arXiv: 2604.18509 · PDF
Authors: Xingchen Xiao, Heyan Huang, Runheng Liu, Jincheng Xie
Primary category: cs.CL · all: cs.CL
Matched keywords: large language model, llm, agent, multi-agent, retrieval, rag, reasoning, inference
TL;DR
MASS-RAG 提出一种多智能体协作的检索增强生成框架,将证据处理拆分为摘要、抽取、推理三类角色化 agent,再由合成阶段整合输出,提升噪声/异构上下文下的回答质量。
Key Ideas
- 单一生成过程难以调和噪声、残缺、异构的检索证据。
- 将 RAG 解耦为角色化多 agent:summarization、extraction、reasoning。
- 专设 synthesis 阶段融合多视角中间证据再生成最终答案。
- 多中间证据视图利于互补信息对比与整合。
Approach
- 架构:检索 → 并行运行三类专职 agent(证据摘要 / 证据抽取 / 推理)→ 合成 agent 聚合中间输出 → 生成答案。
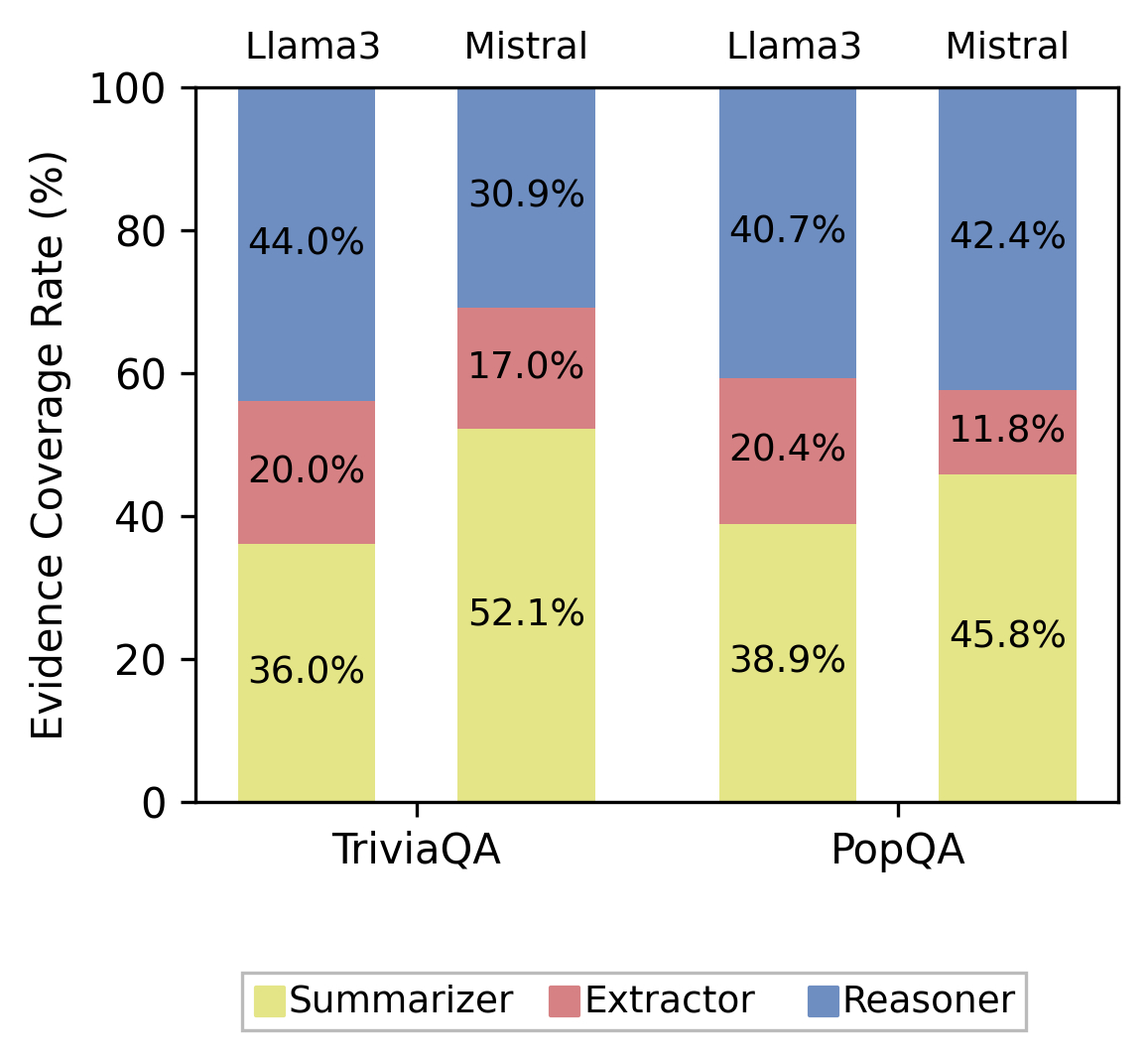
- 每个 agent 针对同一批检索文档产出不同粒度的中间表示,暴露多条证据路径。
- 合成阶段作为仲裁器对互补/冲突证据进行比较与整合。
- 摘要未说明具体 prompt 模板、agent 间通信协议或后端模型。
Experiments
- 四个 RAG benchmark(具体名未披露)。
- 对比强 RAG baseline(未具名)。
- 评估重点:证据分散在多段检索上下文时的表现。
- 摘要未给出数据集规模、检索器设置、评测指标等细节。
Results
- 声称在四个 benchmark 上"consistently"优于强 baseline。
- 在证据跨上下文分散的场景优势更明显。
- 摘要未提供具体数值增益,无法独立核实提升幅度。
Why It Matters
- 为嘈杂或长尾检索结果提供可组合的 agentic RAG 模式。
- 为实务派在 RAG pipeline 里显式引入角色分工、证据融合层提供模板。
- 对构建高可靠知识问答、企业 RAG 系统的工程师有借鉴价值。
Connections to Prior Work
- Self-RAG、Chain-of-Note:显式证据处理/批注思路。
- Multi-agent LLM 协作(AutoGen、MetaGPT、Debate):角色化 agent 协同。
- CRAG、RA-DIT 等鲁棒 RAG 方法:处理噪声/低质量检索。
- Map-Reduce / hierarchical summarization for long context。
Open Questions
- 多 agent 带来的推理成本与延迟如何?是否值得单次调用的 N 倍 token?
- 各 agent 是否共享同一底座 LLM,是否需专门微调?
- 合成阶段如何处理 agent 间冲突证据?是否有显式投票或置信度?
- 在对抗性或高度冗余检索下鲁棒性如何?
- 与更强的单模型长上下文推理(如 Gemini / Claude 长窗)相比是否仍有优势?
Figures
Figure 1: Figure 1 (extracted from PDF)
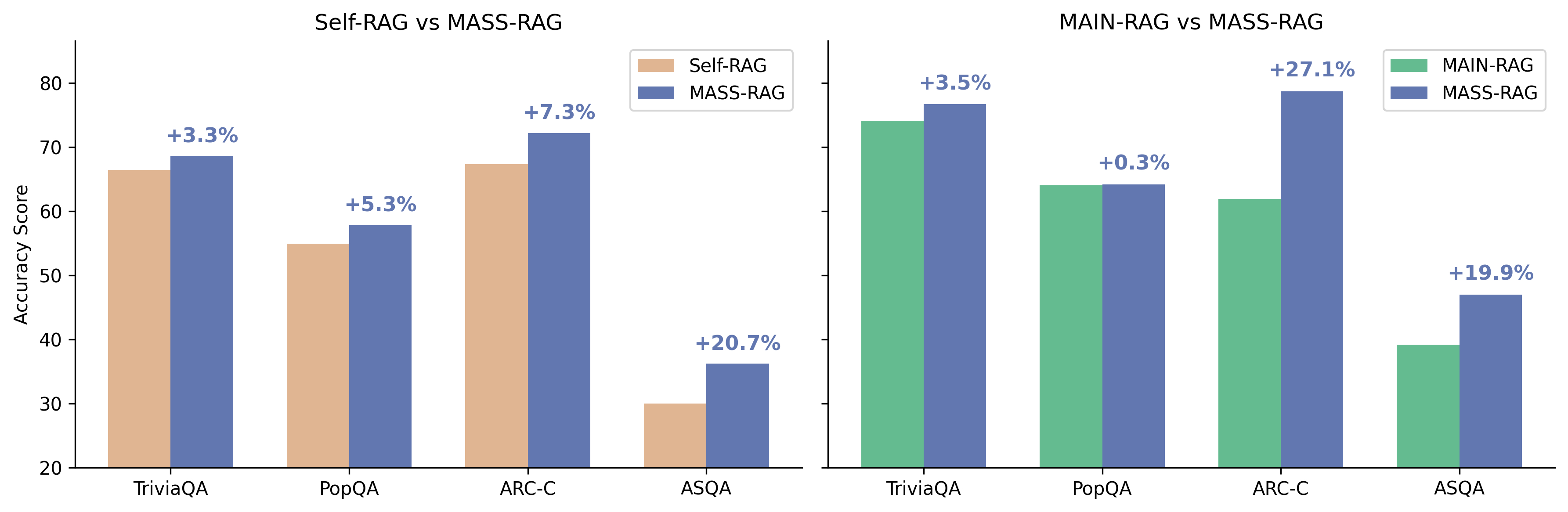
Figure 2: Figure 2 (extracted from PDF)
Original abstract
Large language models (LLMs) are widely used in retrieval-augmented generation (RAG) to incorporate external knowledge at inference time. However, when retrieved contexts are noisy, incomplete, or heterogeneous, a single generation process often struggles to reconcile evidence effectively. We propose \textbf{MASS-RAG}, a multi-agent synthesis approach to retrieval-augmented generation that structures evidence processing into multiple role-specialized agents. MASS-RAG applies distinct agents for evidence summarization, evidence extraction, and reasoning over retrieved documents, and combines their outputs through a dedicated synthesis stage to produce the final answer. This design exposes multiple intermediate evidence views, allowing the model to compare and integrate complementary information before answer generation. Experiments on four benchmarks show that MASS-RAG consistently improves performance over strong RAG baselines, particularly in settings where relevant evidence is distributed across retrieved contexts.