arXiv: 2605.30102 · PDF
作者: Corrado Rainone, Davide Belli, Bence Major, Arash Behboodi
单位: Qualcomm AI Research
主分类: cs.MA · 全部: cs.AI, cs.MA
命中关键词: large language model, llm, agent, agentic, multi-agent, inference
TL;DR
本文系统研究了云端大模型与设备端小模型组成的混合多智能体系统(MAS)设计空间,发现最优架构高度依赖任务类型,增加云端算力并不总能提升性能。
Motivation
随着 LLM 越来越多地以"agent"形式部署,用户面临两难困境:云端前沿大模型(如 GPT-4o)能力强但按 token 计费,长 horizon 任务的 API 成本可能急剧膨胀;而设备端小模型(SLM)成本低、私密性好,但能力有显著差距,尤其在上下文长度上受设备 DRAM 硬性约束,KV-cache 容量远不及云端。
现有混合方案通常是"路由"模式——根据请求类型将其分派给大或小模型——但这种方案没有充分发挥多智能体协作的潜力:不同模型可以承担不同角色(规划者 vs 执行者,督导者 vs 操作者),而不仅仅是互为替补。当前工程实践中,将云端与边缘模型结合进 MAS 的做法仍是针对特定领域的 ad hoc 决策,缺乏通用设计原则。作者认为现在是系统研究这一设计空间的时机:SLM 质量近年显著提升,已可在受限域内接近前沿模型,且上下文管理(context reset / summarization)技术可缓解设备端内存瓶颈,使得云端+边缘协作比以前更可行。
核心观点
- 将两种代表性 MAS 架构(PEVA 和 EVA)改造为支持混合云-边推理,提供统一框架评估准确率、货币成本与边缘能耗之间的 Pareto 权衡。
- 证明不存在"免费午餐"架构:PEVA(规划为主)在 UI 任务(AppWorld)上表现最优,EVA(建议为主)在 Deep Search(FanOutQA)上更具竞争力。
- 云端算力使用越多并不总能带来更好性能——在某些任务上增加云端 Supervisor 干预反而有害。
- 确定了影响混合协作效果的关键机制:督导频率、重启策略、以及摘要机制。
- 展示混合 MAS 通过 context reset 与 summarization 有效控制边缘 KV-cache 增长,提升对内存受限设备的适配性(Table 3)。
方法
论文适配并研究了两种混合 MAS 架构:
PEVA(Plan-Execute-Verify-Replan):Supervisor(云端 LLM)先为查询生成初始计划 $p_0$,然后 Executor(边缘 SLM)在 ReAct 循环中执行;每隔 $T_v$ 步,Supervisor 重新验证并按需 replan。云端模型负责宏观规划与周期性纠偏,边缘模型负责与环境(工具调用、界面操作等)的具体交互。
EVA(Execute-Verify-Advice):无初始规划阶段,Supervisor 周期性地向 Executor 提供 advice(而非完整 replan),Executor 持续执行 ReAct 步骤。云端只在关键节点提供战略建议,执行控制权更多留在边缘。
两种架构均支持以下设计维度的实验:(a) 云端 vs 边缘模型在 Supervisor / Executor 角色上的分配;(b) 督导频率 $T_v$(即多久云端介入一次);(c) 是否引入 context summarization 来管理 KV-cache。
云端模型使用 GPT-4o;边缘模型使用 Qwen2 系列(4B、8B、14B、32B),对 32B 变体使用 KV-cache 和权重量化以适配设备 DRAM。
图 2 描绘了两种架构在不同基准下的整体系统结构,左侧 PEVA 包含显式初始规划步骤,右侧 EVA 以建议驱动代替 replan:

实验
数据集:Deep Search 场景采用 HotpotQA(多跳问答,较易)和 FanOutQA(更宽泛的 fan-out 结构,较难);UI 自动化场景采用 AppWorld(交互式基准,要求 agent 操作模拟 App)。最大步数(max_turns)在 AppWorld 实验中为 12。
Baseline:cloud-only(GPT-4o 独立运行)与 edge-only(Qwen2 各档单独运行)均作为对照组。混合配置以不同督导频率区间 $T_v \in [1, 12]$(AppWorld)或 $[1, 8]$(FanOutQA)扫描。
指标:任务成功率(Task Success)、云端 API 货币成本(Cloud Cost)、边缘 GPU 能耗(mAh/mWh)。三者共同构成 Pareto 前沿。
硬件:边缘端在消费级 GPU 上推理 Qwen2 系列,32B 模型启用量化后可置入受限 DRAM。
结果
下图展示了各混合配置在 HotpotQA 与 FanOutQA 上的 Pareto 前沿,每个点对应一种特定的云/边分配与督导频率组合。可以看出,PEVA 在 AppWorld(UI 任务)方向占优,而 EVA 在 FanOutQA(Deep Search)上形成更有竞争力的曲线;没有一种配置能在所有基准上同时最优(Figure 2):
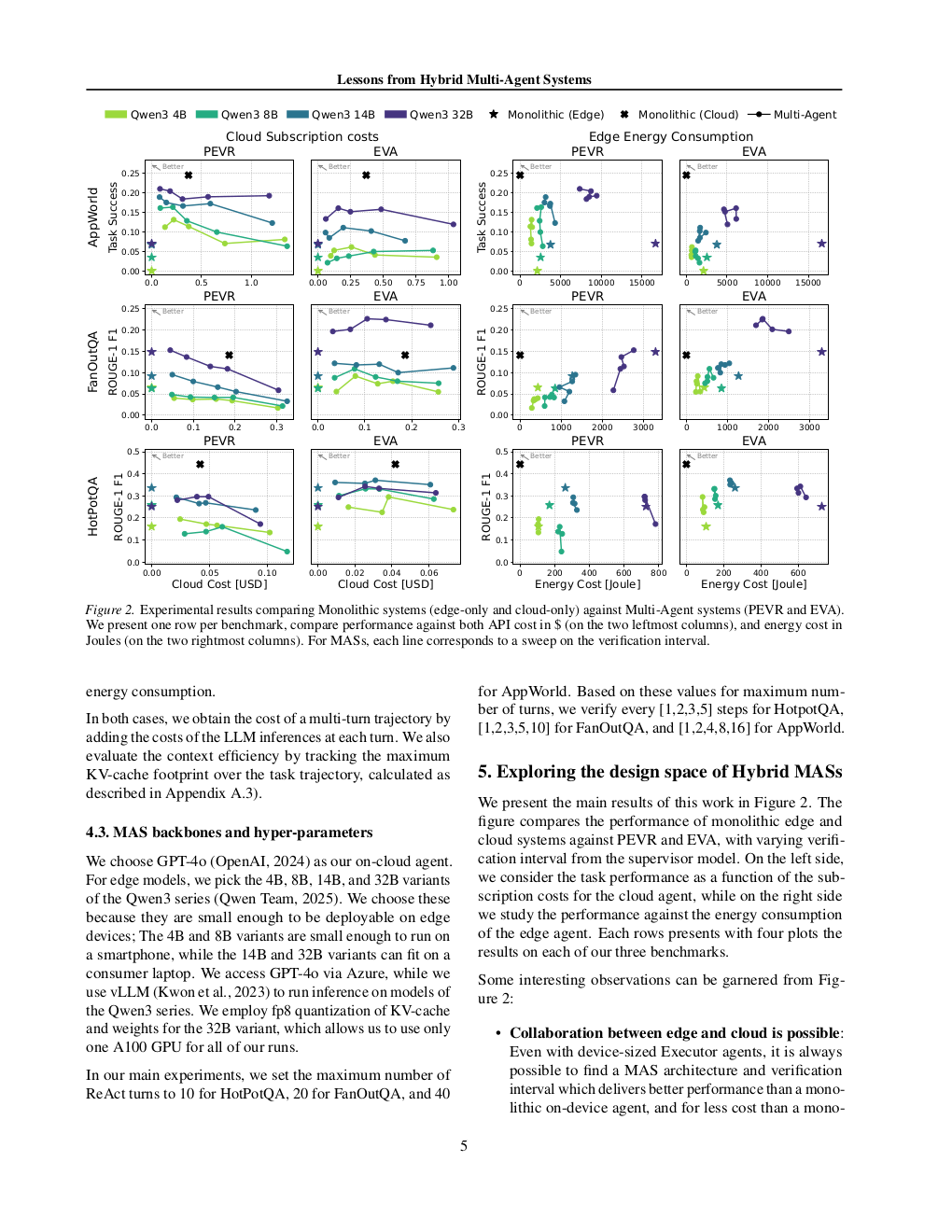
下图进一步以督导频率为横轴,对比了 PEVA 和 EVA 的准确率变化以及干预类型分布(True Positive / False Positive / False Negative)。PEVA 在 AppWorld 上随督导频率提升持续受益,但在 FanOutQA 上曲线趋于平坦甚至下降;EVA 在 FanOutQA 上的 True Positive 率更高,但 PEVA 能抑制更多 False Positive(Figure 3):
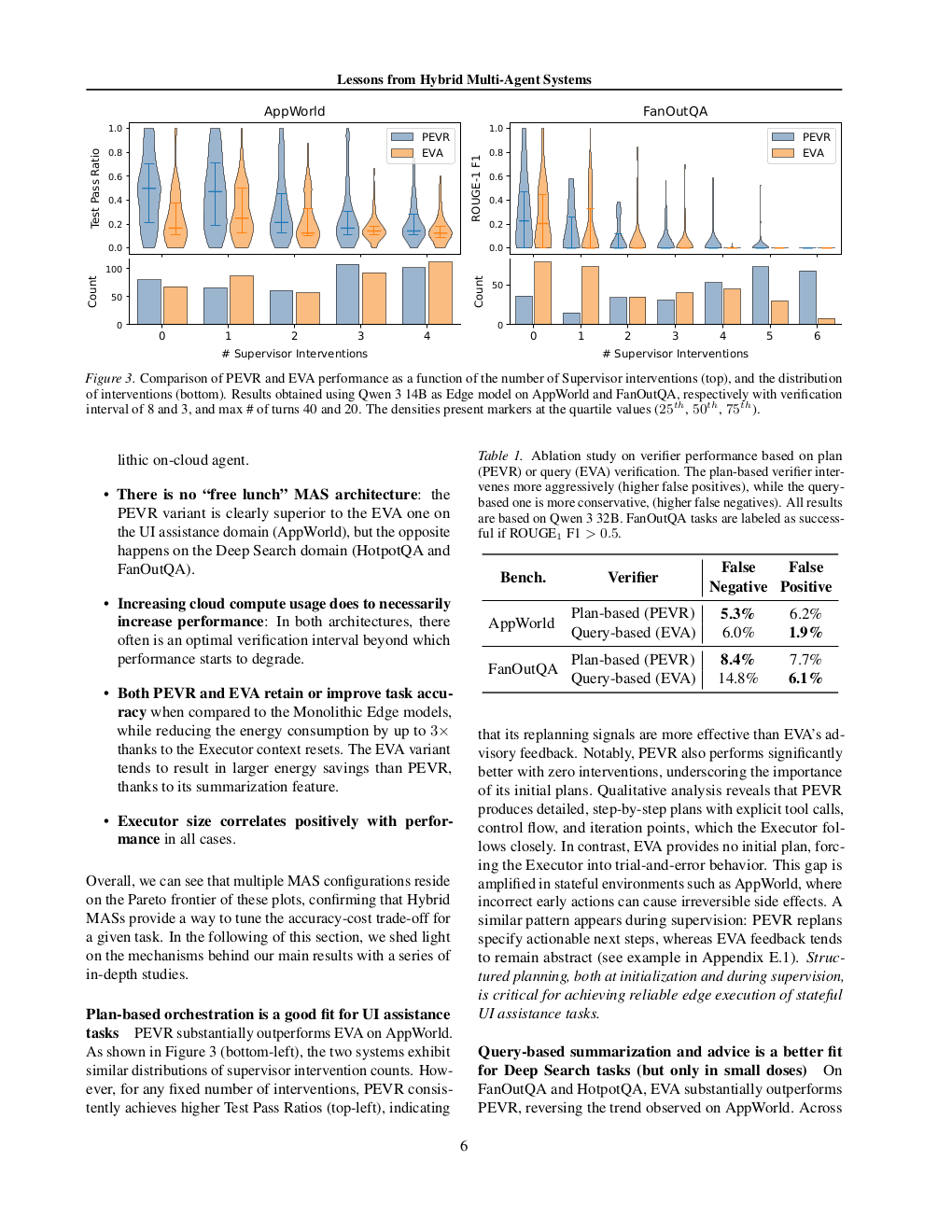
Table 1 的 ablation 研究(Figure 3 同页)揭示了督导质量对性能的非单调影响:以 oracle 质量(True 信号)干预时性能显著提升,而 False Positive(误认任务失败)会将性能拉低至低于无督导基线(Table 1):
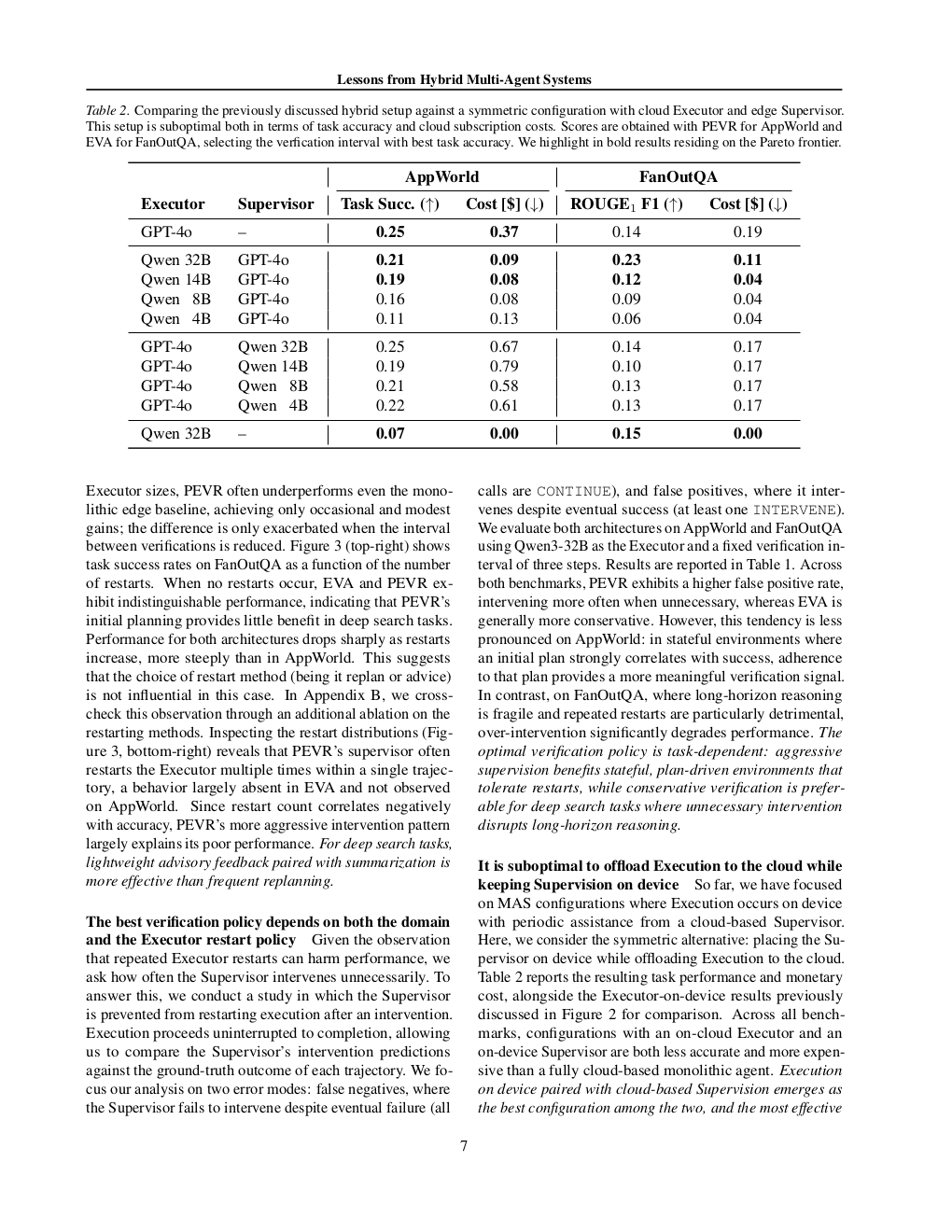
Table 2 对比了将 Executor 置于云端、Supervisor 置于边缘的"反向"配置与标准混合配置,结果表明这种反向分配在任务成功率和成本上均处于劣势——将执行层卸载到云端并不经济(Table 2):

Table 3 展示了随 max_turns 增加,纯边缘架构的 KV-cache 急剧膨胀,而 PEVA 的 context reset 与 summarization 机制将 KV-cache 增长控制在较低水平,支持更长 horizon 任务在内存受限设备上的可行性(Table 3):

结论
最值得带走的 takeaway 是:混合 MAS 的最优架构由任务结构决定,而非由云端模型的能力档位决定——规划导向架构(PEVA)在有明确步骤结构的 UI 任务中最优,而建议导向架构(EVA)在需要灵活信息检索的 Deep Search 中更具优势,且盲目增加云端督导频率在某些任务上会引入 False Positive 干扰,损害整体性能(Table 1)。
边界:所有结论均在英文 benchmarks(HotpotQA、FanOutQA、AppWorld)、Qwen2 系列 SLM、以及 GPT-4o 作为云端模型的特定组合下成立;不同 SLM 系列或其他云端模型是否有相同规律尚未验证。论文没有测试三个以上的 agent 节点,也没有系统研究 SLM 经 fine-tune 后对架构选择的影响。能耗数字来自特定硬件,实际部署在异构边缘设备上的结果可能不同。
是否新瓶装旧酒
论文自述:Related Work 列出了最相近的工作,包括 MAI-UI(Zhou et al., 2025,引入了原生云-边混合 GUI agent)、路由类框架(Ding et al., 2024; Stripelis et al., 2024 等)以及针对单一任务 co-design 的系统(Bogavelli et al., 2025; Zeng et al., 2025 等)。作者将自己的 delta 定位为:首次在统一框架下跨多任务、多维度(成本/准确率/能耗)系统评估 cloud-edge MAS 架构选择,而非针对单一任务做特定系统设计。
独立判断:将云端与边缘模型结合用于 agent 的思路并不新颖,路由/级联方案(如 LLM cascade、FrugalGPT)已有先例。但将 MAS 的 Supervisor/Executor 角色分配与云-边混合对应起来,并系统测量 Pareto 权衡,的确是这类 benchmark-level 比较研究中相对少见的视角。整体来看,这更像一篇工程性的实证分析论文,而非提出新算法——贡献在于"系统研究了设计空间"而非"提出新机制",因此不算旧瓶装新酒,但创新厚度有限。
尚未回答的问题
- 所有 ablation 均在 GPT-4o + Qwen2 组合下完成,换用其他 SLM 系列(如 Llama、Mistral)或其他云端模型(如 Claude、Gemini)时,任务依赖性结论是否仍然成立?
- 论文缺少对 SLM 经任务特定 fine-tune 后的对比:微调 SLM 后,混合架构是否仍比 SLM 独立运行有优势?
- 督导频率 $T_v$ 目前是人工设定的超参数,缺少自适应选择 $T_v$ 的方法;能否训练一个轻量路由器在运行时决策何时调用云端 Supervisor?
- 能耗测量仅限于特定 GPU 硬件,在真实移动端(NPU、手机 SoC)上的结果和结论是否一致?
- 超过两个 agent 节点(多云端 + 多边缘)的配置完全未被研究。
原始摘要(中文翻译)
智能体 AI 推理的设计空间横跨两个极端:一端是前沿大语言模型(LLM),通常托管于云端,能在广泛任务上提供强劲性能,但成本显著高昂;另一端是更具成本效益的小语言模型(SLM),适合在设备端推理。将设备端模型与云端模型结合的混合多智能体系统(MAS)提供了一种有前景的折中方案,但同时也引入了一个复杂且尚未被充分理解的设计空间——任务准确率、货币成本与边缘能耗在其中紧密耦合;由于缺乏通用设计原则,混合组件虽然并非最主流的选择,但通常是通过针对特定领域量身定制的 ad hoc 决策引入的。在本工作中,我们对这一设计空间进行了更系统的研究。我们将两种具有代表性的 MAS 架构改造为支持混合推理,并研究各个设计选择如何在功耗、成本与性能的 Pareto 前沿上移动系统的工作点。我们的发现呈现出混合 MAS 设计的细腻图景:尽管 SLM 确实能从 LLM 的协助中获益,但最优架构高度依赖具体任务,更多前沿级别的算力并不总能转化为更好的性能。