arXiv: 2604.22312 · PDF
Authors: Long Cheng, Ritchie Zhao, Timmy Liu, Mindy Li, Xianjie Qiao, Kefeng Duan, Yu-Jung Chen, Xiaoming Chen, Bita Darvish Rouhani, June Yang
Affiliations: NVIDIA
Primary category: cs.DC · all: cs.AR, cs.DC, cs.PF
Matched keywords: llm, rag, serving, speculative decoding, attention, latency
TL;DR
Guess-Verify-Refine (GVR) is a data-aware exact Top-K kernel for sparse-attention decoding on NVIDIA Blackwell that exploits temporal correlation between consecutive decode steps, delivering 1.88× average speedup over production radix-select while preserving bit-exact outputs.
Key Ideas
- Top-K selection is a real latency bottleneck in long-context sparse-attention decoding, even after indexer/attention kernels are optimized.
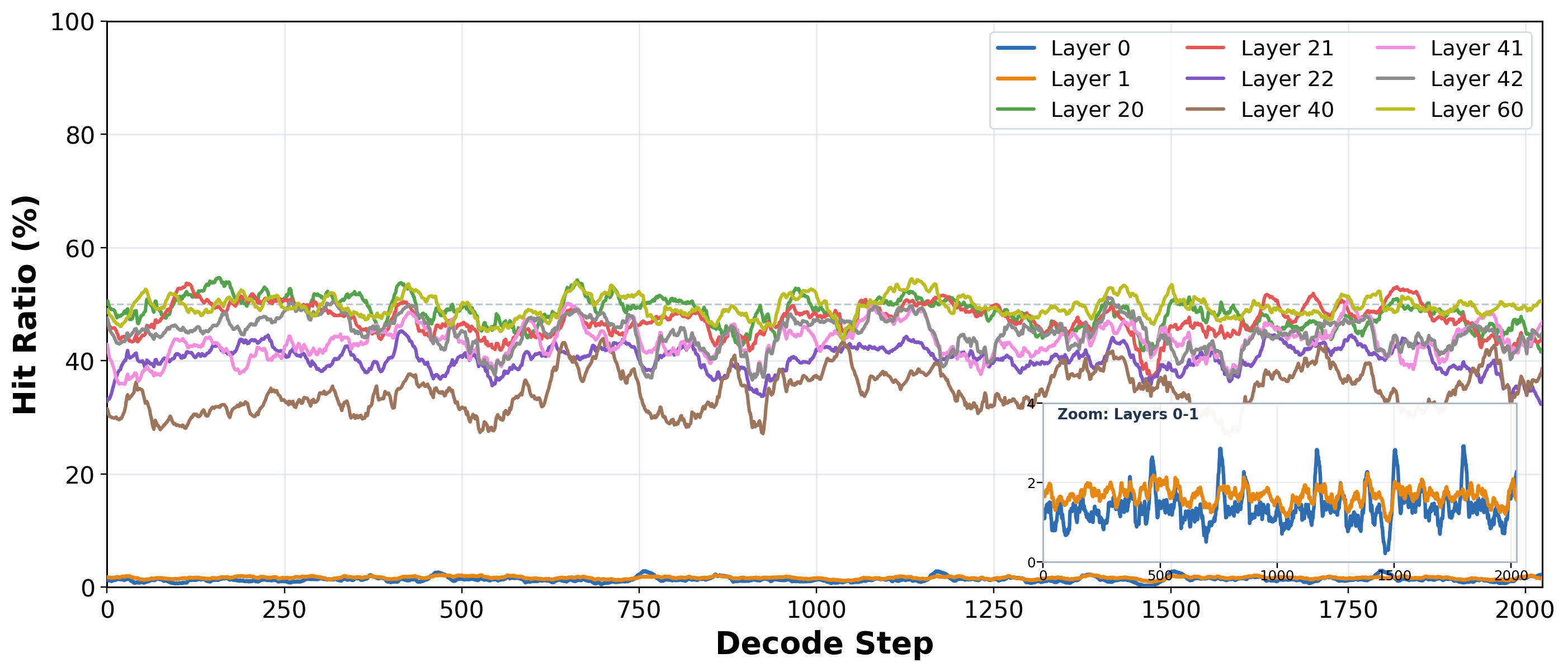
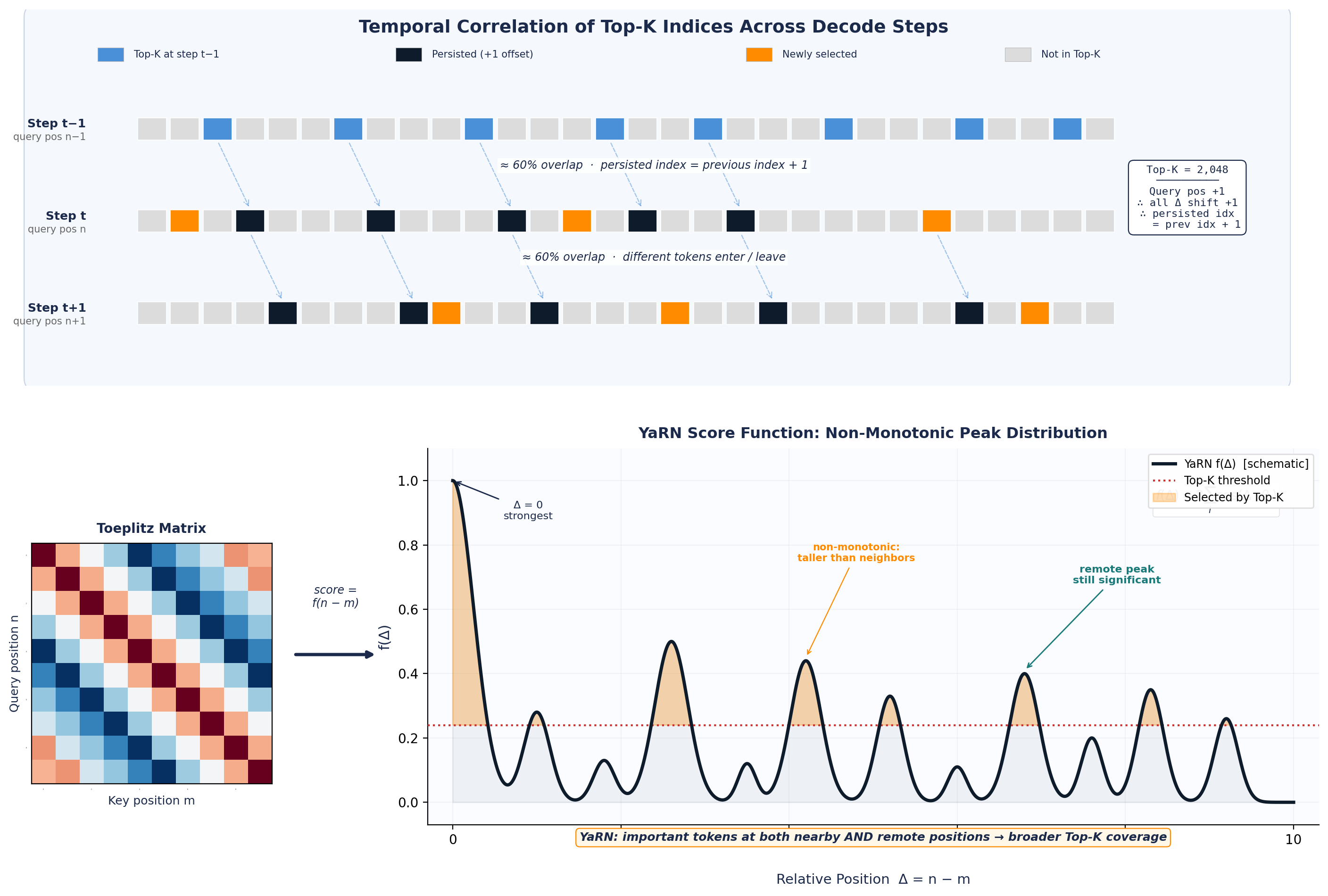
- Consecutive decode steps produce highly overlapping Top-K sets, rooted in the Toeplitz / RoPE structure of DeepSeek Sparse Attention (DSA) indexer scores.
- Previous-step Top-K can serve as a prediction signal to narrow the search, reducing global passes to 1–2.
- Exact (bit-exact) Top-K is preserved — no approximation tradeoff.
Approach
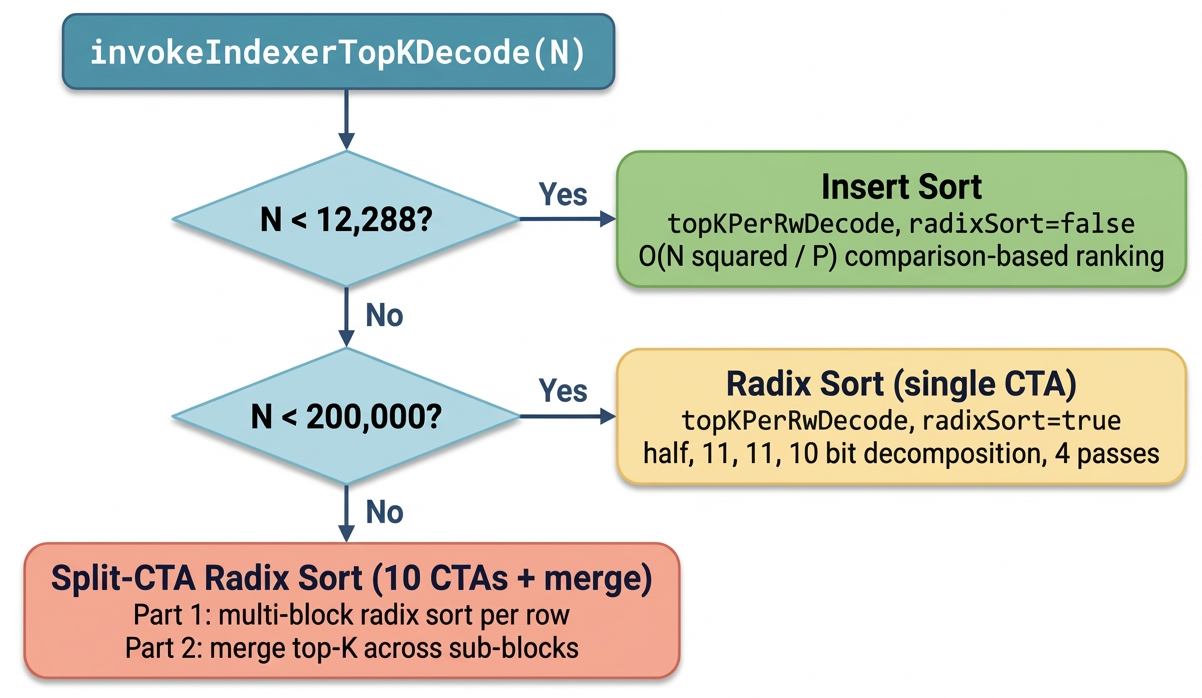
GVR replaces the existing dispatch (insert sort / radix sort / multi-CTA split by sequence length) with a four-stage pipeline: (1) Guess using prior-step Top-K plus pre-indexed statistics; (2) Verify via secant-style counting in 1–2 global passes to find a valid threshold; (3) collect candidates with a ballot-free collector; (4) Refine exact selection entirely in shared memory. Implemented inside TensorRT-LLM’s DSA stack on Blackwell.
Experiments
Real DeepSeek-V3.2 workloads integrated into TensorRT-LLM on NVIDIA Blackwell. Motivation traces use entry 1 of swe_bench_64k.jsonl from SWE-bench-derived LongSeqTasks. Baseline is the production radix-select Top-K kernel. Deployment tested in controlled TEP8 min-latency configuration with context lengths up to 100K, including speculative decoding.
Results
- 1.88× average single-operator speedup over radix-select, up to 2.42× per layer per step.
- Up to 7.52% end-to-end TPOT improvement at 100K context in TEP8 min-latency deployment.
- Gains grow with context length; smaller but positive gains under speculative decoding.
- Bit-exact Top-K outputs maintained.
Why It Matters
Moves Top-K from a fixed sort-dispatch problem to a data-aware one, removing a decode bottleneck for long-context sparse-attention LLM serving. Useful for infra teams running DeepSeek-V3.2-class models and suggests a general template for any sparse-attention decoder with temporal Top-K stability.
Connections to Prior Work
- DeepSeek Sparse Attention (DSA) and its RoPE/Toeplitz score structure.
- Radix-select and multi-CTA GPU Top-K kernels used in production inference.
- Long-context LLM serving stacks like TensorRT-LLM.
- Broader sparse/selective attention line (Top-K attention, KV selection).
Open Questions
- Does GVR generalize beyond DSA to other sparse-attention decoders lacking Toeplitz/RoPE structure?
- Behavior on non-Blackwell GPUs and older architectures.
- Robustness when temporal correlation breaks (short contexts, aggressive speculative decoding, context switches).
- Memory overhead of pre-indexed statistics at scale.
Original abstract
Sparse-attention decoders rely on exact Top-K selection to choose the most important key-value entries for each query token. In long-context LLM serving, this Top-K stage runs once per decode query and becomes a meaningful latency bottleneck even when the indexer and attention kernels are already highly optimized. We present \textbf{Guess-Verify-Refine (GVR)}, a data-aware exact Top-K algorithm for sparse-attention decoding on NVIDIA Blackwell. GVR exploits temporal correlation across consecutive decode steps: it uses the previous step’s Top-K as a prediction signal, computes pre-indexed statistics, narrows to a valid threshold by secant-style counting in 1-2 global passes, verifies candidates with a ballot-free collector, and finishes exact selection in shared memory. We connect this behavior to the Toeplitz / RoPE structure of DeepSeek Sparse Attention (DSA) indexer scores and validate the design on real DeepSeek-V3.2 workloads integrated into TensorRT-LLM. GVR achieves an average \textbf{1.88x} single-operator speedup over the production radix-select kernel, with up to \textbf{2.42x} per layer per step, while preserving bit-exact Top-K outputs. In controlled TEP8 min-latency deployment, it improves end-to-end TPOT by up to \textbf{7.52%} at 100K context, with larger gains at longer contexts and smaller but still positive gains under speculative decoding. While implemented and validated in the current TensorRT-LLM DSA stack on Blackwell, the same principle may extend to sparse-attention decoders whose decode-phase Top-K exhibits temporal stability.