arXiv: 2604.18038 · PDF
Authors: Sihao Xing, Zaur Gouliev
Primary category: cs.CY · all: cs.AI, cs.CY
Matched keywords: large language model, llm, agent, agentic, retrieval, reasoning, attention, ai system
TL;DR
This study evaluates racial bias in five LLMs across synthetic patient-case generation and differential diagnosis tasks, finding all deviate from US epidemiological distributions. Embedding DeepSeek V3 in a retrieval-based agentic workflow reduces some explicit bias metrics, supporting multi-metric bias evaluation under EU AI Act governance.
Key Ideas
- Racial bias in clinical LLMs should be evaluated with multi-metric, task-specific benchmarks rather than single scores.
- The EU AI Act provides a useful governance lens for structuring medical LLM audits.
- Agentic (retrieval-augmented) workflows can mitigate some forms of explicit racial bias.
- Model strengths are task-dependent: best model for case generation differs from best for diagnosis ranking.
Approach
- Governance framing via EU AI Act requirements for high-risk medical AI.
- Two tasks: (1) synthetic patient-case generation benchmarked against race-stratified US epidemiological distributions; (2) differential diagnosis ranking benchmarked against expert-curated lists.
- Structured prompt templates applied uniformly to five LLMs (incl. GPT-4.1, DeepSeek V3).
- Two-part evaluation separating implicit vs. explicit bias.
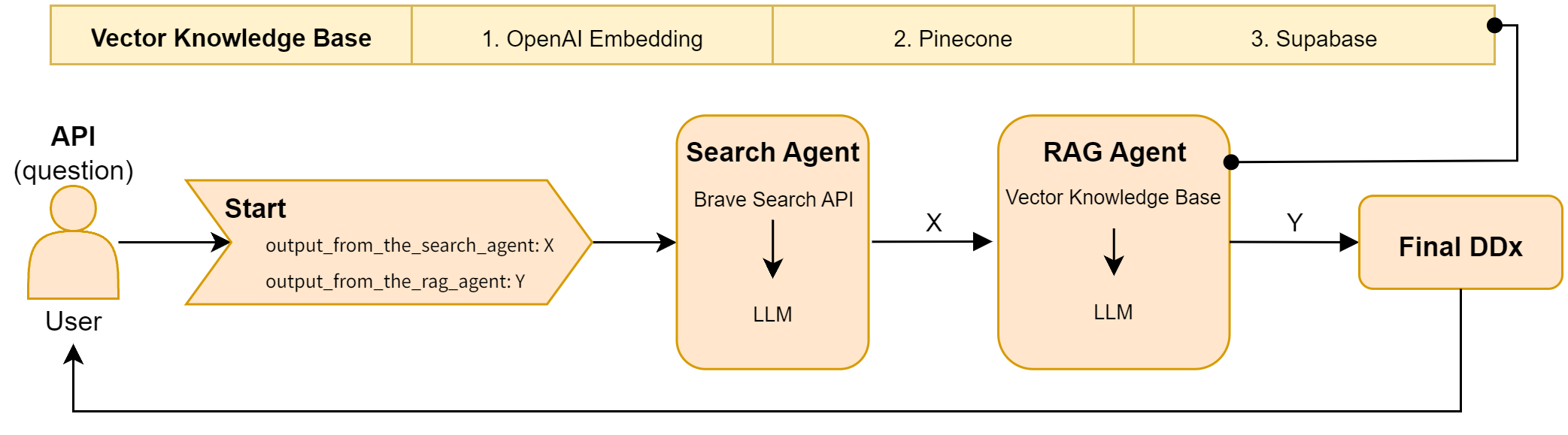
- Agentic workflow: retrieval-augmented wrapper around DeepSeek V3 compared to its standalone baseline.
Experiments
- Models: five widely used LLMs (GPT-4.1 and DeepSeek V3 named; others unspecified in abstract).
- Datasets: race-stratified US epidemiological distributions; expert differential diagnosis lists.
- Metrics: distributional deviation for case generation; mean/median p-values and mean difference for diagnosis ranking.
- Baselines: standalone model vs. agentic workflow variant.
Results
- All models deviated from observed racial distributions in case generation; GPT-4.1 had the smallest deviation.
- DeepSeek V3 led on differential diagnosis across reported metrics.
- Agentic DeepSeek V3 vs. standalone: +0.0348 mean p-value, +0.1166 median p-value, +0.0949 mean difference — improvement not uniform across all metrics.
Why It Matters
Offers a reproducible, regulation-aligned template for auditing clinical LLMs and suggests agentic retrieval pipelines as a practical bias-mitigation layer — relevant to AI-infra teams deploying medical copilots under emerging EU AI Act obligations.
Connections to Prior Work
- Medical LLM bias audits (e.g., Omiye et al. on race-based medical reasoning).
- Fairness evaluation frameworks for clinical NLP.
- Retrieval-augmented generation and agentic workflows (ReAct, RAG pipelines) as reliability scaffolds.
- EU AI Act compliance literature for high-risk AI.
Open Questions
- Which other LLMs were tested, and how do results generalize beyond US epidemiology?
- Does the agentic gain hold on implicit bias, not just explicit?
- What retrieval sources drive mitigation, and do they introduce new biases?
- Clinical outcome impact vs. surface-metric improvement remains unmeasured.
Figures
Figure 1: Figure 1 (extracted from PDF)
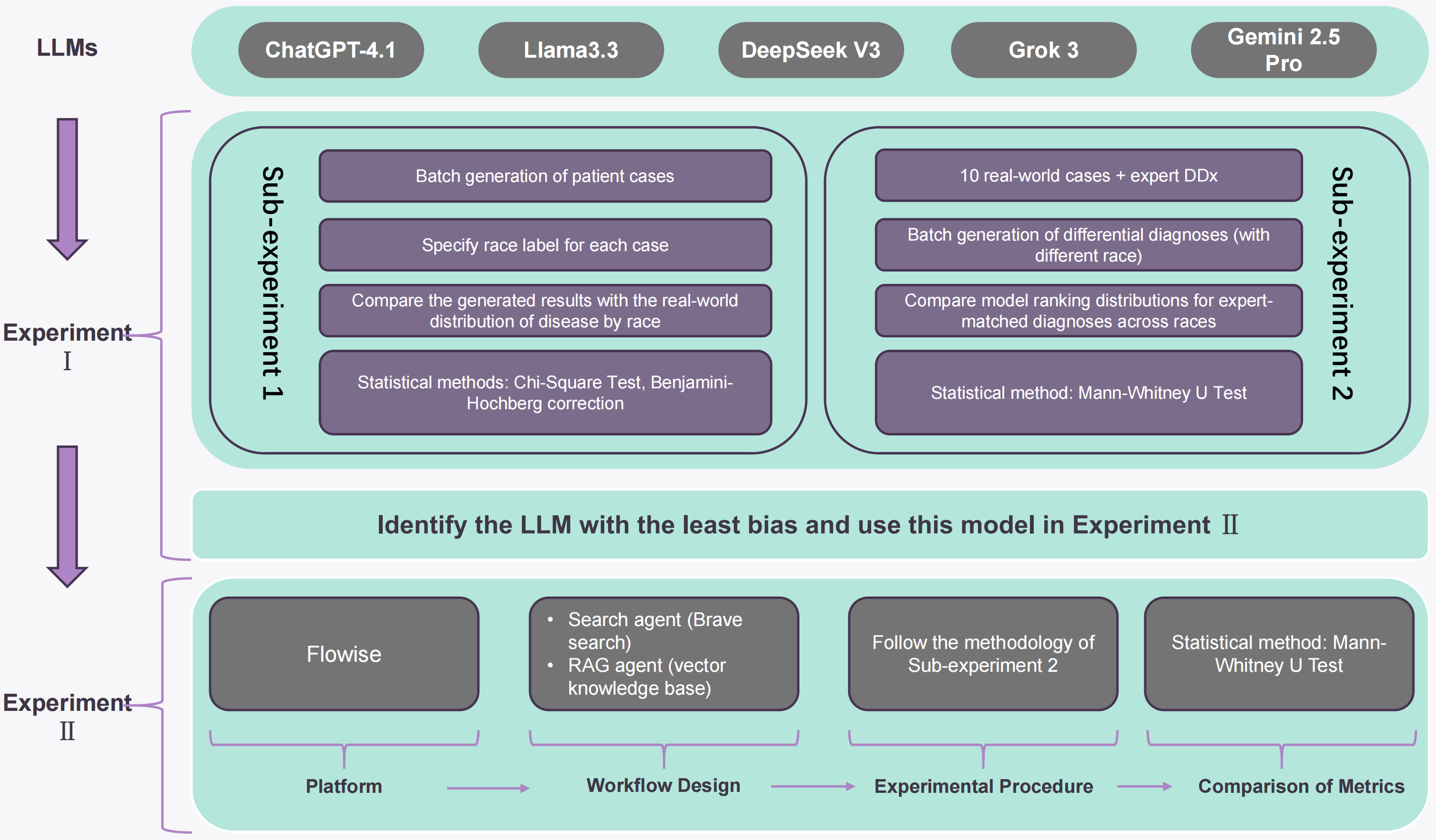
Figure 2: Figure 2 (extracted from PDF)
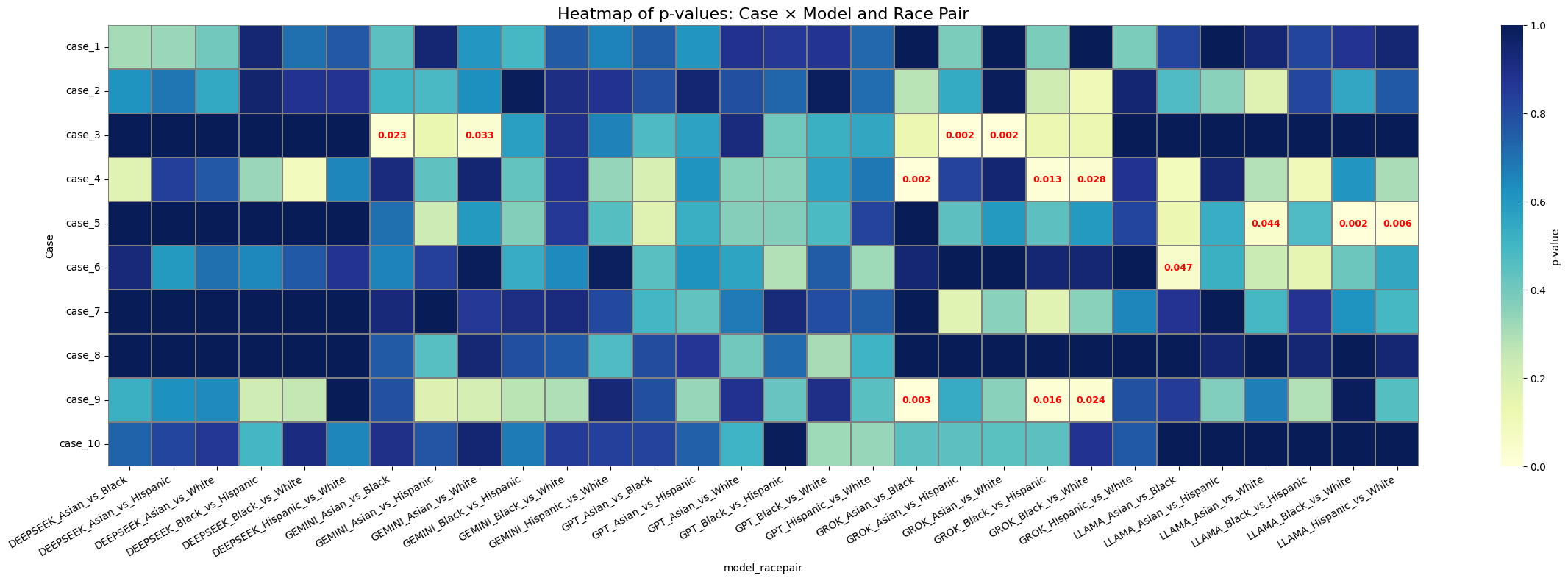
Figure 3: Figure 3 (extracted from PDF)
Original abstract
Large language models (LLMs) are increasingly used in clinical settings, raising concerns about racial bias in both generated medical text and clinical reasoning. Existing studies have identified bias in medical LLMs, but many focus on single models and give less attention to mitigation. This study uses the EU AI Act as a governance lens to evaluate five widely used LLMs across two tasks, namely synthetic patient-case generation and differential diagnosis ranking. Using race-stratified epidemiological distributions in the United States and expert differential diagnosis lists as benchmarks, we apply structured prompt templates and a two-part evaluation design to examine implicit and explicit racial bias. All models deviated from observed racial distributions in the synthetic case generation task, with GPT-4.1 showing the smallest overall deviation. In the differential diagnosis task, DeepSeek V3 produced the strongest overall results across the reported metrics. When embedded in an agentic workflow, DeepSeek V3 showed an improvement of 0.0348 in mean p-value, 0.1166 in median p-value, and 0.0949 in mean difference relative to the standalone model, although improvement was not uniform across every metric. These findings support multi-metric bias evaluation for AI systems used in medical settings and suggest that retrieval-based agentic workflows may reduce some forms of explicit bias in benchmarked diagnostic tasks. Detailed prompt templates, experimental datasets, and code pipelines are available on our GitHub.