arXiv: 2604.18170 · PDF
作者: Ziyang Liu
主分类: cs.CL · 全部: cs.AI, cs.CL
命中关键词: llm, rag, serving, kv cache, speculative decoding, fine-tun
TL;DR
Copy-as-Decode 把 LLM 编辑任务重写为 <copy>/<gen> 两原语的语法约束解码,让拷贝段走并行 prefill 而非逐 token 自回归,在 Qwen2.5 上给出最高 303× 的内核加速与 13× 端到端上界。
核心观点
- 编辑输出大部分 token 与输入逐字相同,自回归重解码是浪费。
- 引入双原语语法:
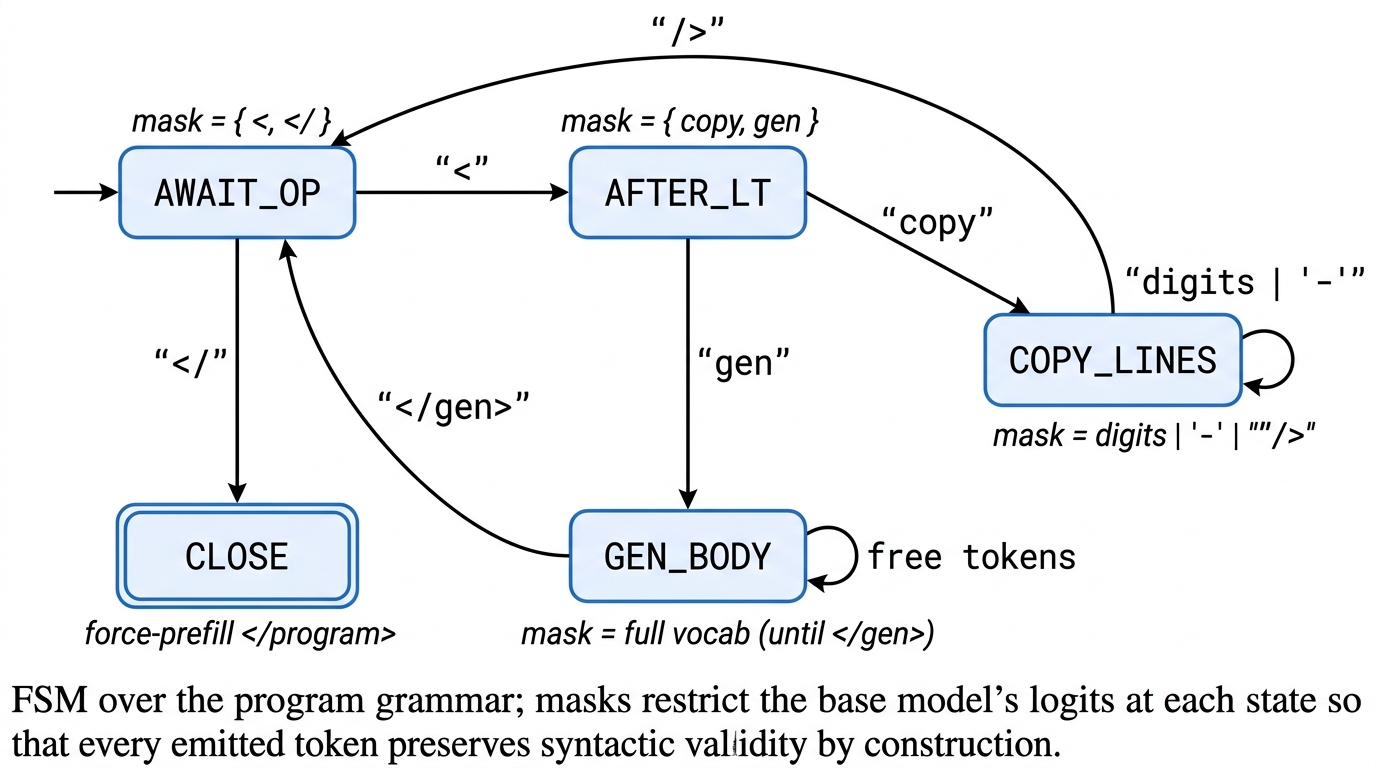
<copy lines="i-j"/>引用输入行区间,<gen>发射新内容。 - token 级 FSM 保证语法合法;服务层用一次并行 prefill 更新拷贝段 KV cache,取代 N 步自回归。
- 与 speculative decoding 共享并行 forward kernel,但以输入 token 为 draft、程序强制接受取代概率验证。
方法
在解码层把编辑过程变成 structured decoding:模型输出遵循 grammar 的 copy/gen 混合序列。拷贝跨度通过单次 parallel-prefill forward 填充 KV cache,生成跨度保持常规自回归。作者给出无需端到端训练的上界分析,并做了一次 fine-tuning pilot 作为可学习性信号。
实验
- 模型:Qwen2.5-1.5B/7B,Qwen2.5-Coder-1.5B;硬件 A100 80GB bf16。
- 数据集:ProbeEdit、HumanEvalPack-Fix(Python/JS),共 482 案例。
- 指标:kernel speedup、copy coverage、端到端 wall-clock 上界、EM、扰动鲁棒性。
结果
- Kernel:拷贝 N∈[8,512] token 比自回归快 6.8×–303×。
- Copy ceiling:行级原语覆盖 74–98% gold token;合成得到 29.0× / 3.4× / 4.2× 三语料上界,pooled 13.0×;token 级扩展覆盖 91–99%,加速下界 4.5×–6.5×。
- Pipeline:oracle program 在所有 482 case 上无损 round-trip。
- 鲁棒性:off-by-one 扰动下 pooled EM 从 100% 降至 15.48%。
- Fine-tune pilot:HEvalFix-Py EM 从 0/33 提升到 12–17%。
为什么重要
为代码/文本编辑类 agent 提供了一条不依赖新模型的推理加速路径:把 diff-style 编辑显式交给 serving 层并行 prefill,可直接叠加现有 speculative decoding kernel,潜在 10× 级端到端吞吐提升。
与已有工作的关系
延续 speculative decoding 的并行 forward 思路,但用程序化接受替代概率验证;与 constrained/grammar decoding、copy mechanism、edit-as-diff 生成(如 CodeEditor、Grace)以及 KV cache reuse/prefill 优化一脉相承。
尚未回答的问题
- 如何让模型稳定生成正确 span 选择,避免 off-by-one 崩盘。
- Batched serving 与多文件编辑场景的实际收益。
- 更大模型、非代码长文档编辑上的覆盖率与加速是否保持。
- 与 speculative decoding、prefix caching 叠加时的交互与上限。
论文图表
图 1: Figure 1 (extracted from PDF)
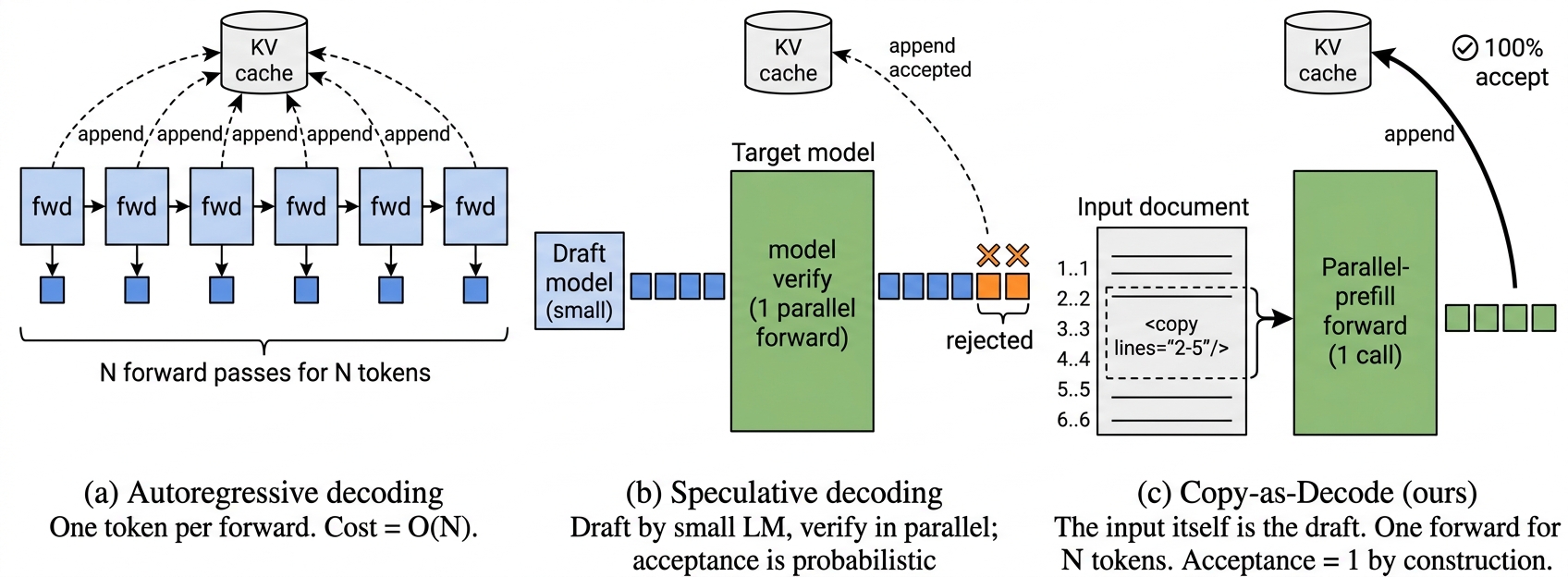
图 2: Figure 2 (extracted from PDF)
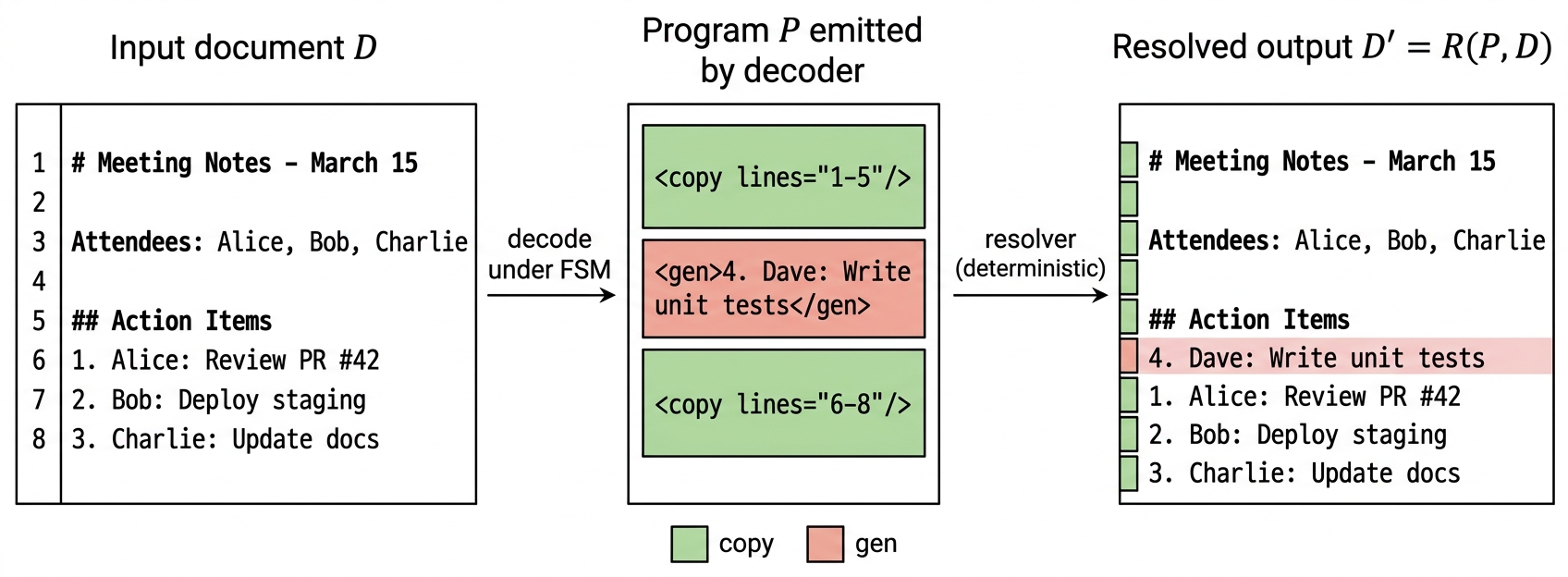
图 3: Figure 3 (extracted from PDF)
原始摘要
LLMs edit text and code by autoregressively regenerating the full output, even when most tokens appear verbatim in the input. We study Copy-as-Decode, a decoding-layer mechanism that recasts edit generation as structured decoding over a two-primitive grammar: