arXiv: 2604.22312 · PDF
作者: Long Cheng, Ritchie Zhao, Timmy Liu, Mindy Li, Xianjie Qiao, Kefeng Duan, Yu-Jung Chen, Xiaoming Chen, Bita Darvish Rouhani, June Yang
主分类: cs.DC · 全部: cs.AR, cs.DC, cs.PF
命中关键词: llm, rag, serving, speculative decoding, attention, latency
TL;DR
GVR 利用相邻 decode 步 Top-K 的时间相关性做"猜测-验证-精炼",在 Blackwell 上把稀疏注意力的精确 Top-K 内核平均加速 1.88×,端到端 TPOT 最多提升 7.52%。
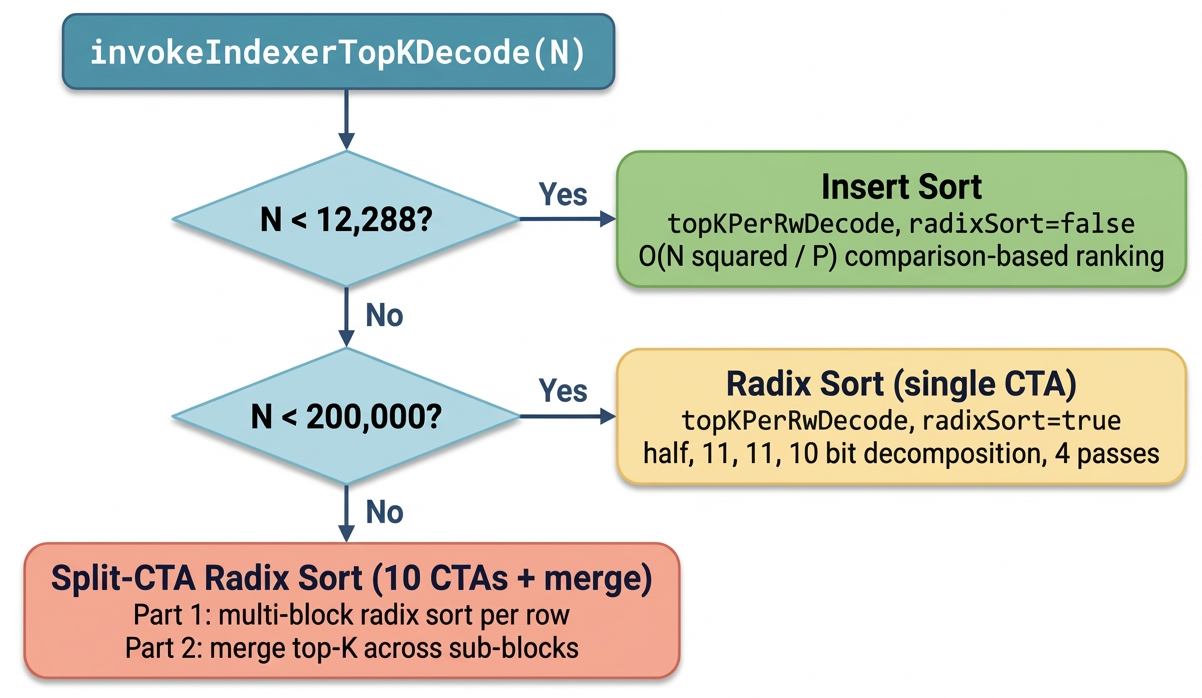
核心观点
- 稀疏注意力 decode 阶段的精确 Top-K 即使在高度优化后仍是延迟瓶颈。
- 连续 decode step 间 Top-K 结果具有强时间相关性,可作为预测信号。
- 利用 DSA indexer 分数的 Toeplitz / RoPE 结构,可设计 data-aware 的精确 Top-K 算法。
- 在保持 bit-exact 输出的前提下显著优于 production radix-select。
方法
GVR 分三阶段:
- Guess:以上一 decode step 的 Top-K 作为候选阈值预测。
- Verify:基于预先统计量,通过 secant-style 计数在 1-2 次 global pass 内收敛到有效阈值;用 ballot-free collector 收集候选。
- Refine:在 shared memory 内完成精确选择,保证 bit-exact。 算法与 DeepSeek Sparse Attention (DSA) indexer 分数的 Toeplitz / RoPE 结构相结合,专为 NVIDIA Blackwell 架构优化。
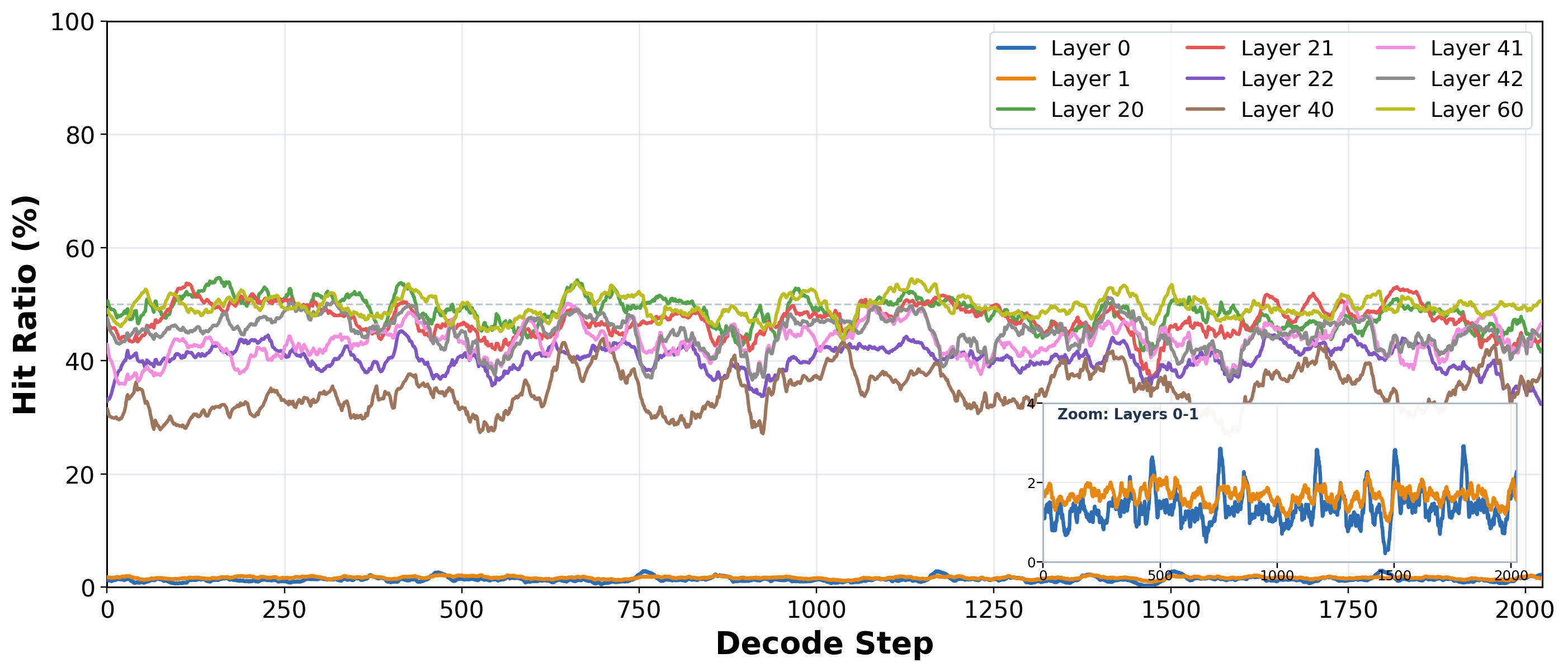
实验
- 模型 / 栈:DeepSeek-V3.2,集成进 TensorRT-LLM 的 DSA pipeline。
- 硬件:NVIDIA Blackwell,TEP8 min-latency 部署配置。
- 基线:production radix-select kernel。
- 指标:单算子加速比、端到端 TPOT、不同 context 长度(含 100K)及 speculative decoding 场景。
结果
- 单算子平均 1.88×、单层单步最高 2.42× 加速。
- 100K context 下 end-to-end TPOT 最多提升 7.52%;上下文越长收益越大。
- speculative decoding 下收益更小但仍为正。
- 输出与基线 bit-exact 一致。
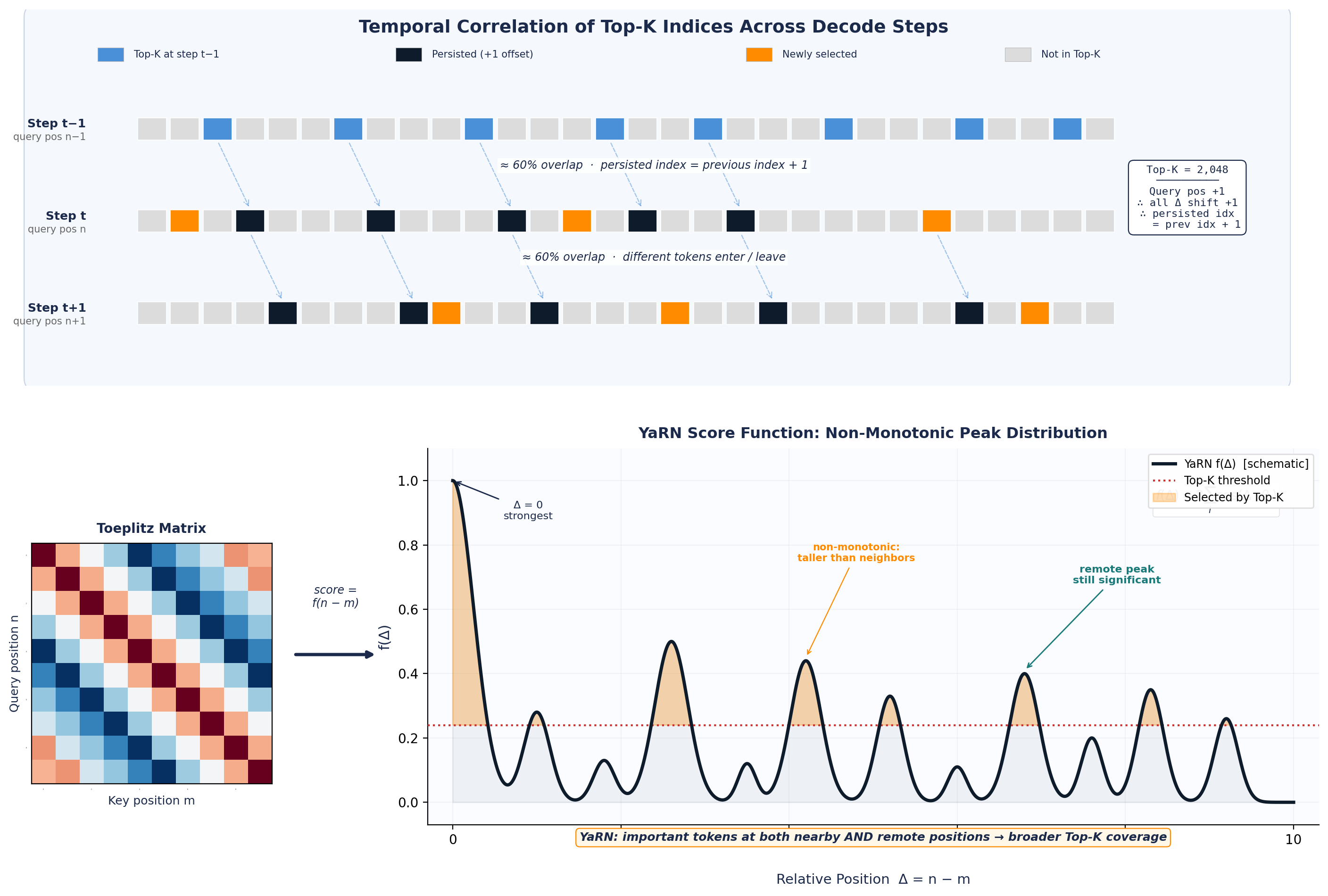
为什么重要
对长上下文 LLM serving,Top-K 选择往往被忽视却是真实瓶颈。GVR 把"时间局部性"引入 kernel 级别设计,在不损失精度的前提下给稀疏注意力 decode 实打实的延迟收益,直接落地到 TensorRT-LLM 生产栈,对做 LLM 推理基础设施的工程师有直接参考价值。
与已有工作的关系
- 建立在 DeepSeek Sparse Attention (DSA) 与 DeepSeek-V3.2 之上。
- 对比对象为经典 radix-select GPU Top-K。
- 与 RoPE / Toeplitz 结构化注意力分析一脉相承。
- 属于稀疏注意力(如 sparse/selective attention 系列)在 serving 侧的系统优化分支。
尚未回答的问题
- 时间相关性假设在非 DSA 的其他稀疏注意力(如可学习 sparsity、block-sparse)上是否依然成立?
- 在 prefill 阶段或非 Blackwell(Hopper/Ada)架构上的可迁移性?
- 当 Top-K 发生剧烈切换(如话题突变)时 guess 失败的最坏情况开销?
- 与更激进的 speculative / MTP decoding 组合时的收益上限?
原始摘要
Sparse-attention decoders rely on exact Top-K selection to choose the most important key-value entries for each query token. In long-context LLM serving, this Top-K stage runs once per decode query and becomes a meaningful latency bottleneck even when the indexer and attention kernels are already highly optimized. We present \textbf{Guess-Verify-Refine (GVR)}, a data-aware exact Top-K algorithm for sparse-attention decoding on NVIDIA Blackwell. GVR exploits temporal correlation across consecutive decode steps: it uses the previous step’s Top-K as a prediction signal, computes pre-indexed statistics, narrows to a valid threshold by secant-style counting in 1-2 global passes, verifies candidates with a ballot-free collector, and finishes exact selection in shared memory. We connect this behavior to the Toeplitz / RoPE structure of DeepSeek Sparse Attention (DSA) indexer scores and validate the design on real DeepSeek-V3.2 workloads integrated into TensorRT-LLM. GVR achieves an average \textbf{1.88x} single-operator speedup over the production radix-select kernel, with up to \textbf{2.42x} per layer per step, while preserving bit-exact Top-K outputs. In controlled TEP8 min-latency deployment, it improves end-to-end TPOT by up to \textbf{7.52%} at 100K context, with larger gains at longer contexts and smaller but still positive gains under speculative decoding. While implemented and validated in the current TensorRT-LLM DSA stack on Blackwell, the same principle may extend to sparse-attention decoders whose decode-phase Top-K exhibits temporal stability.