arXiv: 2604.18038 · PDF
作者: Sihao Xing, Zaur Gouliev
主分类: cs.CY · 全部: cs.AI, cs.CY
命中关键词: large language model, llm, agent, agentic, retrieval, reasoning, attention, ai system
TL;DR
以 EU AI Act 为治理视角,评估 5 个主流 LLM 在合成病例生成与鉴别诊断中的种族偏见,发现 retrieval-based agentic workflow 可缓解 DeepSeek V3 的显性偏见。
核心观点
- 医学 LLM 普遍偏离美国种族流行病学分布,存在隐性与显性种族偏见。
- 单一指标不足以刻画偏见,主张多指标联合评估。
- 将 LLM 嵌入 retrieval-based agentic workflow 可在部分指标上降低显性偏见。
- 以 EU AI Act 为治理框架为医学 AI 偏见评估提供合规对齐参照。
方法
- 选取 5 个常用 LLM,覆盖两类任务:synthetic patient-case generation 与 differential diagnosis ranking。
- 基准:美国种族分层流行病学分布 + 专家鉴别诊断列表。
- 使用 structured prompt templates,采取两部分评估设计,分别探测隐性与显性种族偏见。
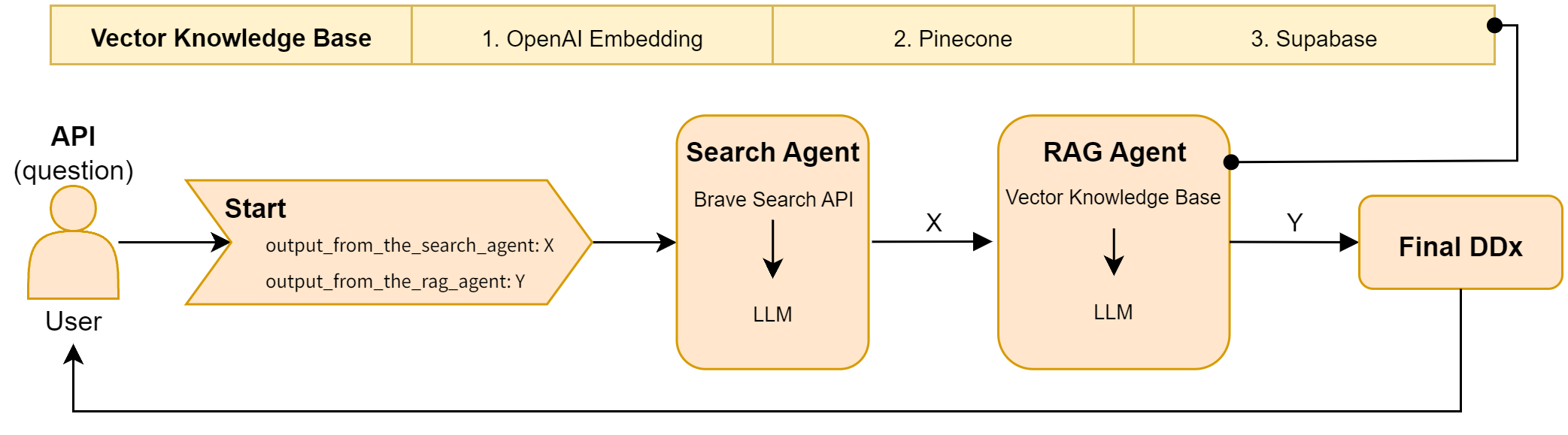
- 对 DeepSeek V3 额外构建 agentic workflow(含检索组件),对比 standalone 版本的指标变化。
实验
- 数据集:race-stratified 美国流行病学分布数据;专家编制的鉴别诊断列表。
- 模型:5 个主流 LLM,其中报告了 GPT-4.1 与 DeepSeek V3 的具体数值。
- 指标:合成生成任务看与真实分布的偏离;诊断排序任务用 p-value(mean/median)及 mean difference 等。
结果
- 合成病例:所有模型均偏离真实种族分布,GPT-4.1 整体偏离最小。
- 鉴别诊断:DeepSeek V3 综合表现最好。
- Agentic workflow 对 DeepSeek V3:mean p-value +0.0348,median p-value +0.1166,mean difference +0.0949,但并非所有指标都改善。
为什么重要
- 为临床 LLM 部署提供可操作的偏见评估范式,兼顾 EU AI Act 合规维度。
- 说明 agentic + retrieval 架构不仅能提升准确率,还能作为 bias mitigation 手段,对医疗 AI 基础设施选型有指导意义。
与已有工作的关系
- 延续 medical LLM bias 评测线(如 Omiye et al. 对 GPT 系列的偏见研究)。
- 借用 agentic workflow / retrieval-augmented generation 思路,把 mitigation 从 fine-tuning 扩展到推理期。
- 以 EU AI Act 为治理锚点,呼应 responsible AI、AI governance 方向的工作。
尚未回答的问题
- 改善幅度较小且不均衡,在真实临床决策中是否具备统计与临床显著性?
- 方法能否推广到性别、年龄、社经地位等其他受保护属性?
- 未比较不同检索语料/检索策略对 bias 的差异化影响。
- 未进入真实 EHR 与前瞻临床评估,外部效度待验证。
- 对隐性偏见(模型内部表征层面)是否真正缓解仍不清楚。
论文图表
图 1: Figure 1 (extracted from PDF)
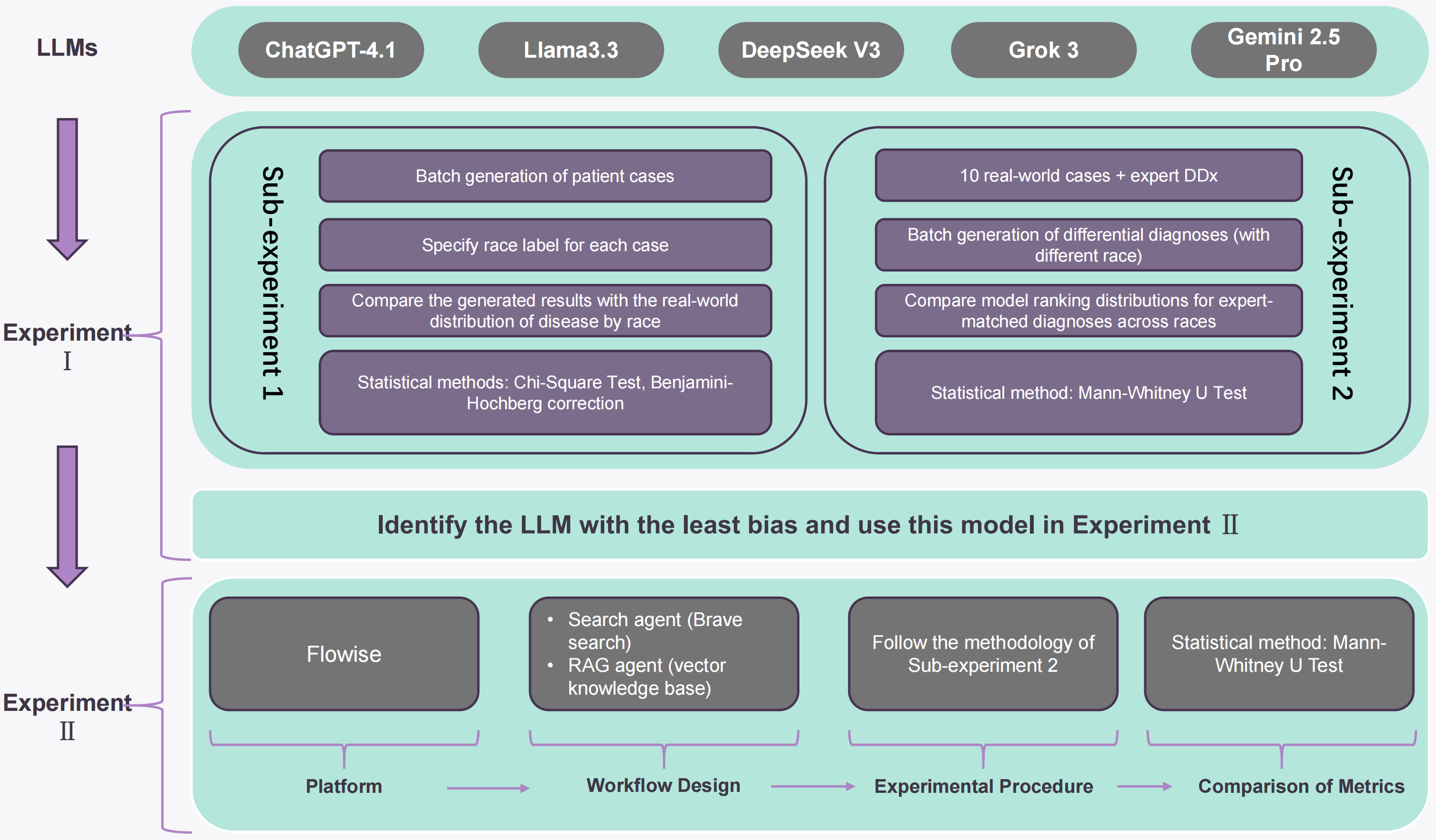
图 2: Figure 2 (extracted from PDF)
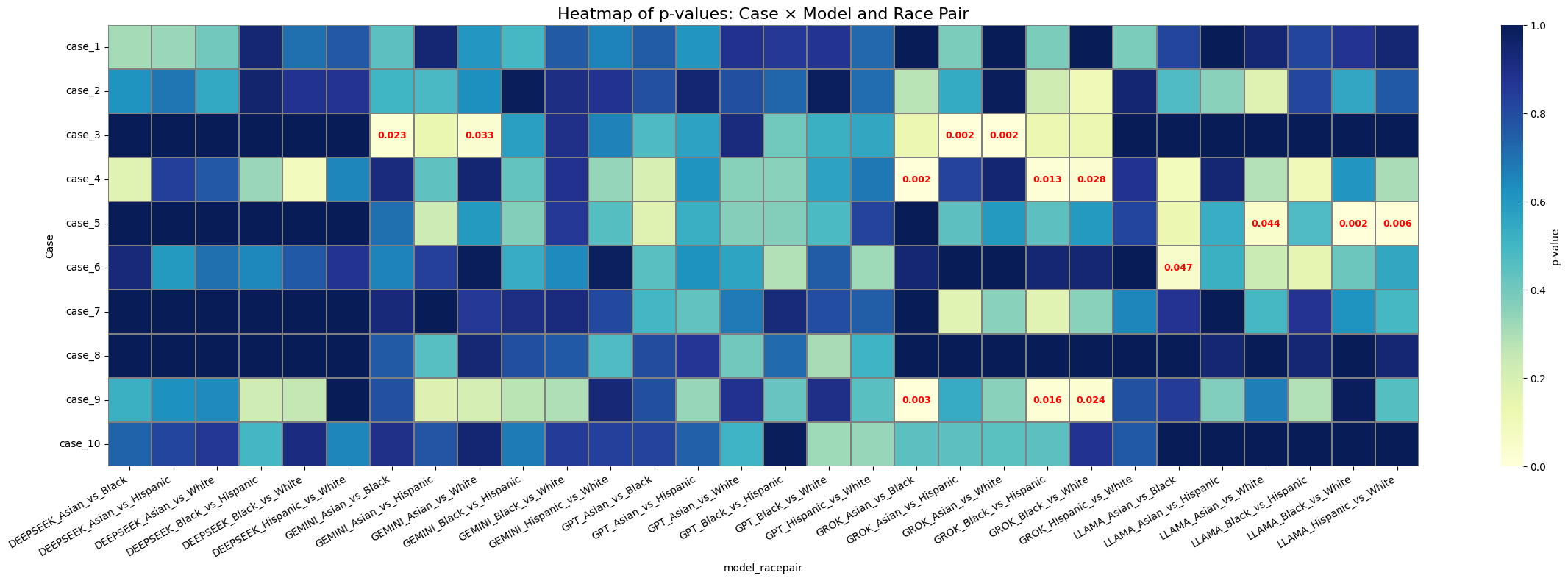
图 3: Figure 3 (extracted from PDF)
原始摘要
Large language models (LLMs) are increasingly used in clinical settings, raising concerns about racial bias in both generated medical text and clinical reasoning. Existing studies have identified bias in medical LLMs, but many focus on single models and give less attention to mitigation. This study uses the EU AI Act as a governance lens to evaluate five widely used LLMs across two tasks, namely synthetic patient-case generation and differential diagnosis ranking. Using race-stratified epidemiological distributions in the United States and expert differential diagnosis lists as benchmarks, we apply structured prompt templates and a two-part evaluation design to examine implicit and explicit racial bias. All models deviated from observed racial distributions in the synthetic case generation task, with GPT-4.1 showing the smallest overall deviation. In the differential diagnosis task, DeepSeek V3 produced the strongest overall results across the reported metrics. When embedded in an agentic workflow, DeepSeek V3 showed an improvement of 0.0348 in mean p-value, 0.1166 in median p-value, and 0.0949 in mean difference relative to the standalone model, although improvement was not uniform across every metric. These findings support multi-metric bias evaluation for AI systems used in medical settings and suggest that retrieval-based agentic workflows may reduce some forms of explicit bias in benchmarked diagnostic tasks. Detailed prompt templates, experimental datasets, and code pipelines are available on our GitHub.