arXiv: 2604.18170 · PDF
Authors: Ziyang Liu
Primary category: cs.CL · all: cs.AI, cs.CL
Matched keywords: llm, rag, serving, kv cache, speculative decoding, fine-tun
TL;DR
Copy-as-Decode reframes LLM text/code editing as grammar-constrained decoding over two primitives (<copy> and <gen>), letting copy spans be filled via a single parallel-prefill forward instead of N autoregressive steps, yielding large theoretical speedups without end-to-end training.
Key Ideas
- Most edit outputs are verbatim copies of the input, so regenerating them autoregressively is wasteful.
- A two-primitive grammar (
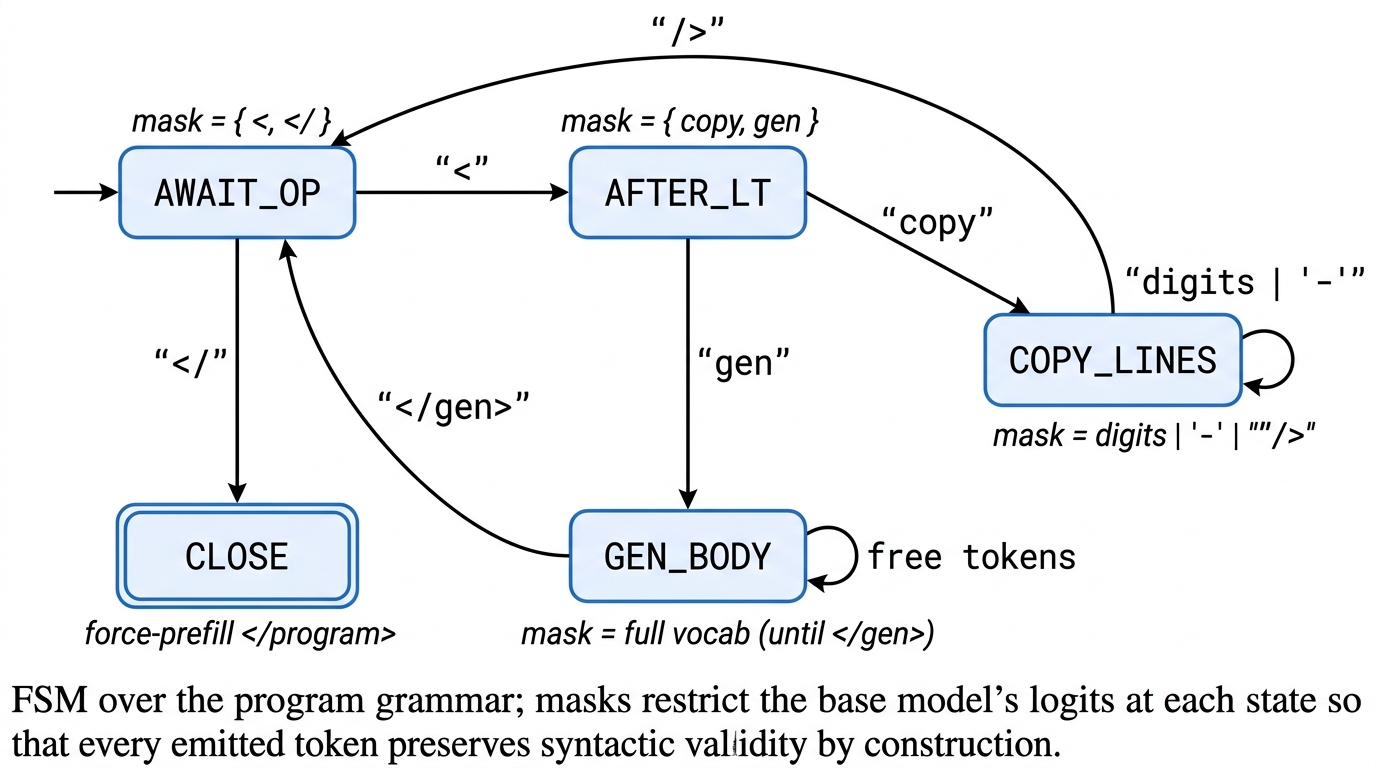
<copy lines="i-j"/>,<gen>...</gen>) with a token-level FSM guarantees syntactic validity. - Copy spans reuse the speculative-decoding parallel-forward kernel, but with input tokens as the “draft” and grammar-enforced (not probabilistic) acceptance.
- Paper gives an upper-bound analysis — no training required — separating kernel speedup, copy coverage ceiling, and pipeline losslessness.
Approach
At decode time the model emits grammar tokens; a deterministic resolver expands <copy> tags by issuing one parallel-prefill forward that updates the KV cache for the whole span, while <gen> falls back to standard autoregressive decoding. An FSM enforces legal token transitions. Line-level and finer token-level primitives are both analyzed.
Experiments
- Models: Qwen2.5-1.5B / 7B, Qwen2.5-Coder-1.5B; A100 80GB bf16.
- Benchmarks: ProbeEdit, HumanEvalPack-Fix (Python, JS); 482 oracle cases.
- Measures: kernel latency vs autoregressive, gold-token coverage under copy primitive, round-trip EM under oracle and perturbed span selection, a small fine-tuning pilot.
Results
- Kernel: 6.8×–303× speedup copying N∈[8,512] tokens.
- Coverage: 74–98% line-level, 91–99% token-level.
- Closed-form wall-clock bounds: 29.0× / 3.4× / 4.2× per corpus, 13.0× pooled (4.5×–6.5× floors token-level).
- Oracle programs round-trip losslessly on all 482 cases; off-by-one span noise collapses EM to 15.48%.
- Fine-tuning pilot lifts HEvalFix-Py EM from 0/33 to 12–17% — a learnability signal, not a deployed system.
Why It Matters
Edit-heavy workloads (code assistants, refactoring, document rewriting) dominate real LLM serving cost. This work identifies copying as the bottleneck and provides a serving-layer primitive that composes with existing speculative-decoding kernels, pointing to substantial latency wins without retraining the base model.
Connections to Prior Work
Speculative decoding (Leviathan et al., Medusa), constrained/grammar-guided decoding (Outlines, XGrammar), retrieval/copy mechanisms (CopyNet, pointer networks), and edit-as-diff code models (CodeEditor, InCoder). Distinctive in using the input itself as a deterministic draft with program-level acceptance.
Open Questions
- Can a policy reliably pick correct spans end-to-end? Off-by-one fragility is severe.
- Batched-serving and multi-file edits remain unimplemented.
- Interaction with standard speculative decoding and KV quantization is unexplored.
- Training signal beyond the tiny pilot — data, loss, and scaling behavior — is open.
Figures
Figure 1: Figure 1 (extracted from PDF)
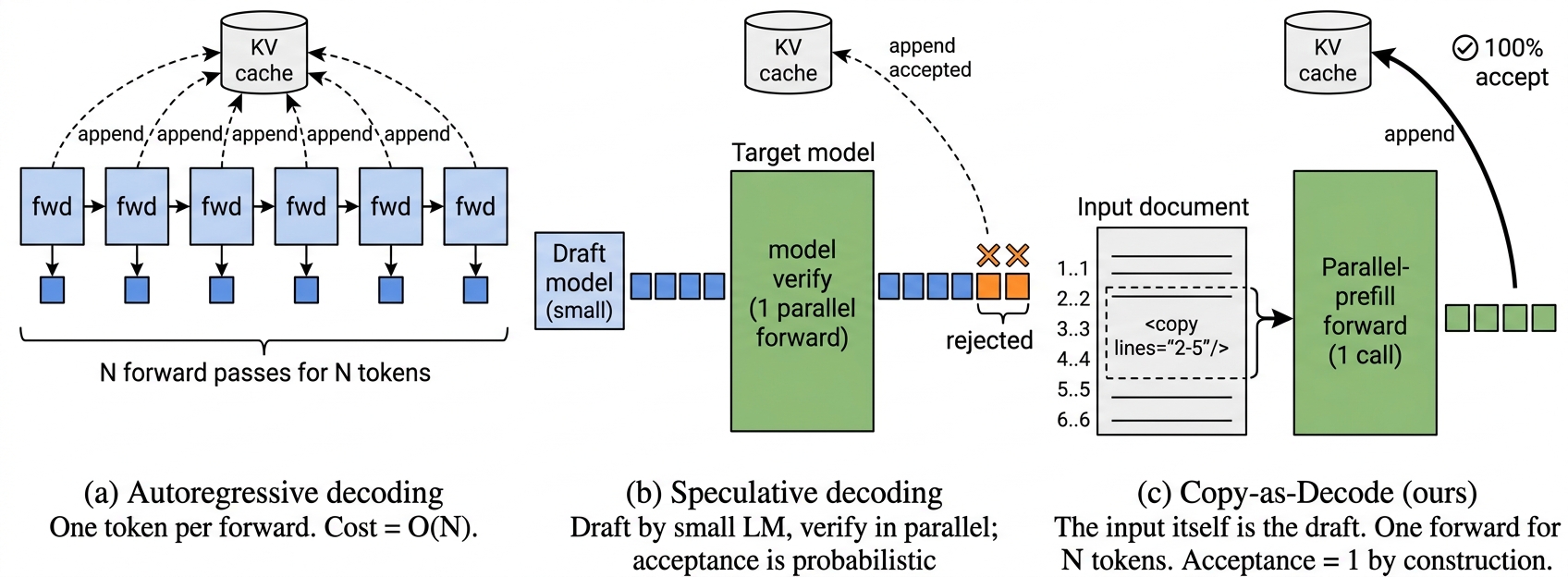
Figure 2: Figure 2 (extracted from PDF)
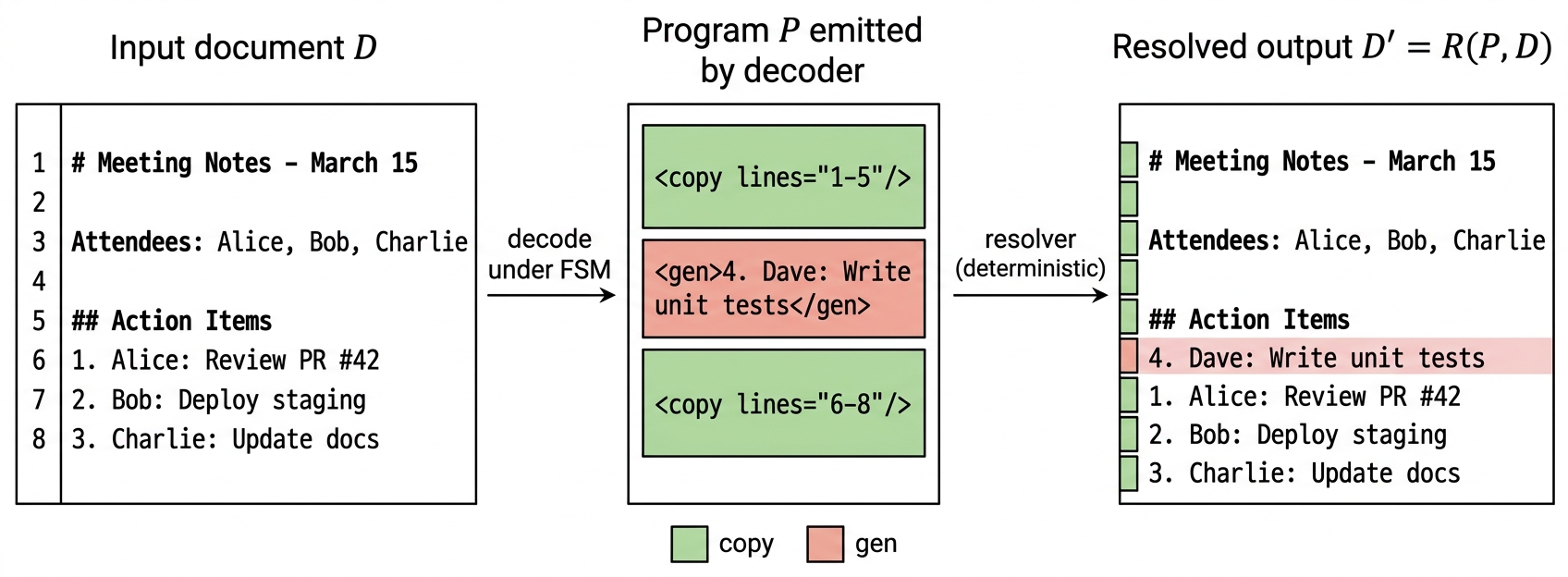
Figure 3: Figure 3 (extracted from PDF)
Original abstract
LLMs edit text and code by autoregressively regenerating the full output, even when most tokens appear verbatim in the input. We study Copy-as-Decode, a decoding-layer mechanism that recasts edit generation as structured decoding over a two-primitive grammar: