arXiv: 2604.21536 · PDF
Authors: Nikita Severin, Danil Kartushov, Vladislav Urzhumov, Vladislav Kulikov, Oksana Konovalova, Alexey Grishanov, Anton Klenitskiy, Artem Fatkulin, Alexey Vasilev, Andrey Savchenko, Ilya Makarov
Primary category: cs.IR · all: cs.AI, cs.IR
Matched keywords: large language model, llm, reasoning, inference, serving, fine-tun
TL;DR
The paper proposes a knowledge distillation method that transfers LLM-generated textual user profiles into sequential recommender systems, enhancing user semantic understanding without incurring LLM inference costs at serving time.
Key Ideas
- Sequential recommenders capture temporal patterns but miss rich user semantics.
- Pre-trained LLMs can produce semantic user profiles but are too costly for real-time inference.
- Distill LLM-derived textual user profiles into sequential recommenders offline.
- No architectural changes to the recommender and no LLM fine-tuning required.
- Preserves traditional sequential-model serving efficiency.
Approach
Abstract-level only: the authors generate textual user profiles using pre-trained LLMs, then distill that knowledge into a standard sequential recommender. The distillation is user-centric, injecting LLM-derived semantic signals into the recommender’s representations during training. At serving time, only the sequential model runs — LLM calls are eliminated. Specific losses, teacher-student coupling, and profile-tokenization details are not disclosed in the abstract.
Experiments
The abstract does not specify datasets, baselines, or evaluation metrics. Thin on empirical detail.
Results
No concrete numbers are reported in the abstract. Claims of “maintained inference efficiency” and enhanced semantics are asserted but not quantified here.
Why It Matters
Offers a practical recipe for industrial recommender teams to harvest LLM semantic understanding without the latency or cost of online LLM inference. Decouples expensive LLM reasoning (offline) from latency-sensitive serving (online), which is the main blocker for LLM-enhanced ranking in production. Architecture-agnostic distillation means it can likely be slotted onto existing SASRec/BERT4Rec-style stacks.
Connections to Prior Work
- Sequential recommendation: SASRec, BERT4Rec, GRU4Rec.
- LLM-for-RecSys: P5, TALLRec, LLaMA-Rec, and prompt-based recommenders that suffer from serving cost.
- Knowledge distillation in recommenders: teacher-student ranking distillation, embedding distillation.
- Text-enhanced recommendation: UniSRec, Recformer, and content-aware sequential models.
- Profile-based personalization via LLMs (user summary / persona generation).
Open Questions
- What distillation objective is used — logit matching, embedding alignment, contrastive, or auxiliary prediction?
- How are textual profiles encoded and fused into the sequential model?
- Which LLM and which datasets; how does it compare against LLM-in-the-loop baselines and plain sequential baselines?
- How stale can profiles become before accuracy degrades, and what is the refresh strategy for active users?
- Cold-start users: does the method help when interaction history is sparse?
- Robustness to LLM hallucination in generated profiles.
- Cost/benefit of profile generation at scale (billions of users).
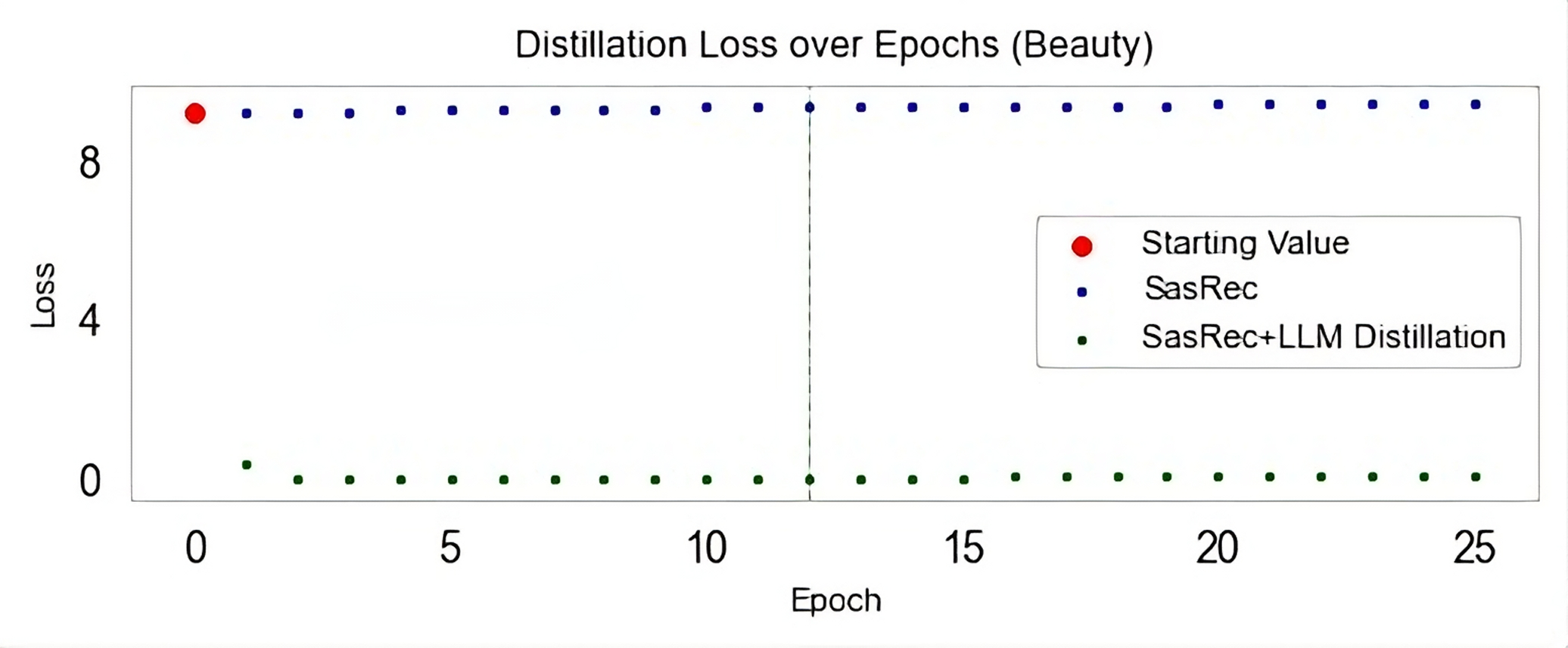
Figures
Figure 1: Figure 1 (extracted from PDF)
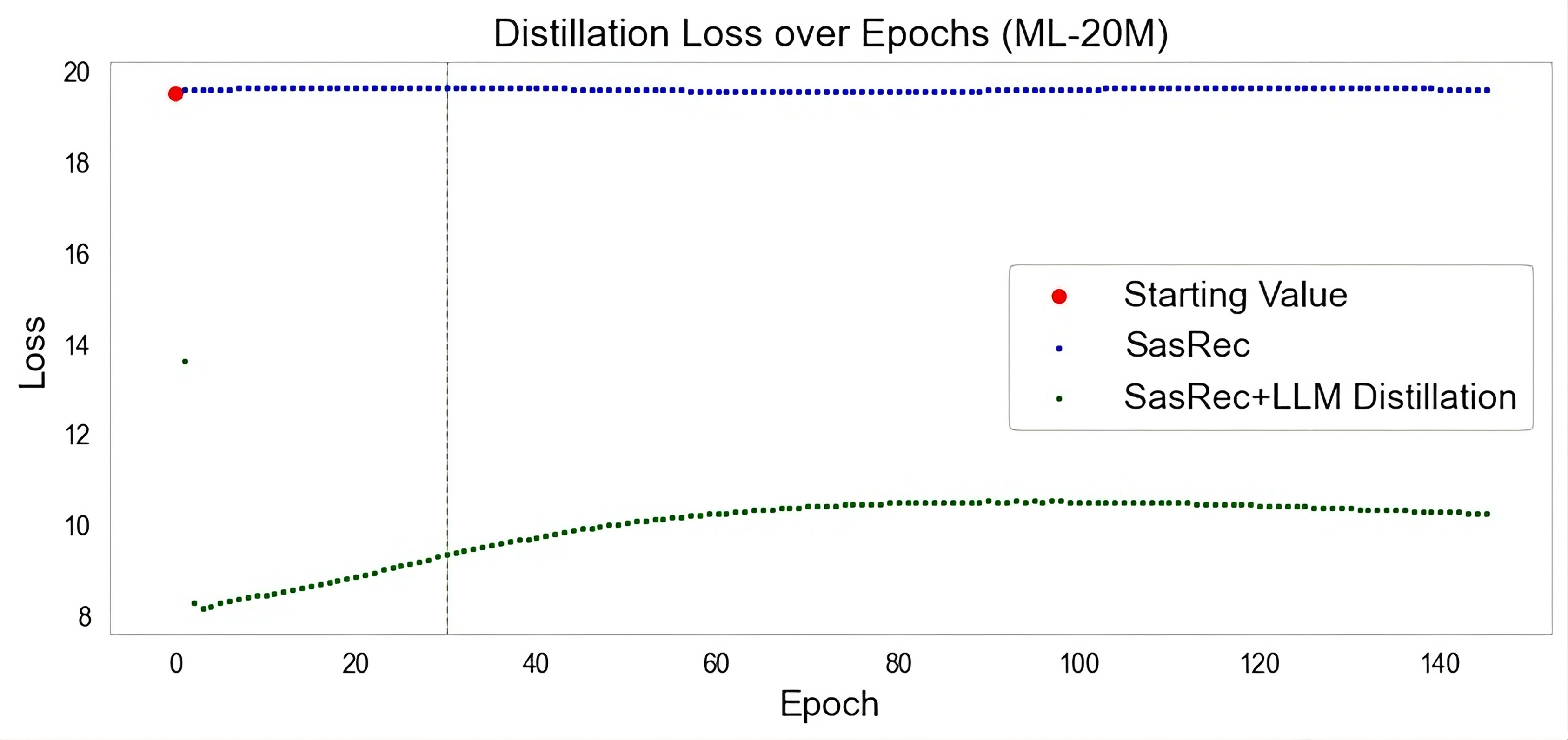
Figure 2: Figure 2 (extracted from PDF)
Original abstract
Sequential recommender systems have achieved significant success in modeling temporal user behavior but remain limited in capturing rich user semantics beyond interaction patterns. Large Language Models (LLMs) present opportunities to enhance user understanding with their reasoning capabilities, yet existing integration approaches create prohibitive inference costs in real time. To address these limitations, we present a novel knowledge distillation method that utilizes textual user profile generated by pre-trained LLMs into sequential recommenders without requiring LLM inference at serving time. The resulting approach maintains the inference efficiency of traditional sequential models while requiring neither architectural modifications nor LLM fine-tuning.