arXiv: 2604.22050 · PDF
作者: Mohamed Ali Souibgui, Jan Fostier, Rodrigo Abadía-Heredia, Bohdan Denysenko, Christian Marschke, Igor Peric
单位: Openchip & Softwares Technologies
主分类: cs.LG · 全部: cs.CL, cs.LG
命中关键词: llm, inference, serving, attention, transformer, throughput, latency
TL;DR
LayerBoost 基于逐层敏感度分析,对 transformer 不同层分别保留 softmax、替换为线性滑窗或完全移除注意力,仅用 10M token 蒸馏修复,高并发吞吐提升最高 68%。
核心观点
- 现有线性/混合注意力方法在所有层上统一替换,导致性能大幅下降或需大量再训练。
- 不同 transformer 层对注意力的敏感度差异显著,应按层差异化处理。
- 提出三档策略:高敏感层保留 softmax,中敏感层换成 linear sliding window,低敏感层完全移除 attention。
- 仅需 10M token 的轻量蒸馏 healing 阶段即可恢复性能。
- 在高并发与硬件受限场景下显著降低推理成本并保持质量。
方法
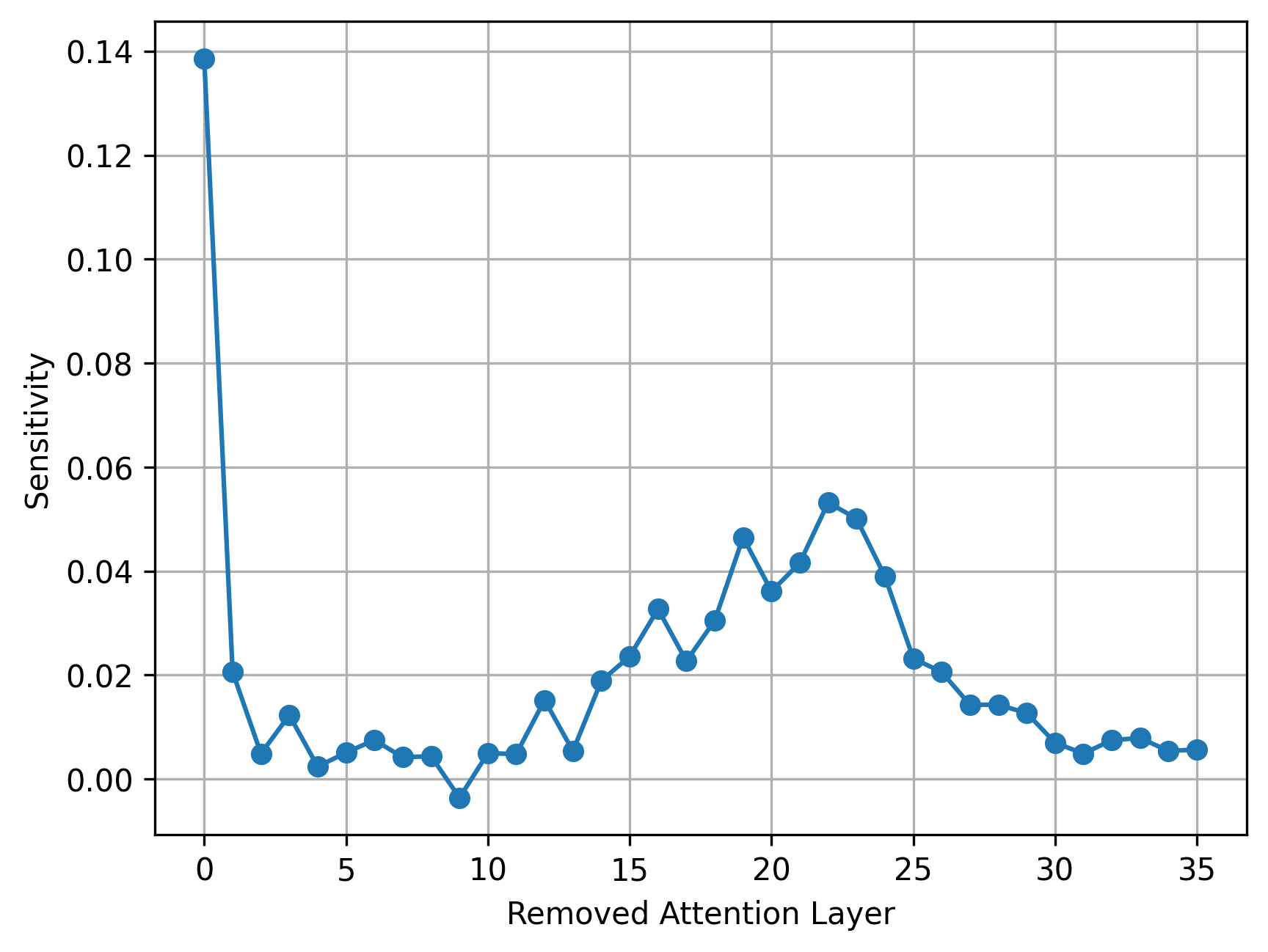
LayerBoost 先在预训练模型上做系统性 sensitivity analysis,衡量移除/替换各层 attention 对基准性能的平均下降(Eq 3),据此将层分为三类并分别应用:保留 softmax attention、替换为 linear sliding window attention、完全移除 attention。架构改动后,引入基于 distillation 的 healing phase,仅用额外 10M 训练 token 恢复模型质量。
实验
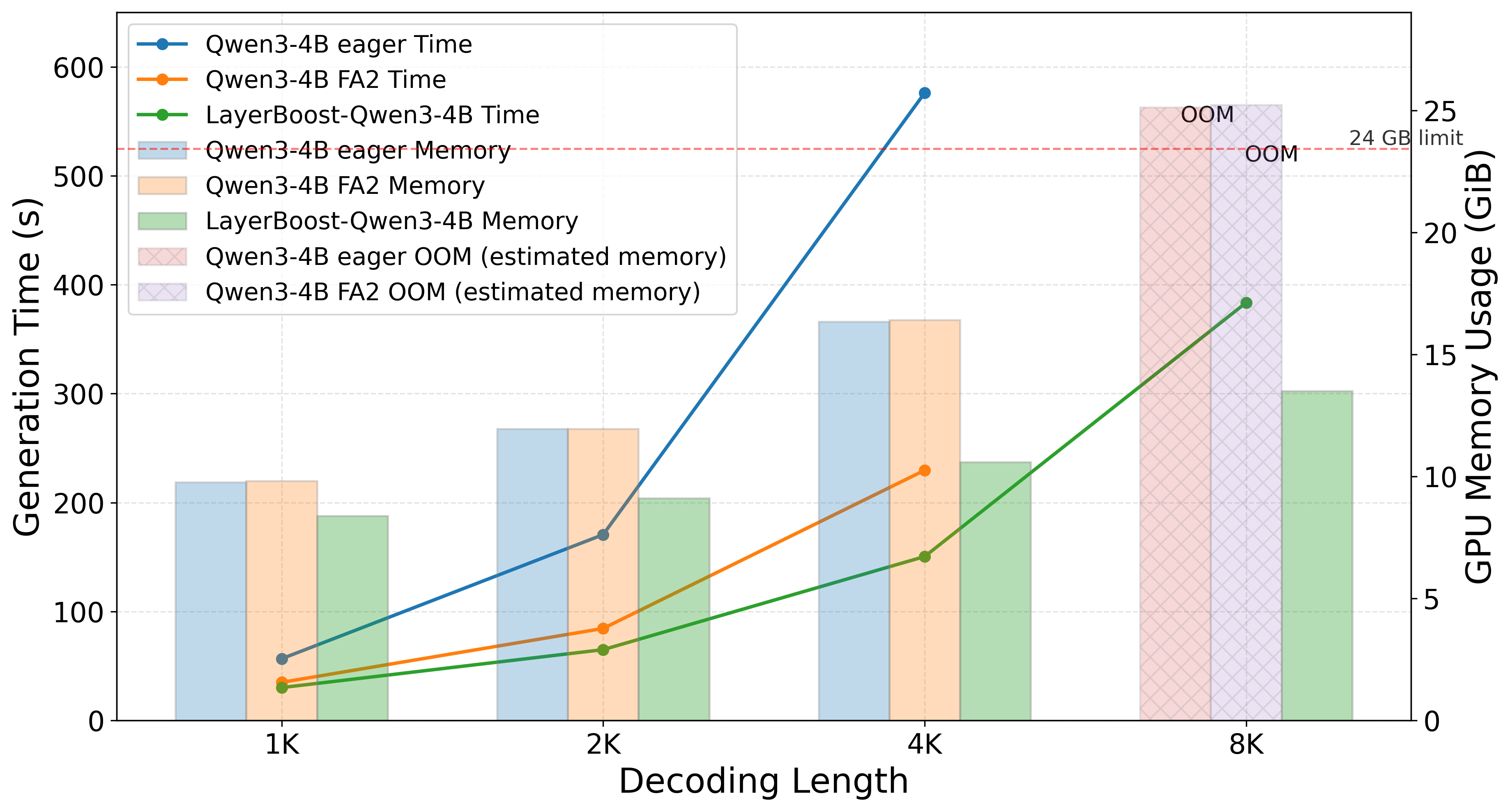
作者在多项基准上对比基础模型及 SOTA attention linearization 方法,测试不同 concurrency(50/100/200)下的吞吐(TPS)与准确率权衡;并在单张 24GB A10 GPU、batch size 16、变化 decoding length 下测量 decoding latency 与 GPU memory。指标包括 benchmark accuracy、throughput、latency、memory footprint。
结果
高并发下吞吐提升最高达 68%,延迟显著降低;在多个 benchmark 上与 base model 持平,部分任务仅轻微下降,且显著优于 SOTA 线性化方法。逐层敏感度分析显示少数层对性能至关重要,其余层可安全简化。
为什么重要
对 LLM serving 基础设施从业者,LayerBoost 提供了一条低成本改造现有预训练模型的路径:无需大规模重训练即可在高并发、显存受限的部署场景下显著降本,适合边缘与多租户推理系统。
与已有工作的关系
延续 linear attention、hybrid attention、sliding window attention 等注意力简化路线,但不同于统一替换的做法;与 knowledge distillation 式的架构修复方法相关;对比对象为当前 SOTA attention linearization 工作。
尚未回答的问题
- sensitivity 指标在更大模型或多模态场景下是否稳定?
- 10M token healing 是否足以覆盖长上下文、代码、推理等复杂任务?
- 三档策略的阈值如何自动化选择,而非经验划分?
- 与 KV cache 压缩、量化等技术能否叠加?
原始摘要(中文翻译)
Transformer 主要依赖 softmax attention,其关于序列长度的二次复杂度仍是高效推理的主要瓶颈。以往关于 linear 或 hybrid attention 的工作通常在所有层上统一替换 softmax attention,往往导致显著的性能下降,或需要大量再训练才能恢复模型质量。本文提出 LayerBoost,一种 layer-aware 的注意力精简方法,根据各个 transformer 层的敏感度选择性地修改注意力机制。它首先在预训练模型上进行系统的敏感度分析,识别对维持性能至关重要的层。在此分析指导下,可应用三种不同策略:在高度敏感的层中保留标准 softmax attention,在中等敏感的层中将其替换为 linear sliding window attention,在敏感度较低的层中完全移除 attention。为在这些架构修改后恢复性能,我们引入了一个基于 distillation 的轻量 healing 阶段,只需额外 10M 训练 token。LayerBoost 降低了推理延迟,在高并发下吞吐最多提升 68%,同时保持具有竞争力的模型质量。它在若干基准上与基础模型持平,在其他基准上仅出现轻微下降,并显著优于最先进的 attention linearization 方法。这些效率收益使我们的方法特别适合高并发服务和硬件受限的部署场景,其中推理成本和显存占用是关键瓶颈。