arXiv: 2604.18655 · PDF
作者: Sravanth Kodavanti, Sowmya Vajrala, Srinivas Miriyala, Utsav Tiwari, Uttam Kumar, Utkarsh Kumar Mahawar, Achal Pratap Singh, Arya D, Narendra Mutyala, Vikram Nelvoy Rajendiran, Sharan Kumar Allur, Euntaik Lee, Dohyoung Kim, HyeonSu Lee, Gyusung Cho, JungBae Kim
主分类: cs.DC · 全部: cs.AI, cs.CL, cs.DC
命中关键词: large language model, llm, inference, quantization, speculative decoding, latency
TL;DR
面向三星 Galaxy S24/S25 的端侧 LLM 部署框架:用多 LoRA 共享单一冻结推理图、多流解码与 DS2D 自推测解码,实现 4–6× 内存与时延改进。
核心观点
- 以单个冻结的 LLaMA 多语基座图承载多个应用场景,通过 runtime 注入 LoRA 实现无需重编译的动态任务切换。
- 提出多流解码,在一次前向中并发生成多种风格回复,降低最多 6× 时延。
- 提出 Dynamic Self-Speculative Decoding (DS2D):无需 draft model 的树状自推测解码,decode 加速最高 2.3×。
- 与 INT4 量化、架构级优化组合,在 9 语言 / 8 任务上达成 4–6× 整体内存和时延优化且保持精度。
方法
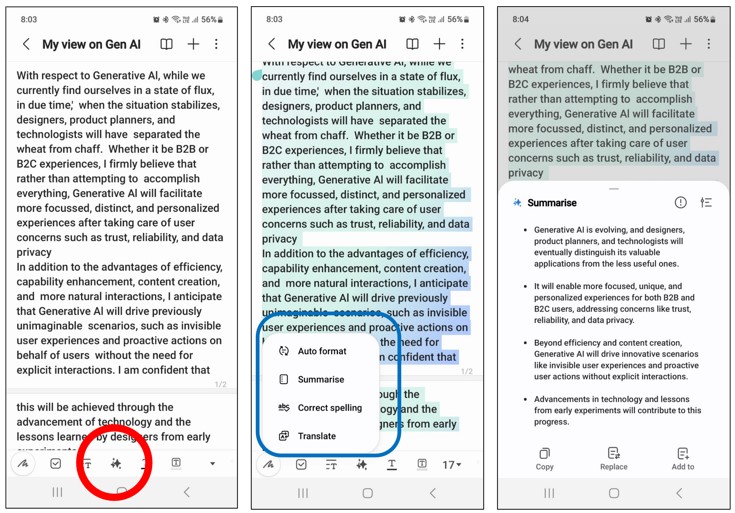
在 Qualcomm SM8650/SM8750 上做硬件感知部署:冻结一张 LLaMA 推理图,将任务 LoRA 权重作为运行时输入喂入,实现 one-for-all。解码阶段引入多流机制,让同一 forward pass 并行产生 formal/polite/jovial 等风格输出;同时使用基于树的自推测解码 DS2D,由模型自身预测未来 token,省去独立 draft 模型。模型以 INT4 量化落地,并配合架构层优化。
实验
硬件:Samsung Galaxy S24 (SM8650) 与 S25 (SM8750)。模型:LLaMA 系多语基座 + 多个应用 LoRA。覆盖 9 种语言、8 个任务;对比指标为内存占用、端到端时延、decode 时延与精度。摘要未披露具体基线名称或数据集细节。
结果
- 多流解码:时延最多降低 6×。
- DS2D:decode 时延最多加速 2.3×。
- 综合 INT4 + 架构优化:内存与时延整体改进 4–6×,9 语言 / 8 任务精度保持。摘要未给出绝对数值与具体精度指标,难以独立核验。
为什么重要
对端侧 LLM 从业者提供了一个可商用路径:单图 + 多 LoRA 解决多场景切换与内存膨胀,多流解码降低风格化生成成本,DS2D 免去部署 draft model 的工程负担,直接落地主流 Qualcomm 旗舰芯片。
与已有工作的关系
LoRA / multi-LoRA serving(S-LoRA、Punica 思路的端侧版)、speculative decoding(Medusa、Self-Speculative、EAGLE 等树状推测)、INT4 量化(GPTQ、AWQ)、端侧 LLaMA 部署(MLC-LLM、llama.cpp)。本文特色在于三者在手机 NPU 上协同。
尚未回答的问题
- 精度保持的具体幅度与任务级下降未披露。
- LoRA 切换与多流对 NPU 内存带宽的真实开销。
- DS2D 相对成熟 speculative 方法的精度/接受率对比。
- 跨更多芯片(MediaTek、Apple)与更大模型规模的可移植性。
- 能耗与热 throttling 下的稳态表现。
论文图表
图 1: Figure 1 (extracted from PDF)
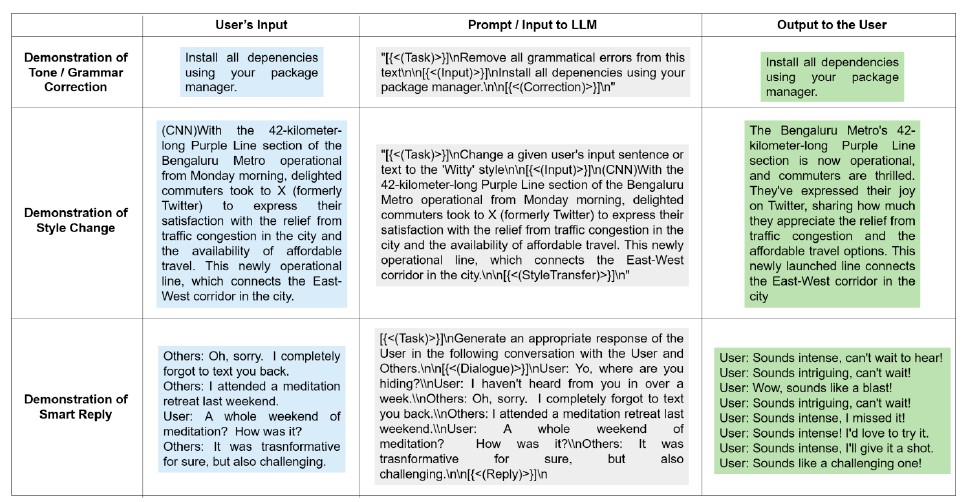
图 2: Figure 2 (extracted from PDF)
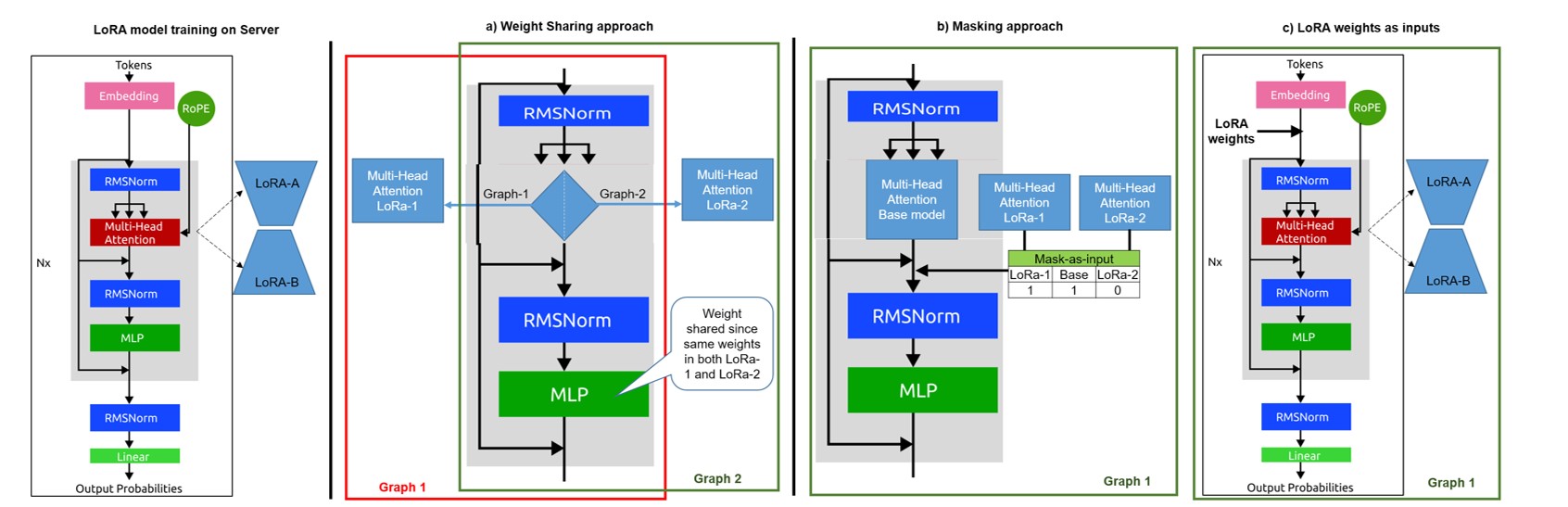
图 3: Figure 3 (extracted from PDF)
原始摘要
Deploying large language models (LLMs) on smartphones poses significant engineering challenges due to stringent constraints on memory, latency, and runtime flexibility. In this work, we present a hardware-aware framework for efficient on-device inference of a LLaMA-based multilingual foundation model supporting multiple use cases on Samsung Galaxy S24 and S25 devices with SM8650 and SM8750 Qualcomm chipsets respectively. Our approach integrates application-specific LoRAs as runtime inputs to a single frozen inference graph, enabling dynamic task switching without recompilation or memory overhead. We further introduce a multi-stream decoding mechanism that concurrently generates stylistic variations - such as formal, polite, or jovial responses - within a single forward pass, reducing latency by up to 6x. To accelerate token generation, we apply Dynamic Self-Speculative Decoding (DS2D), a tree-based strategy that predicts future tokens without requiring a draft model, yielding up to 2.3x speedup in decode time. Combined with quantization to INT4 and architecture-level optimizations, our system achieves 4-6x overall improvements in memory and latency while maintaining accuracy across 9 languages and 8 tasks. These results demonstrate practical feasibility of deploying multi-use-case LLMs on edge devices, advancing the commercial viability of Generative AI in mobile platforms.