arXiv: 2604.18509 · PDF
作者: Xingchen Xiao, Heyan Huang, Runheng Liu, Jincheng Xie
主分类: cs.CL · 全部: cs.CL
命中关键词: large language model, llm, agent, multi-agent, retrieval, rag, reasoning, inference
TL;DR
MASS-RAG 用多 agent 分工(摘要、抽取、推理)处理检索证据,再经合成阶段产出答案,在证据分散场景下稳定优于单次生成的 RAG baseline。
核心观点
- 单次生成在噪声、残缺或异质检索上下文下难以有效整合证据。
- 将证据处理拆分为角色专门化的多个 agent,暴露多视角中间证据表示。
- 通过专门的 synthesis 阶段汇合不同视角,提升跨文档证据整合能力。
方法
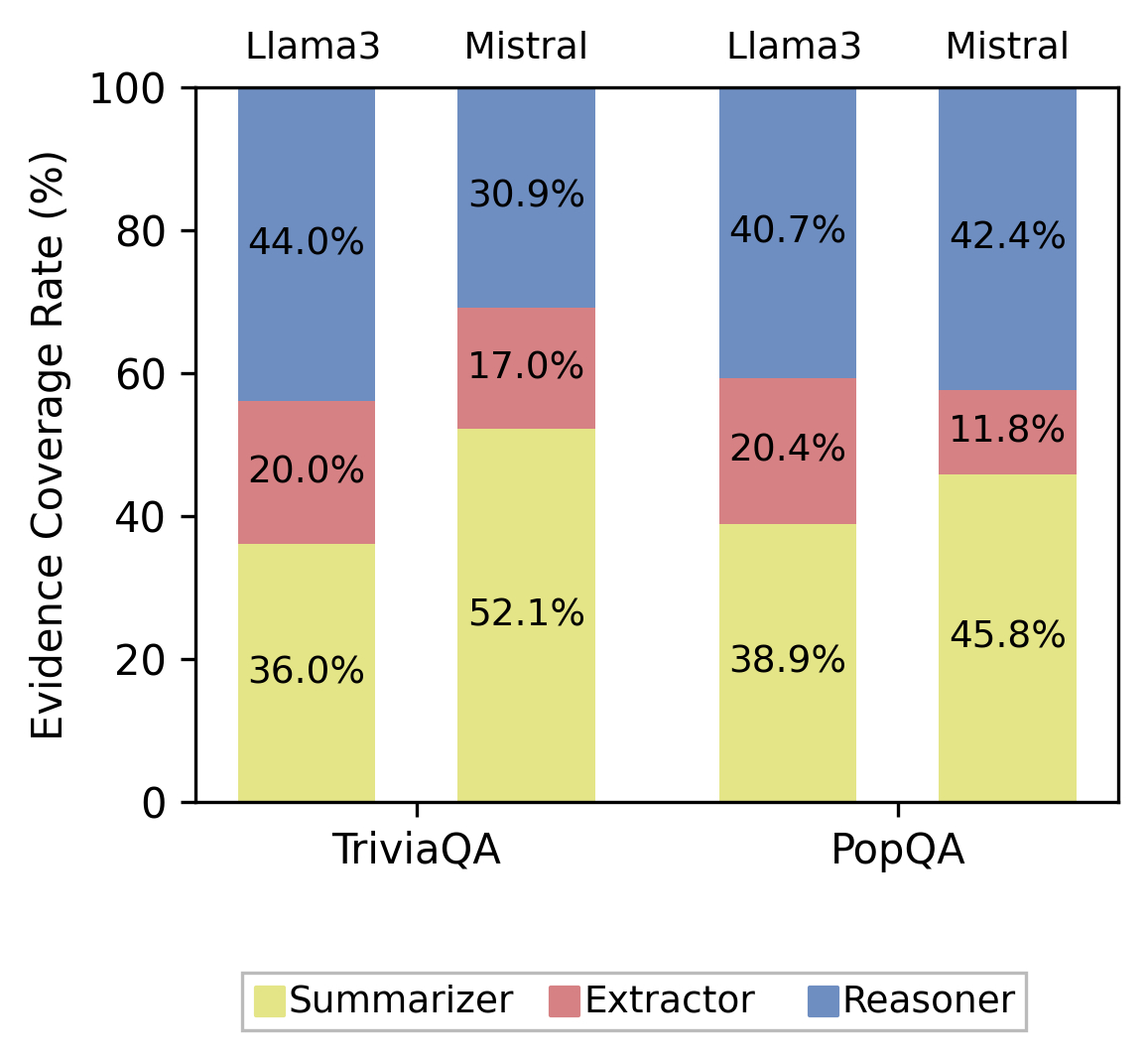
MASS-RAG 在检索阶段之后引入三类角色 agent:evidence summarization、evidence extraction、reasoning over retrieved documents。三者分别产生互补的中间证据视图,最后由一个 dedicated synthesis stage 将它们合并,生成最终答案。该流水线让模型可在答案生成前先对比并整合来自不同 agent 的证据,而不是在一次 prompt 中混合所有检索片段。
实验
摘要提到在 4 个 benchmark 上评测,并与 strong RAG baselines 对比。但未披露具体数据集名称、backbone LLM、检索器、指标细节或 agent 数量消融设置。
结果
论文声称 MASS-RAG 在四个 benchmark 上"consistently"优于强 RAG baseline,尤其在相关证据分散于多个检索上下文时增益最明显。摘要未给出具体数值,因此量化幅度与统计显著性无法从摘要判断。
为什么重要
对 RAG 系统设计者来说,它提供了一个可插拔的"多 agent 证据处理层"范式:把长且杂的检索结果拆给角色化 agent 处理,再 synthesis。这和当前把 RAG 上下文一次性塞进 LLM 的主流做法形成对比,更贴近 agentic LLM 基础设施的演进方向。
与已有工作的关系
处在 RAG(Lewis et al. 的 RAG、Self-RAG、RAG-Fusion)与 multi-agent LLM 框架(Debate、Society of Mind、AutoGen、LLM-Blender)的交汇点;思路上接近把 Chain-of-Agents、ReAct 式分工机制引入证据整合阶段。
尚未回答的问题
- 具体 benchmark、backbone、检索器与数值增益是多少?
- 多 agent 带来的推理成本与 latency 开销是否可接受?
- 各角色 agent 的必要性和消融贡献?
- 在对抗性或高度冲突证据下 synthesis 是否仍稳健?
- 是否可扩展到超长上下文或 tool-use / agentic RAG 场景?
论文图表
图 1: Figure 1 (extracted from PDF)
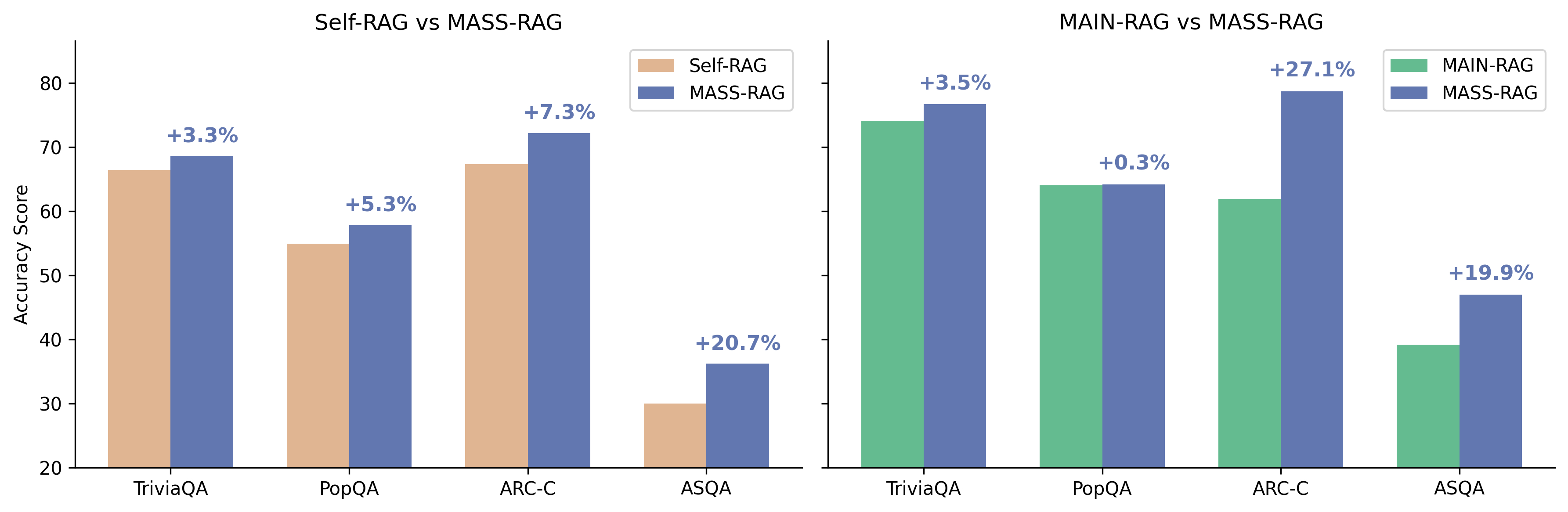
图 2: Figure 2 (extracted from PDF)
原始摘要
Large language models (LLMs) are widely used in retrieval-augmented generation (RAG) to incorporate external knowledge at inference time. However, when retrieved contexts are noisy, incomplete, or heterogeneous, a single generation process often struggles to reconcile evidence effectively. We propose \textbf{MASS-RAG}, a multi-agent synthesis approach to retrieval-augmented generation that structures evidence processing into multiple role-specialized agents. MASS-RAG applies distinct agents for evidence summarization, evidence extraction, and reasoning over retrieved documents, and combines their outputs through a dedicated synthesis stage to produce the final answer. This design exposes multiple intermediate evidence views, allowing the model to compare and integrate complementary information before answer generation. Experiments on four benchmarks show that MASS-RAG consistently improves performance over strong RAG baselines, particularly in settings where relevant evidence is distributed across retrieved contexts.