s internal bandwidth capabilities. Building on this, we introduce AQPIM, a novel PIM-aware activation quantization framework based on Product Quantization (PQ), optimizing it for modern Large Language Models (LLMs). By performing quantization directly within memory, AQPIM leverages PIM’s high internal bandwidth and enables direct computation on compressed data, significantly reducing both memory footprint and computational overhead for attention computation. AQPIM addresses PQ’s accuracy challenges by introducing several algorithmic optimizations. Evaluations demonstrate that AQPIM achieves significant performance improvements, drastically reducing of GPU-CPU communication that can account for 90$\sim$98.5% of decoding latency, together with 3.4$\times$ speedup over a SOTA PIM approach.