arXiv: 2604.19299 · PDF
Authors: Xinlin Wang, Mats Brorsson
Primary category: cs.CL · all: cs.AI, cs.CL
Matched keywords: large language model, agent, multi-agent, tool use, reasoning, latency, fine-tun
TL;DR
This paper presents the first large-scale empirical study of sub-10B open-source SLMs across three deployment paradigms—base, single-agent with tools, and multi-agent collaboration—finding that single-agent systems offer the best cost/performance balance while multi-agent setups add overhead with limited gains.
Key Ideas
- SLMs (<10B params) are viable LLM alternatives if their weaknesses are compensated by agent paradigms rather than pure scaling or fine-tuning.
- Tool-augmented single agents systematically outperform base SLMs at modest extra cost.
- Multi-agent collaboration yields diminishing returns relative to its computational overhead.
- Deployment efficiency is a first-class design criterion for trustworthy SLM systems.
Approach
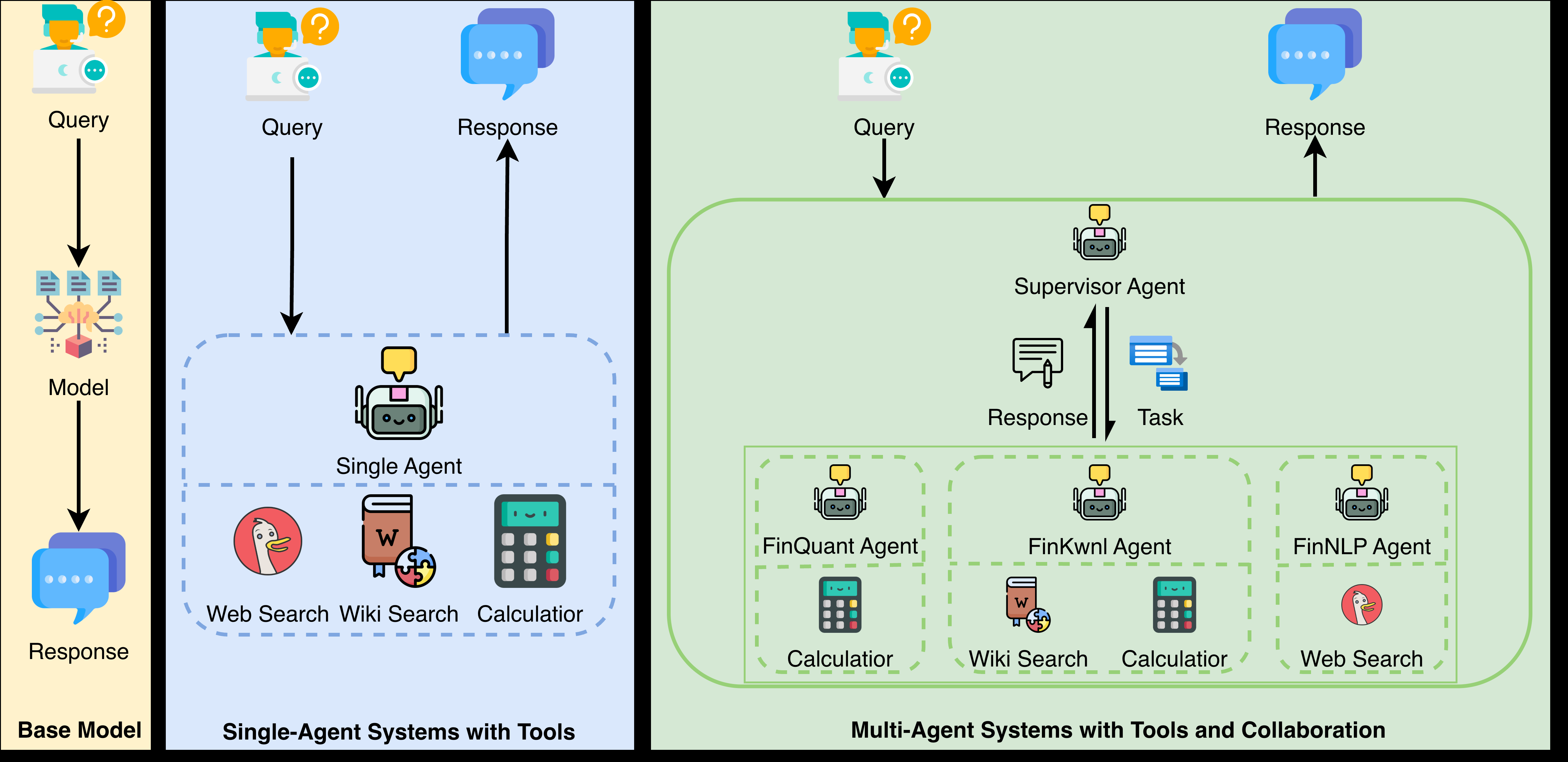
The authors benchmark open-source SLMs under three paradigms: (1) bare base model, (2) a single agent equipped with external tools, and (3) a multi-agent collaborative system. They compare performance and cost across these configurations, though the abstract does not specify which tools, orchestration framework, or agent protocols are used.
Experiments
The study covers <10B open-source models; specific model families, benchmark datasets, metrics, and baseline comparisons are not named in the abstract. Evaluation reportedly spans both task performance and deployment cost, but concrete setups are undisclosed here.
Results
Headline finding: single-agent + tools achieves the best performance/cost trade-off. Multi-agent systems incur extra orchestration and inference overhead without proportional quality gains. Exact numerical improvements are not given in the abstract.
Why It Matters
For practitioners with latency, privacy, or cost constraints, this suggests investing in tool-augmented single agents over heavier multi-agent stacks or larger base models. It reframes SLM deployment as an agent-design problem rather than a scaling problem.
Connections to Prior Work
Extends scaling-law analyses (Chinchilla, Phi series) and SLM fine-tuning literature; relates to tool-use agents (ToolFormer, ReAct), multi-agent frameworks (AutoGen, MetaGPT, CAMEL), and efficiency-oriented studies of edge/on-device LLM deployment.
Open Questions
- Which specific SLMs, tasks, and tools were tested? The abstract is thin on experimental specifics.
- Under what task categories (reasoning, coding, retrieval) does multi-agent actually pay off?
- How does the balance shift with better routing, specialized agents, or improved inter-agent communication protocols?
- Do the conclusions hold for closed-source SLMs or quantized/distilled variants?
- What are the privacy and latency measurements beyond aggregate cost?
Figures
Figure 1: Figure 1 (extracted from PDF)
Figure 2: Figure 2 (extracted from PDF)
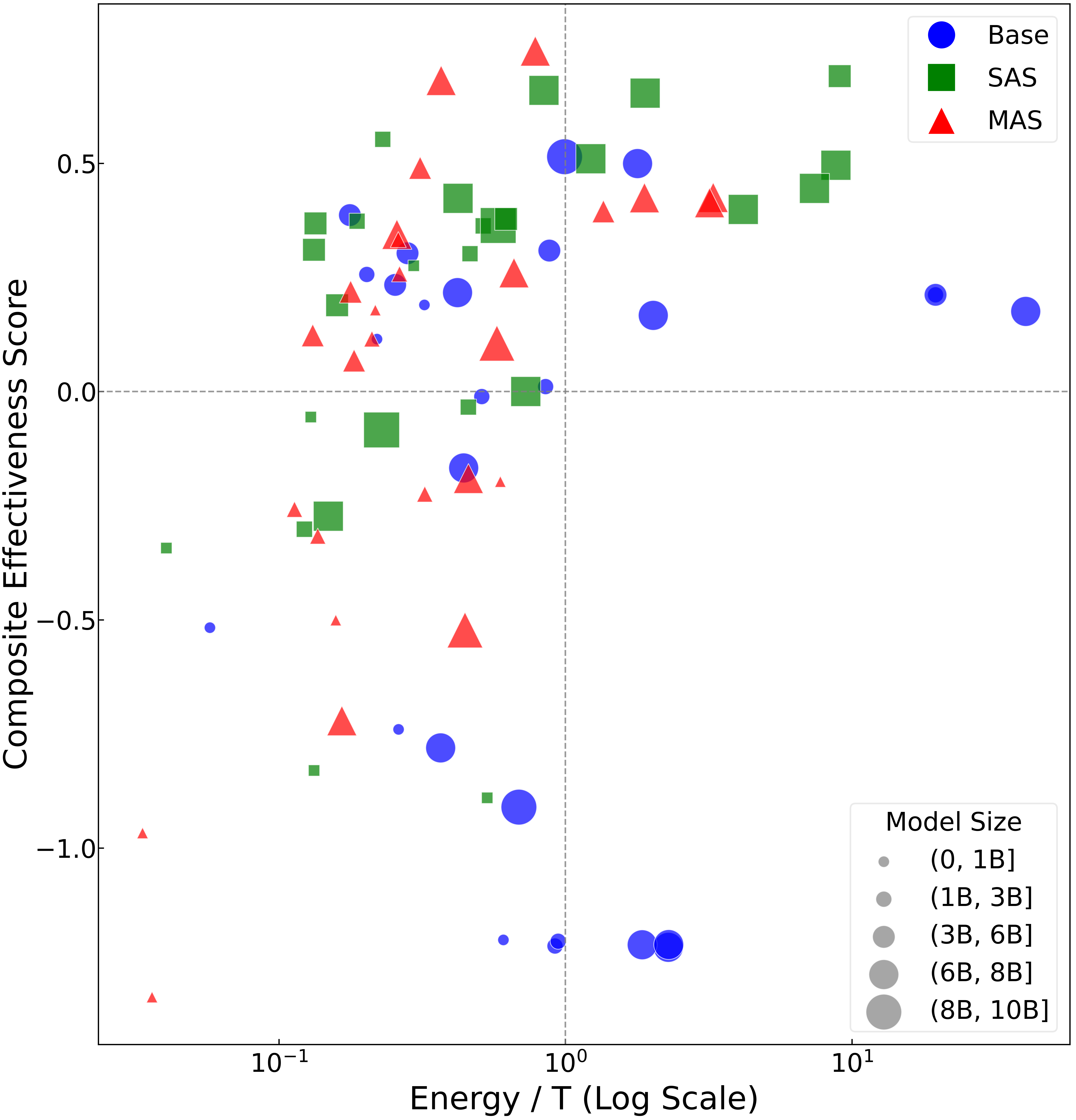
Figure 3: Figure 3 (extracted from PDF)
Original abstract
Despite the impressive capabilities of large language models, their substantial computational costs, latency, and privacy risks hinder their widespread deployment in real-world applications. Small Language Models (SLMs) with fewer than 10 billion parameters present a promising alternative; however, their inherent limitations in knowledge and reasoning curtail their effectiveness. Existing research primarily focuses on enhancing SLMs through scaling laws or fine-tuning strategies while overlooking the potential of using agent paradigms, such as tool use and multi-agent collaboration, to systematically compensate for the inherent weaknesses of small models. To address this gap, this paper presents the first large-scale, comprehensive study of <10B open-source models under three paradigms: (1) the base model, (2) a single agent equipped with tools, and (3) a multi-agent system with collaborative capabilities. Our results show that single-agent systems achieve the best balance between performance and cost, while multi-agent setups add overhead with limited gains. Our findings highlight the importance of agent-centric design for efficient and trustworthy deployment in resource-constrained settings.