arXiv: 2604.22577 · PDF
作者: Manyi Zhang, Ji-Fu Li, Zhongao Sun, Xiaohao Liu, Zhenhua Dong, Xianzhi Yu, Haoli Bai, Xiaobo Xia
单位: Huawei Technologies, National University of Singapore, University of Science and Technology of China
主分类: cs.AI · 全部: cs.AI, cs.CL
命中关键词: agent, reasoning, inference, serving, quantization, latency
TL;DR
QuantClaw 是 OpenClaw 的即插即用精度路由插件,按任务复杂度动态分配量化精度,在 GLM-5 上相比 FP8 基线最多省 21.4% 成本、降 15.7% 延迟。
核心观点
- Autonomous agent 系统(如 OpenClaw)因长上下文和多轮推理带来高昂计算与金钱成本。
- 量化对 agent 性能的影响高度任务相关,统一精度并非最优。
- 应把精度视为动态资源:轻量任务用低精度,复杂任务保留高精度。
- 提出 QuantClaw:plug-and-play 的精度路由插件,在不增加用户复杂度的情况下节省成本、加速推理。
方法
作者首先在 OpenClaw 的多样复杂工作流上系统分析量化敏感度,得出精度需求因任务而异的结论。基于此提出 QuantClaw:一个精度路由插件,将 task detector 与 intelligent routing 整合,on-the-fly 判断任务特征,把轻量任务路由到低成本(更低精度)配置,把 demanding workload 路由到更高精度,从而在 agent 系统内实现动态精度分配。
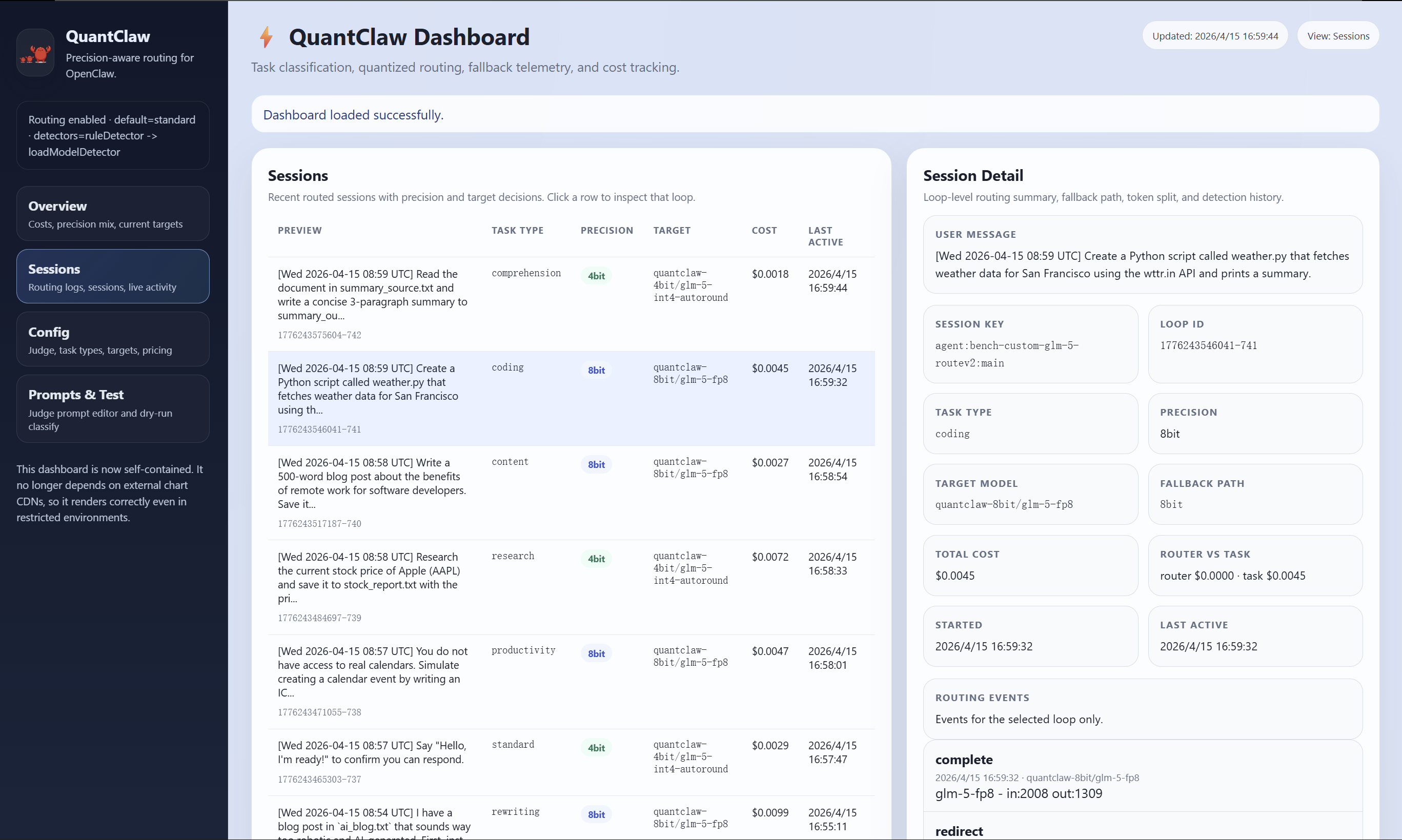
实验
- 载体系统:OpenClaw autonomous agent。
- 模型基线:GLM-5 的 FP8 baseline。
- 覆盖工作流:多种 agent 任务(long-context、multi-turn reasoning 等复杂场景)。
- 评估指标:任务性能、latency、computational / monetary cost。
- 另外对 NVFP4 下量化退化的 scaling 行为进行了分析(随模型参数增大而衰减,呈 power-law)。
结果
- 在一系列 agent 任务上最多 21.4% cost 节省与 15.7% latency 降低(相对 GLM-5 FP8 基线)。
- 任务性能维持或提升,未出现精度换性能的明显退化。
- NVFP4 量化退化随模型规模呈 power-law 递减,大模型更耐量化。
为什么重要
对 agent / LLM infra 实践者,QuantClaw 展示了"精度即资源"的新思路:无需改用户代码,就能在生产 agent 流水线中按任务弹性切换精度,显著降低 serving 成本与延迟,适合长上下文、多轮 agent 场景。
与已有工作的关系
延续 post-training quantization(FP8、NVFP4)与 mixed-precision inference 的研究,将其由静态模型级策略推进为 agent 任务级动态路由;与 OpenClaw 等 autonomous agent 框架、以及 LLM routing / cascading 工作(按难度分配算力)相呼应。
尚未回答的问题
- task detector 的泛化性:面对未见任务类型是否仍能准确判断精度需求?
- 路由错误的代价与回退机制?
- 在非 GLM-5 模型、非 FP8/NVFP4 精度组合下的普适性?
- 多模型 / 多硬件后端下的调度开销与收益边界?
原始摘要(中文翻译)
像 OpenClaw 这样的 autonomous agent 系统,由于长上下文输入与多轮推理,带来了显著的效率挑战。这在真实开发中导致了过高的计算与金钱成本。虽然 quantization 是降低成本与延迟的标准方法,但其在真实场景中对 agent 性能的影响尚不清楚。在本工作中,我们分析了 OpenClaw 上多种复杂工作流下的量化敏感度,并表明精度需求高度依赖于任务。基于这一观察,我们提出 QuantClaw,一个即插即用的精度路由插件,根据任务特征动态分配精度。QuantClaw 将轻量任务路由到低成本配置,同时为 demanding 的工作负载保留更高精度,从而在不增加用户复杂度的前提下节省成本并加速推理。实验表明,我们的 QuantClaw 在维持或提升任务性能的同时,降低了延迟和计算成本。在一系列 agent 任务上,它相对 GLM-5(FP8 基线)实现了最多 21.4% 的成本节省和 15.7% 的延迟降低。这些结果凸显了在 agent 系统中将精度视作动态资源的好处。