arXiv: 2604.22577 · PDF
Authors: Manyi Zhang, Ji-Fu Li, Zhongao Sun, Xiaohao Liu, Zhenhua Dong, Xianzhi Yu, Haoli Bai, Xiaobo Xia
Primary category: cs.AI · all: cs.AI, cs.CL
Matched keywords: agent, reasoning, inference, serving, quantization, latency
TL;DR
QuantClaw is a plug-and-play precision-routing plugin for the OpenClaw agent system that dynamically assigns quantization precision per task, cutting cost up to 21.4% and latency 15.7% on GLM-5 (FP8 baseline) without degrading task quality.
Key Ideas
- Quantization sensitivity in agent workflows is highly task-dependent, not uniform.
- Precision should be treated as a dynamic resource, routed per request.
- A lightweight plugin can sit in front of OpenClaw without increasing user complexity.
Approach
The authors first profile quantization sensitivity across diverse OpenClaw workflows (long-context, multi-turn reasoning). Based on those profiles, they build QuantClaw, a routing plugin that inspects task characteristics and dispatches lightweight tasks to lower-precision configurations (e.g., more aggressive quantization) while keeping higher precision for demanding workloads. Routing is plug-and-play over existing FP8/quantized backends.
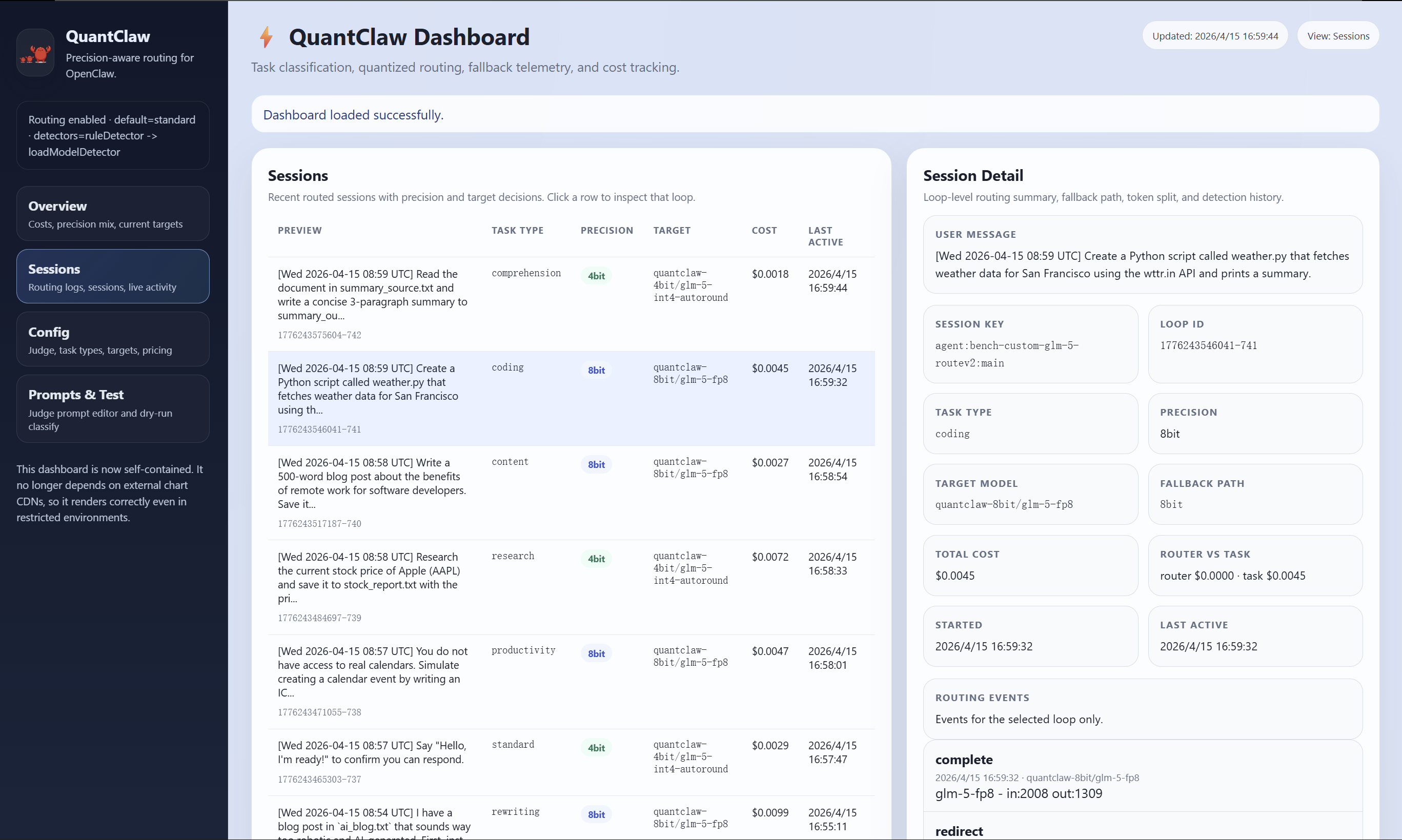
Experiments
- Platform: OpenClaw agent system with GLM-5 backbone, FP8 as baseline precision.
- Workloads: a range of agent tasks spanning light and heavy reasoning (abstract does not enumerate benchmarks).
- Metrics: task performance (quality), monetary cost, end-to-end latency.
Results
- Up to 21.4% cost savings and 15.7% latency reduction versus FP8 GLM-5 baseline.
- Task performance maintained or improved, suggesting lower precision suffices for easy tasks without hurting hard-task accuracy.
- Abstract reports only aggregate headline numbers; per-task breakdowns are not summarised here.
Why It Matters
For agent/LLM infra practitioners, it reframes quantization from a static deploy-time choice to a runtime routing decision. That unlocks cheaper agent inference stacks without bespoke per-workflow tuning, and pairs naturally with multi-precision serving fleets already common in production.
Connections to Prior Work
- Mixed-precision and dynamic quantization (GPTQ, AWQ, SmoothQuant, FP8 training/inference).
- Model routing / cascading systems (FrugalGPT, RouteLLM) that pick cheap vs. expensive models per query — QuantClaw picks precision instead of model.
- Agent efficiency work on long-context and multi-turn cost reduction (speculative decoding, KV-cache compression).
Open Questions
- How is the router trained and how robust is it to distribution shift across new agent tools?
- What is the routing overhead, and does it amortise on short tasks?
- Behavior on non-GLM backbones and below FP8 (INT4/INT2)?
- Worst-case quality regressions on individual tasks, not just averages.
- Interaction with KV-cache quantization and speculative decoding in the same stack.
Original abstract
Autonomous agent systems such as OpenClaw introduce significant efficiency challenges due to long-context inputs and multi-turn reasoning. This results in prohibitively high computational and monetary costs in real-world development. While quantization is a standard approach for reducing cost and latency, its impact on agent performance in realistic scenarios remains unclear. In this work, we analyze quantization sensitivity across diverse complex workflows over OpenClaw, and show that precision requirements are highly task-dependent. Based on this observation, we propose QuantClaw, a plug-and-play precision routing plugin that dynamically assigns precision according to task characteristics. QuantClaw routes lightweight tasks to lower-cost configurations while preserving higher precision for demanding workloads, saving cost and accelerating inference without increasing user complexity. Experiments show that our QuantClaw maintains or improves task performance while reducing both latency and computational cost. Across a range of agent tasks, it achieves up to 21.4% cost savings and 15.7% latency reduction on GLM-5 (FP8 baseline). These results highlight the benefit of treating precision as a dynamic resource in agent systems.