arXiv: 2604.18655 · PDF
Authors: Sravanth Kodavanti, Sowmya Vajrala, Srinivas Miriyala, Utsav Tiwari, Uttam Kumar, Utkarsh Kumar Mahawar, Achal Pratap Singh, Arya D, Narendra Mutyala, Vikram Nelvoy Rajendiran, Sharan Kumar Allur, Euntaik Lee, Dohyoung Kim, HyeonSu Lee, Gyusung Cho, JungBae Kim
Primary category: cs.DC · all: cs.AI, cs.CL, cs.DC
Matched keywords: large language model, llm, inference, quantization, speculative decoding, latency
TL;DR
A hardware-aware framework deploys a LLaMA-based multilingual foundation model on Samsung Galaxy S24/S25 phones, combining runtime multi-LoRA switching, multi-stream decoding, dynamic self-speculative decoding, and INT4 quantization to achieve 4-6x memory/latency improvements across 9 languages and 8 tasks.
Key Ideas
- Single frozen inference graph accepts application-specific LoRAs as runtime inputs, enabling dynamic task switching without recompilation.
- Multi-stream decoding produces stylistic variations (formal, polite, jovial) concurrently in one forward pass.
- Dynamic Self-Speculative Decoding (DS2D): tree-based speculative strategy without a separate draft model.
- INT4 quantization plus architectural tweaks tailored to Qualcomm SM8650/SM8750 NPUs.
Approach
The authors freeze a LLaMA-based multilingual backbone and attach multiple LoRA adapters that are injected at runtime, avoiding per-task graph rebuilds. A multi-stream decoder shares the backbone forward pass across several stylistic outputs to amortize compute. DS2D predicts candidate tokens via a tree structure using the model itself, bypassing a separate draft model. The stack is quantized to INT4 and co-optimized with the Qualcomm chipset runtime.
Experiments
Deployed on Samsung Galaxy S24 (SM8650) and S25 (SM8750). Evaluated across 9 languages and 8 application tasks. The abstract does not disclose specific datasets, baselines, or accuracy metrics used for validation.
Results
- Up to 6x latency reduction from multi-stream decoding.
- Up to 2.3x decode-time speedup via DS2D.
- Overall 4-6x improvements in memory and latency with maintained accuracy. Concrete accuracy numbers and baselines are not reported in the abstract, so the “maintained accuracy” claim is unverifiable here.
Why It Matters
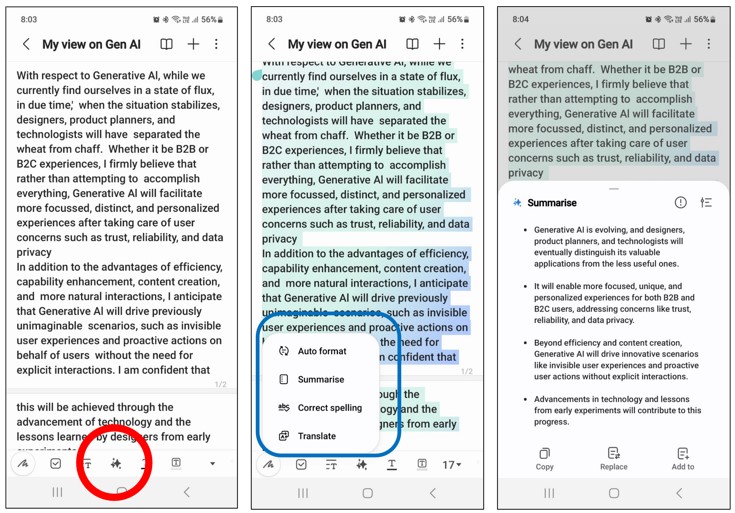
Shows a practical recipe for shipping a single on-device foundation LLM that serves many tasks and styles under tight mobile constraints, sharpening the commercial path for generative AI on smartphones without per-use-case model duplication.
Connections to Prior Work
- LoRA adapter-based multi-task serving (LoRA, S-LoRA, Punica).
- Self-speculative decoding families (Medusa, EAGLE, Lookahead, self-speculative decoding).
- Low-bit LLM quantization for edge (GPTQ, AWQ, SmoothQuant, LLM.int4).
- Prior on-device LLM work on Qualcomm/Snapdragon stacks and LLaMA derivatives.
Open Questions
- What quality degradation, if any, does INT4 plus LoRA stacking incur per language/task?
- How does DS2D compare quantitatively with Medusa/EAGLE on mobile silicon?
- Thermal and energy behavior under sustained multi-stream decoding.
- Scaling behavior with more concurrent LoRAs and memory fragmentation.
- Reproducibility outside Samsung/Qualcomm hardware.
Figures
Figure 1: Figure 1 (extracted from PDF)
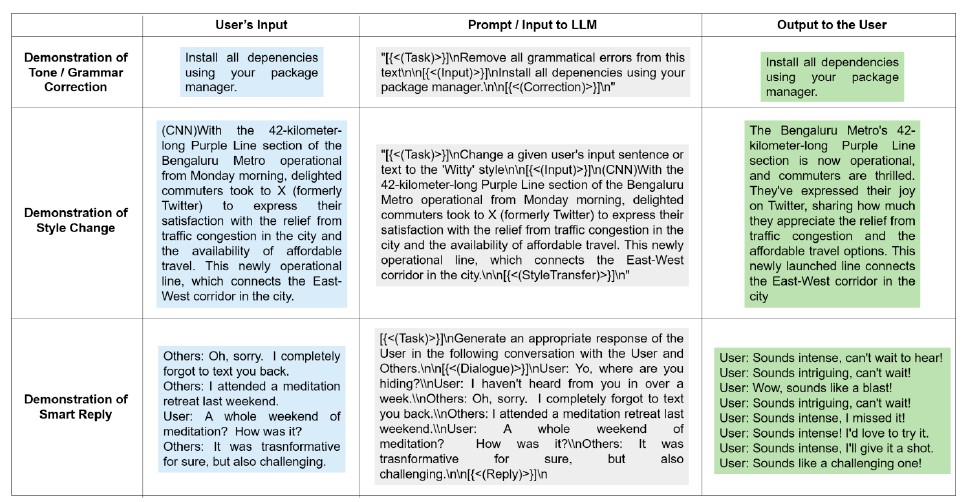
Figure 2: Figure 2 (extracted from PDF)
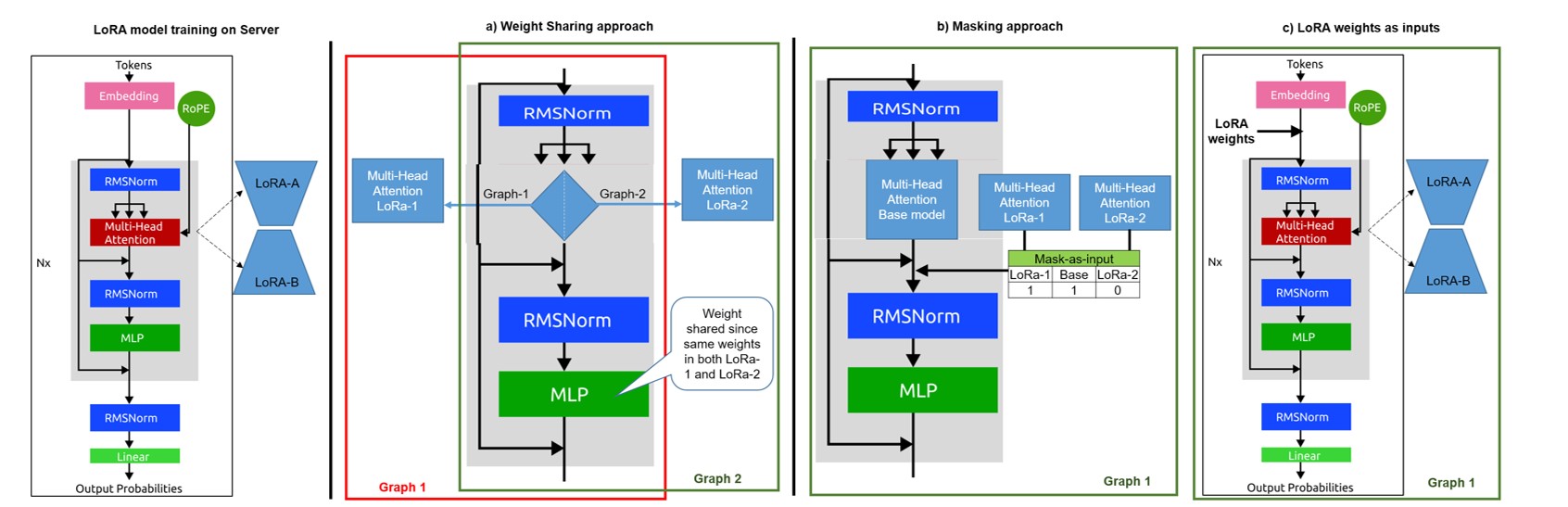
Figure 3: Figure 3 (extracted from PDF)
Original abstract
Deploying large language models (LLMs) on smartphones poses significant engineering challenges due to stringent constraints on memory, latency, and runtime flexibility. In this work, we present a hardware-aware framework for efficient on-device inference of a LLaMA-based multilingual foundation model supporting multiple use cases on Samsung Galaxy S24 and S25 devices with SM8650 and SM8750 Qualcomm chipsets respectively. Our approach integrates application-specific LoRAs as runtime inputs to a single frozen inference graph, enabling dynamic task switching without recompilation or memory overhead. We further introduce a multi-stream decoding mechanism that concurrently generates stylistic variations - such as formal, polite, or jovial responses - within a single forward pass, reducing latency by up to 6x. To accelerate token generation, we apply Dynamic Self-Speculative Decoding (DS2D), a tree-based strategy that predicts future tokens without requiring a draft model, yielding up to 2.3x speedup in decode time. Combined with quantization to INT4 and architecture-level optimizations, our system achieves 4-6x overall improvements in memory and latency while maintaining accuracy across 9 languages and 8 tasks. These results demonstrate practical feasibility of deploying multi-use-case LLMs on edge devices, advancing the commercial viability of Generative AI in mobile platforms.