arXiv: 2604.22345 · PDF
作者: Weixu Zhang, Ye Yuan, Changjiang Han, Yuxing Tian, Zipeng Sun, Linfeng Du, Jikun Kang, Hong Kang, Xue Liu, Haolun Wu
主分类: cs.CL · 全部: cs.CL
命中关键词: large language model, llm, rag, inference, serving, attention, transformer
TL;DR
论文提出 Preference Heads 假设:LLM 中少量 attention head 因果性地编码用户偏好,并据此设计训练-free 的 Differential Preference Steering (DPS) 实现可解释个性化。
核心观点
- 假设存在稀疏的 Preference Heads,负责编码用户风格与话题偏好。
- 通过因果掩码分析 (causal masking) 定位这些 heads,并用 Preference Contribution Score (PCS) 量化其影响。
- 提出 DPS:推理时对比"启用/禁用 Preference Heads"的 logits 差异,放大偏好对齐方向。
- 无需训练,兼具可解释性、低开销与可控性。
方法
DPS 分两步:
- 识别:对每个 attention head 施加因果掩码,测量其在用户对齐输出上的贡献,计算 PCS,挑选得分最高者作为 Preference Heads。
- 引导:解码阶段分别用完整模型和"屏蔽 Preference Heads"模型各得一套 logits,取差值作为个性化信号,加权放大后融合回生成分布,从而 selectively 强化偏好对齐续写。
实验
在多种常用个性化 benchmark 上、跨多个 LLM 做评测;比较对象包括 prompt-based 基线与 fine-tuning 方法;指标覆盖个性化 fidelity、内容 coherence 与计算开销。摘要未披露具体模型规模与数据集名称。
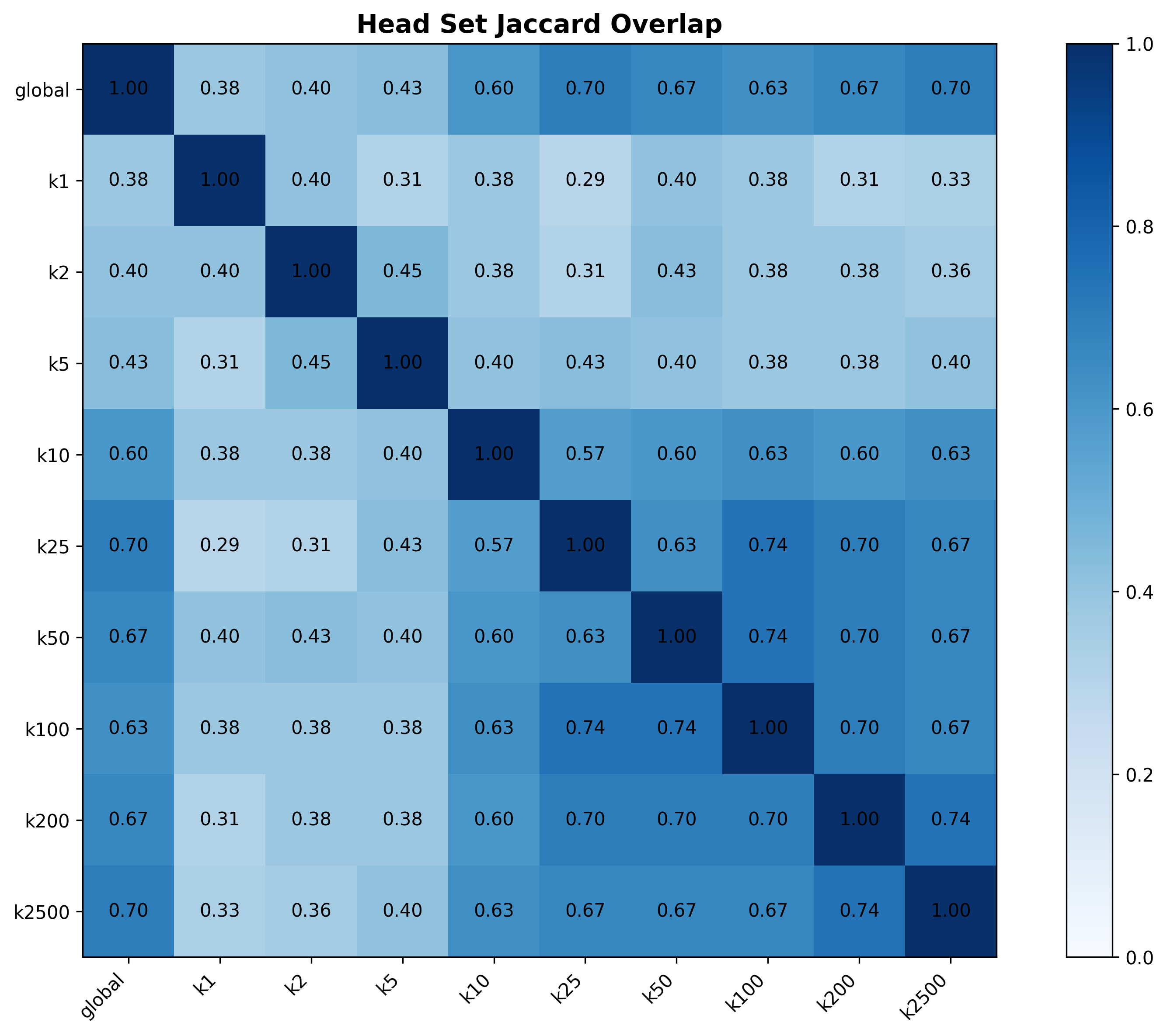
结果
报告"在不同 LLM 上一致提升个性化 fidelity,同时保持内容连贯性,额外开销低"。摘要未给出具体数值,因此绝对增益与对比强弱暂无法判断;主张依赖原文表格支撑。
为什么重要
- 对 agent/LLM 工程师:提供一种无需微调、插拔式的个性化方案,推理期即可部署,适合多用户服务。
- 对 interpretability:把"个性化"落实到具体 head 层面,给出 where/how 的机制解释。
- 对基础设施:低额外成本、可控强度,便于与现有 decoding pipeline(如 contrastive decoding)集成。
与已有工作的关系
- 延续 mechanistic interpretability 脉络(induction heads、function vectors、activation patching)。
- 方法形式上属 contrastive / steering decoding 家族(CAD、DoLa、representation engineering)。
- 与传统 personalization 路线(RLHF、LoRA fine-tune、prompt-tuning、retrieval-based persona)形成互补,强调训练-free 与可解释性。
尚未回答的问题
- Preference Heads 在不同模型家族、规模间是否稳定迁移?
- PCS 对用户样本数量与噪声的鲁棒性如何?
- 与 CAD/DoLa 等 contrastive decoding 方法的正交性与叠加收益?
- 是否存在多维偏好(风格 vs 话题)间的 head 解耦?长上下文与多轮对话下表现?
- 安全性:能否被用来放大不良偏好或绕过对齐约束?
原始摘要
Large Language Models (LLMs) exhibit strong implicit personalization ability, yet most existing approaches treat this behavior as a black box, relying on prompt engineering or fine tuning on user data. In this work, we adopt a mechanistic interpretability perspective and hypothesize the existence of a sparse set of Preference Heads, attention heads that encode user specific stylistic and topical preferences and exert a causal influence on generation. We introduce Differential Preference Steering (DPS), a training free framework that (1) identifies Preference Heads through causal masking analysis and (2) leverages them for controllable and interpretable personalization at inference time. DPS computes a Preference Contribution Score (PCS) for each attention head, directly measuring its causal impact on user aligned outputs. During decoding, we contrast model predictions with and without Preference Heads, amplifying the difference between personalized and generic logits to selectively strengthen preference aligned continuations. Experiments on widely used personalization benchmarks across multiple LLMs demonstrate consistent gains in personalization fidelity while preserving content coherence and low computational overhead. Beyond empirical improvements, DPS provides a mechanistic explanation of where and how personalization emerges within transformer architectures. Our implementation is publicly available.