arXiv: 2604.22345 · PDF
Authors: Weixu Zhang, Ye Yuan, Changjiang Han, Yuxing Tian, Zipeng Sun, Linfeng Du, Jikun Kang, Hong Kang, Xue Liu, Haolun Wu
Affiliations: McGill University, Mila - Quebec AI Institute, MBZUAI, University of Montreal, Salesforce
Primary category: cs.CL · all: cs.CL
Matched keywords: large language model, llm, rag, inference, serving, attention, transformer
TL;DR
The paper posits that LLM personalization is concentrated in a sparse set of “Preference Heads” and introduces Differential Preference Steering (DPS), a training-free method that identifies these heads via causal masking and contrasts logits with/without them at decoding to amplify user-aligned outputs.
Key Ideas
- Hypothesis: a sparse subset of attention heads (Preference Heads) causally encode user-specific stylistic/topical preferences.
- Preference Contribution Score (PCS) quantifies each head’s causal impact on user-aligned generation.
- Differential Preference Steering (DPS): training-free, inference-time personalization via logit contrast.
- Mechanistic interpretability lens on where personalization emerges in transformers.
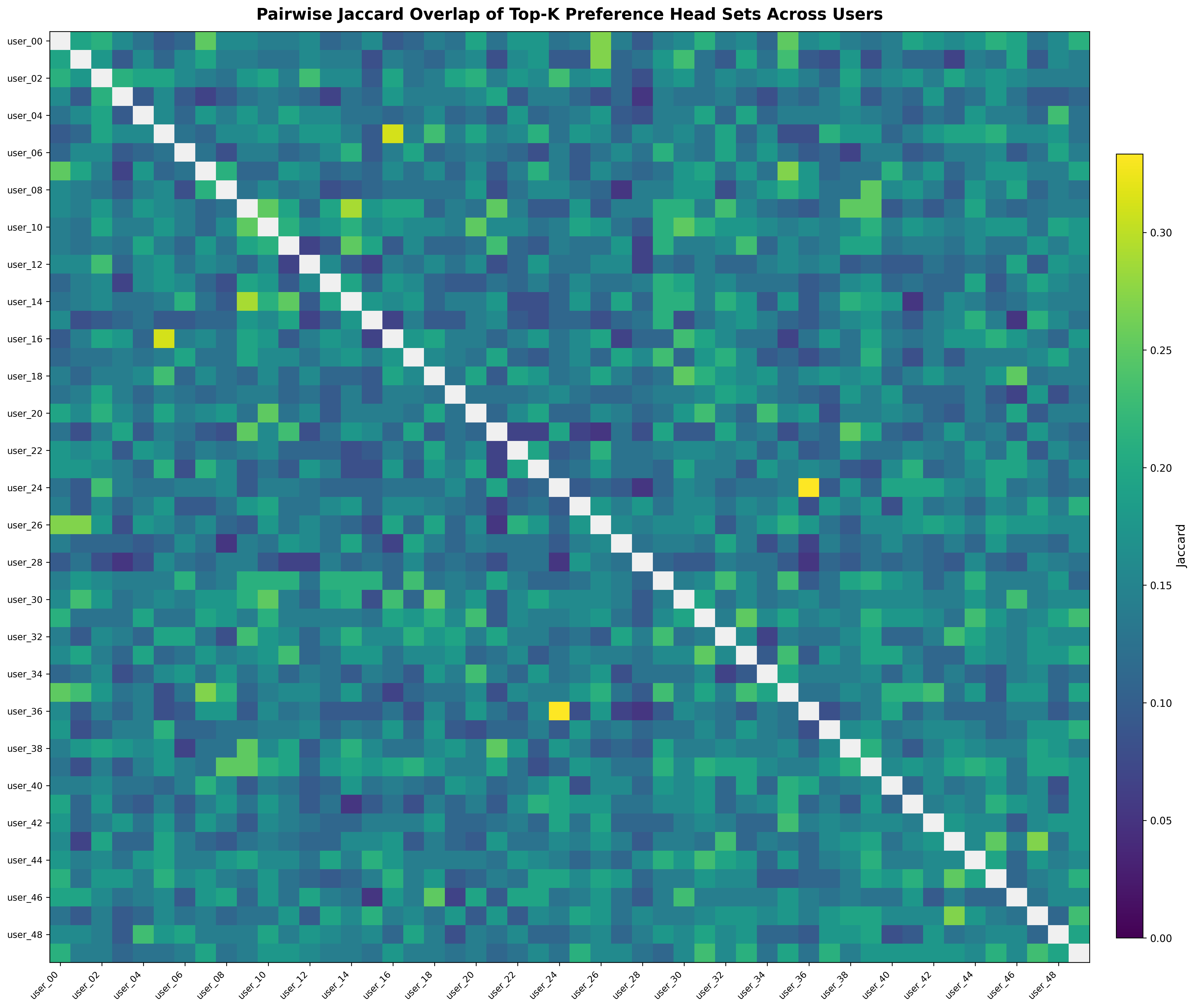
- Preference Heads are sparse within users and show limited overlap across users, motivating cluster-aware discovery.
Approach
- Head discovery: causal masking analysis computes PCS per attention head, measuring how masking it degrades user-aligned outputs.
- Selection: retain top-K heads with highest PCS as Preference Heads.
- Decoding: run forward passes with and without Preference Heads active; contrast the two logit distributions to amplify the preference-aligned direction (analogous to contrastive decoding).
- No parameter updates — purely inference-time steering.
Experiments
- Widely used personalization benchmarks (specific names not given in the abstract).
- Multiple LLM backbones evaluated.
- Metrics cover personalization fidelity, content coherence, and computational overhead; accuracy and F1 also reported as a function of K.
- Baselines implied to include prompt engineering and fine-tuning on user data, though the abstract is thin on specifics.
Results
- Consistent gains in personalization fidelity across benchmarks and LLMs.
- Coherence preserved; overhead kept low (training-free, one extra masked forward pass at decode).
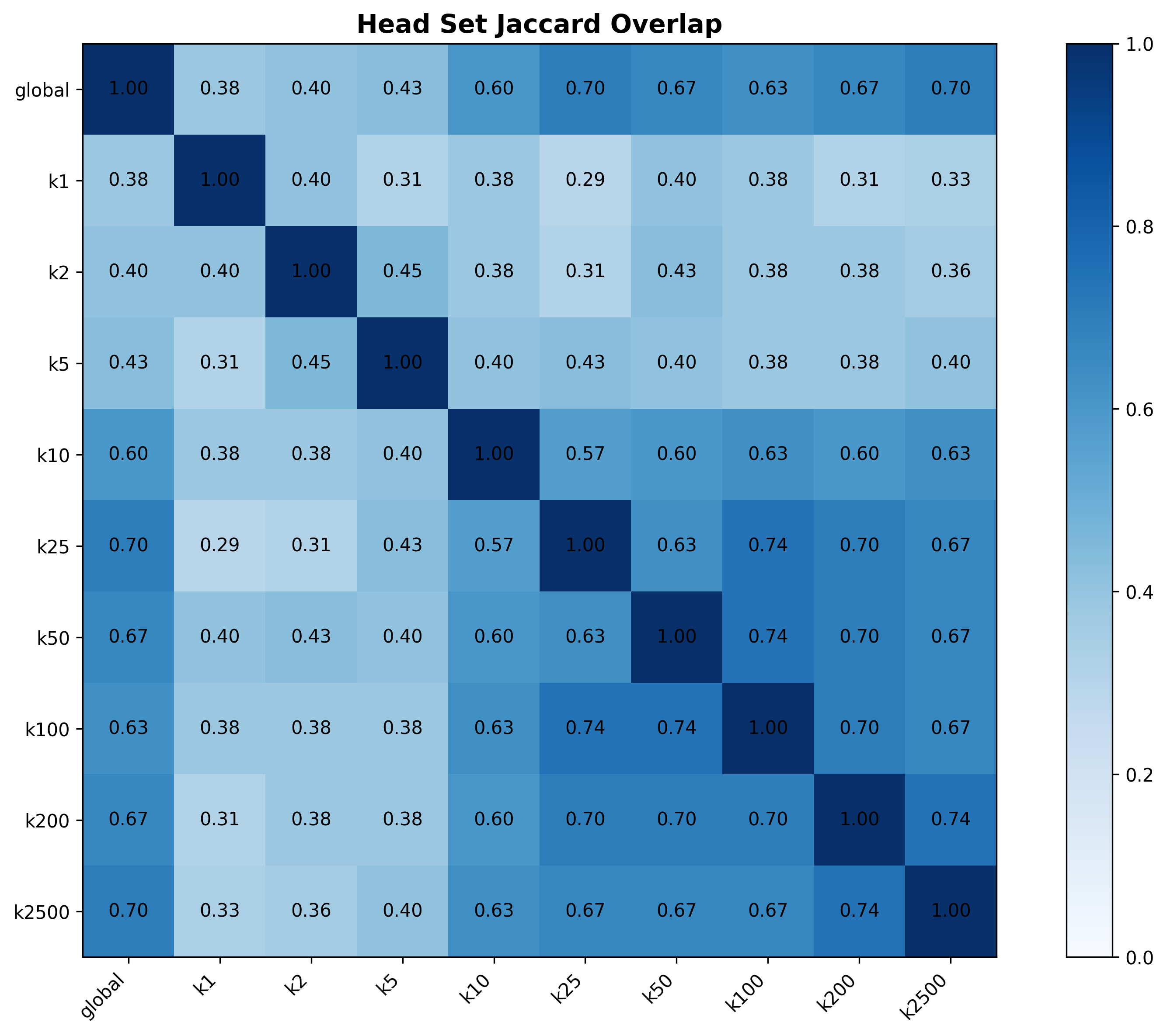
- Accuracy/F1 stable across a wide range of K, saturating at moderate K — confirming sparsity of personalization signal.
- Abstract gives no concrete numerical deltas; headline magnitudes unverifiable from the abstract alone.
Why It Matters
Gives practitioners a lightweight, interpretable knob for per-user adaptation without fine-tuning or storing user-specific weights — attractive for multi-tenant inference. Also surfaces where personalization lives mechanistically, supporting auditing and safer deployment of persona-conditioned LLMs.
Connections to Prior Work
- Mechanistic interpretability of attention heads (induction heads, function vectors, circuit analysis).
- Causal mediation / activation patching for head-level attribution.
- Contrastive decoding and DoLa-style logit arithmetic for controllable generation.
- Personalization via prompt engineering, PEFT/LoRA fine-tuning, and retrieval-augmented user modeling.
Open Questions
- Which benchmarks, models, and baselines exactly, and by how much does DPS beat them?
- How stable are Preference Heads across domains, languages, and time?
- Can heads be clustered/shared across users to scale, given the low cross-user Jaccard overlap?
- Interaction with safety-relevant heads — could DPS be abused to amplify undesired personas?
Original abstract
Large Language Models (LLMs) exhibit strong implicit personalization ability, yet most existing approaches treat this behavior as a black box, relying on prompt engineering or fine tuning on user data. In this work, we adopt a mechanistic interpretability perspective and hypothesize the existence of a sparse set of Preference Heads, attention heads that encode user specific stylistic and topical preferences and exert a causal influence on generation. We introduce Differential Preference Steering (DPS), a training free framework that (1) identifies Preference Heads through causal masking analysis and (2) leverages them for controllable and interpretable personalization at inference time. DPS computes a Preference Contribution Score (PCS) for each attention head, directly measuring its causal impact on user aligned outputs. During decoding, we contrast model predictions with and without Preference Heads, amplifying the difference between personalized and generic logits to selectively strengthen preference aligned continuations. Experiments on widely used personalization benchmarks across multiple LLMs demonstrate consistent gains in personalization fidelity while preserving content coherence and low computational overhead. Beyond empirical improvements, DPS provides a mechanistic explanation of where and how personalization emerges within transformer architectures. Our implementation is publicly available.