arXiv: 2604.22345 · PDF
作者: Weixu Zhang, Ye Yuan, Changjiang Han, Yuxing Tian, Zipeng Sun, Linfeng Du, Jikun Kang, Hong Kang, Xue Liu, Haolun Wu
单位: McGill University, Mila - Quebec AI Institute, MBZUAI, University of Montreal, Salesforce
主分类: cs.CL · 全部: cs.CL
命中关键词: large language model, llm, rag, inference, serving, attention, transformer
TL;DR
论文提出 Preference Heads 假设,认为 LLM 中存在稀疏的注意力头编码用户偏好,并基于此设计训练无关的 Differential Preference Steering (DPS) 框架实现可解释的个性化推理。
核心观点
- 假设 LLM 中存在稀疏的 Preference Heads:专门编码用户风格与主题偏好并对生成有因果影响的注意力头。
- 提出 Preference Contribution Score (PCS),通过 causal masking 直接度量每个 attention head 对用户对齐输出的因果贡献。
- 提出 Differential Preference Steering (DPS):训练无关,在解码时对比有/无 Preference Heads 的 logits 以放大偏好对齐信号。
- 给出了 transformer 中个性化"在哪里、如何涌现"的机制性解释。
方法
DPS 分两步:(1) 通过 causal masking 分析识别 Preference Heads——对每个 head 计算 PCS,衡量其在用户对齐输出中的因果影响;(2) 推理时做 logits 对比:同时跑开启和屏蔽 Preference Heads 的两次前向,放大二者 logits 差值,从而选择性增强偏好对齐的后续 token。整个框架无需训练或微调,仅在解码阶段介入。
实验
- 数据集:常用的个性化 benchmark(摘要未列出具体名称)。
- 模型:在多个 LLM 上评估。
- 基线与指标:与 prompt engineering / fine-tuning 等既有个性化方法对比,指标覆盖 personalization fidelity、内容连贯性、计算开销,以及 Accuracy / F1。
结果
- 在多个 LLM 与 benchmark 上,DPS 在 personalization fidelity 上取得一致提升,同时保持内容连贯性和低计算开销。
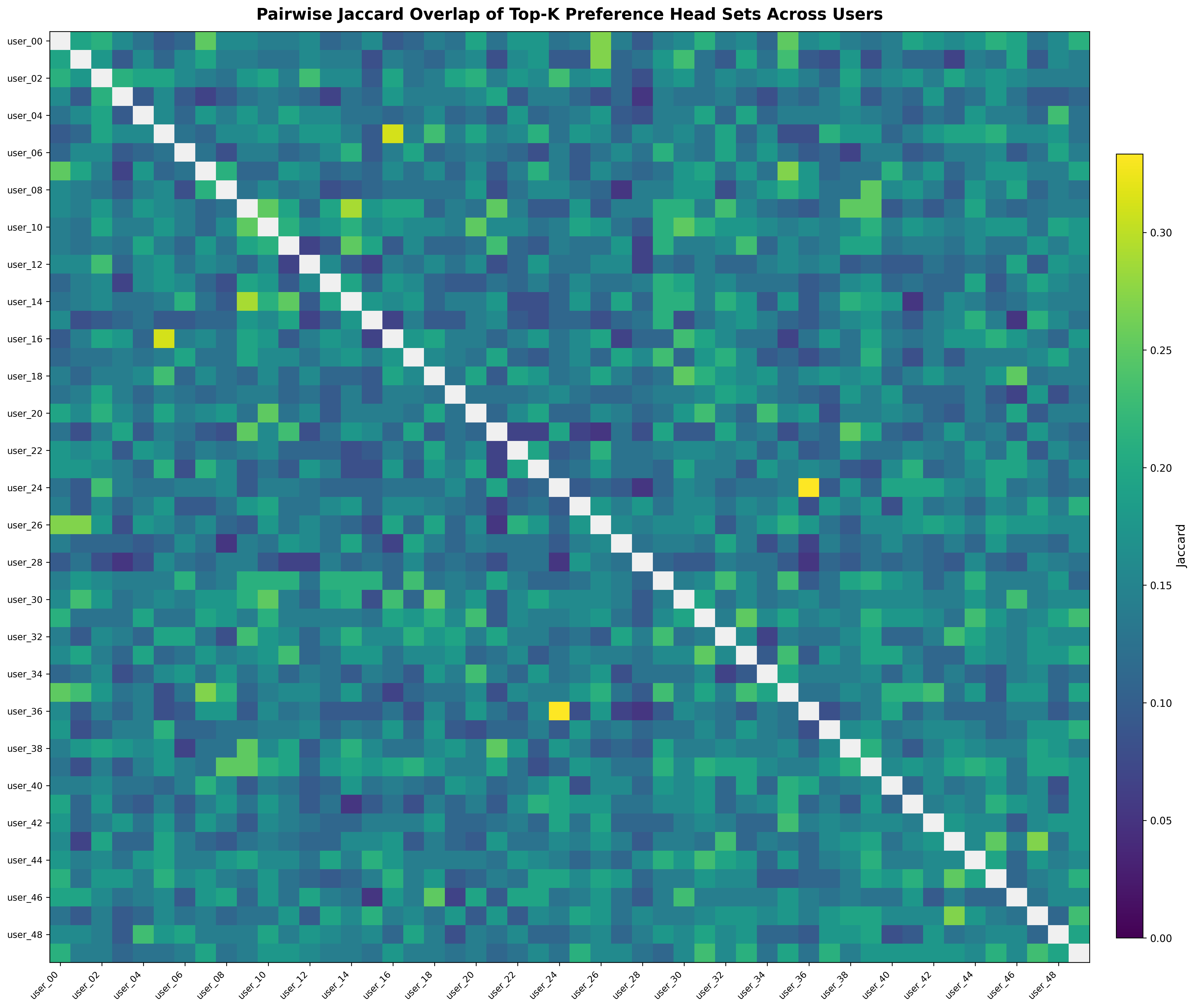
- Preference Heads 在用户内部稀疏且有因果意义,但跨用户重叠有限(Jaccard overlap 低),需做 cluster-aware 发现。
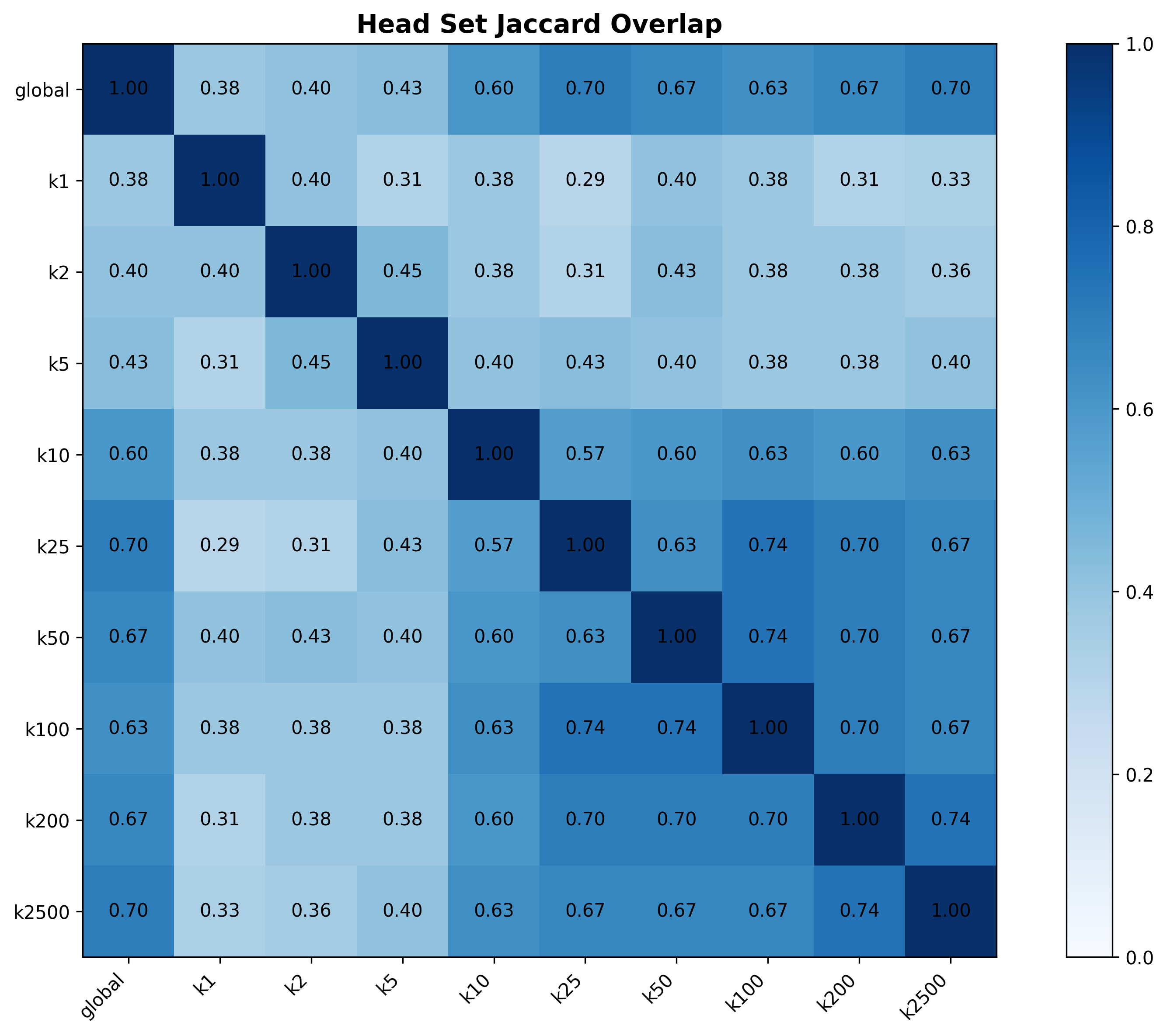
- Accuracy 与 F1 对所选 head 数 K 不敏感,在中等 K 时性能即饱和,说明个性化信号高度集中。
为什么重要
对 LLM / agent 从业者而言,DPS 提供了无需训练、低开销的可控个性化手段,并首次把"用户偏好"定位到具体 attention head,为可解释性、个性化对齐以及偏好审计(谁的偏好被激活)打开新的切入点。
与已有工作的关系
沿用 mechanistic interpretability 脉络(induction heads、function vectors、activation steering 等思路),把 causal masking / head-level intervention 应用到个性化场景;相较 RLHF、DPO、prompt-based personalization 与 user-specific fine-tuning,DPS 属于解码期 contrastive decoding 变体,近似 DoLa / Contrastive Decoding 的思路但锚定在用户偏好 head 上。
尚未回答的问题
- Preference Heads 在新用户、零样本或极长历史下如何稳健识别?
- 跨用户 cluster-aware 发现的具体代价与泛化性如何?
- 对安全、隐私(推断用户属性)与偏见放大的影响?
- 能否拓展到多模态或 agent 多轮规划中的偏好建模?
原始摘要(中文翻译)
大语言模型(LLMs)展现出很强的隐式个性化能力,但现有大多数方法将这一行为视为黑盒,依赖 prompt engineering 或在用户数据上微调。在本工作中,我们采用机制可解释性(mechanistic interpretability)的视角,假设存在一组稀疏的 Preference Heads——即编码用户特定风格与主题偏好、并对生成产生因果影响的注意力头。我们提出 Differential Preference Steering (DPS),一个训练无关的框架,它 (1) 通过 causal masking 分析识别 Preference Heads,(2) 在推理阶段利用它们实现可控且可解释的个性化。DPS 为每个注意力头计算 Preference Contribution Score (PCS),直接度量其对用户对齐输出的因果影响。在解码过程中,我们将开启与关闭 Preference Heads 的模型预测进行对比,放大个性化与通用 logits 之间的差异,从而选择性地增强偏好对齐的续写。在多个 LLM 上、广泛使用的个性化基准上的实验表明,DPS 在保持内容连贯性和低计算开销的同时,持续提升个性化保真度。除了实证改进之外,DPS 还提供了关于个性化在 transformer 架构中何处、以何种方式涌现的机制性解释。我们的实现已公开。