arXiv: 2604.19299 · PDF
作者: Xinlin Wang, Mats Brorsson
主分类: cs.CL · 全部: cs.AI, cs.CL
命中关键词: large language model, agent, multi-agent, tool use, reasoning, latency, fine-tun
TL;DR
首次系统评估 <10B 小语言模型在 base、单 agent、多 agent 三种范式下的部署权衡,发现单 agent + 工具在性能与成本间取得最佳平衡。
核心观点
- SLM 的知识与推理短板可通过 agent 范式(工具调用、多智能体协作)系统性弥补,而非单纯依赖 scaling law 或 fine-tuning。
- 首次对 <10B 开源模型在三种部署范式下做大规模对比。
- 单 agent 系统是性能/成本最优解;多 agent 协作带来额外开销但收益有限。
- 面向资源受限场景,应采用 agent-centric 的部署设计。
方法
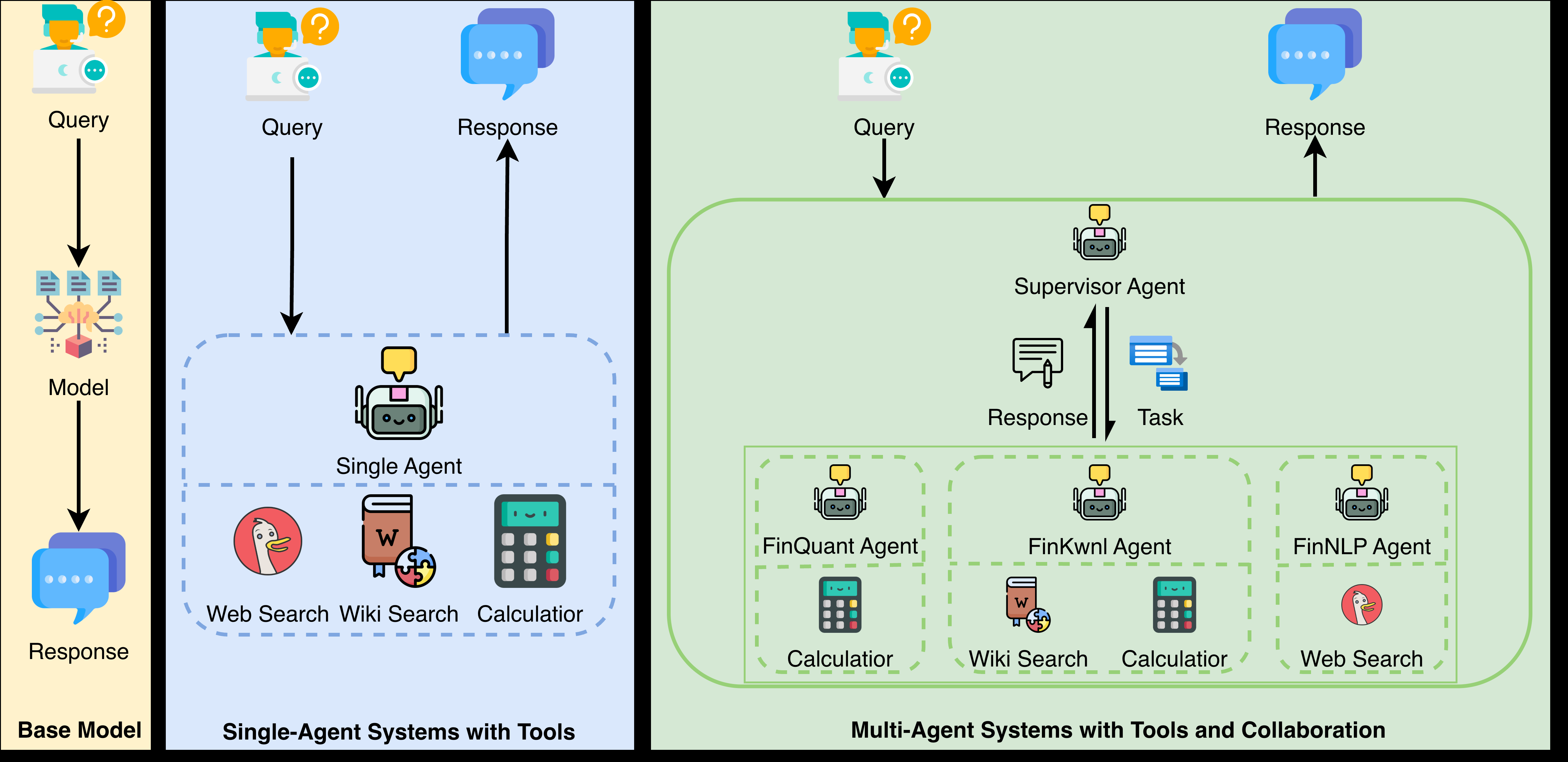
作者在三种范式下统一评测 <10B 开源模型:
- Base model:原始模型直接推理。
- Single agent:为模型配备工具(tool use)以补齐知识/推理缺口。
- Multi-agent:多个 agent 协同完成任务。 摘要未披露具体 orchestration 框架、工具集与 prompting 细节。
实验
摘要仅说明是"大规模、全面"的研究,覆盖多个 <10B 开源模型,并在三范式下横向比较性能与成本。具体数据集、基线模型列表、评估指标(如准确率、延迟、token 成本)摘要未给出。
结果
- 单 agent 方案在性能-成本权衡上最优。
- 多 agent 协作带来 overhead,收益增量有限。
- 摘要未提供具体数值或显著性分析,主张的强度难以完全核实。
为什么重要
对在边缘、私有化或成本敏感场景部署 LLM 的团队,论文给出一个清晰信号:与其堆参数或 fine-tune,不如先给 SLM 加工具。多 agent 未必是银弹,应谨慎引入复杂 orchestration。
与已有工作的关系
- SLM 研究脉络:MobileLLM、Phi、Gemma 等聚焦 scaling law 与蒸馏。
- Agent/工具使用:ReAct、Toolformer、Gorilla。
- 多 agent 协作:AutoGen、MetaGPT、CAMEL。 本文将上述方向在 <10B 模型上做统一的部署-成本评估。
尚未回答的问题
- 具体哪些任务类型下单 agent 收益最大?多 agent 何时才"值回票价"?
- 工具集规模、质量如何影响结论?
- 延迟、隐私、可靠性等非精度指标的量化结果?
- 与 7B–10B fine-tuned 专用模型的正面对比?
- 结论能否外推到 10B–30B 区间或闭源小模型?
论文图表
图 1: Figure 1 (extracted from PDF)
图 2: Figure 2 (extracted from PDF)
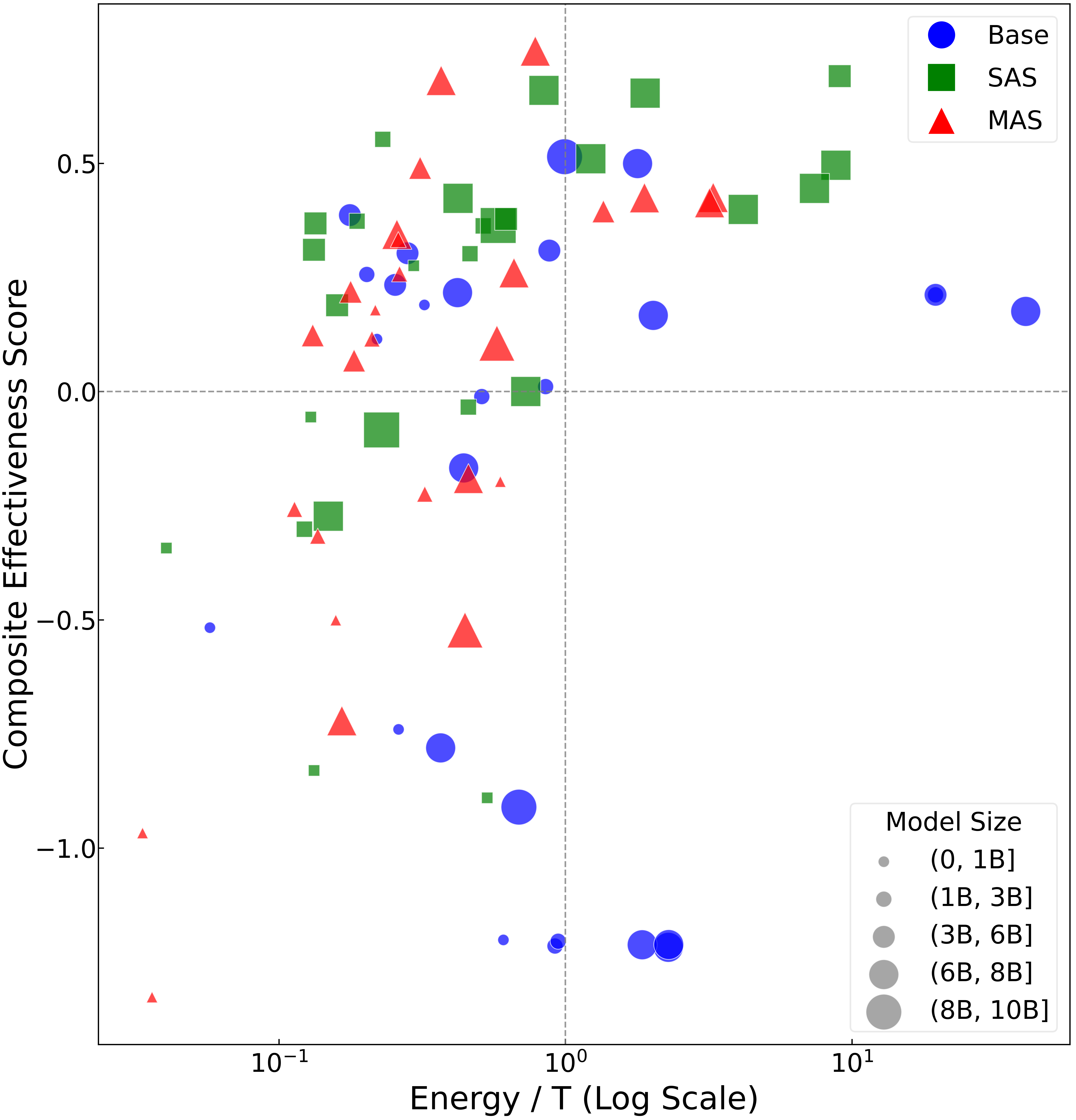
图 3: Figure 3 (extracted from PDF)
原始摘要
Despite the impressive capabilities of large language models, their substantial computational costs, latency, and privacy risks hinder their widespread deployment in real-world applications. Small Language Models (SLMs) with fewer than 10 billion parameters present a promising alternative; however, their inherent limitations in knowledge and reasoning curtail their effectiveness. Existing research primarily focuses on enhancing SLMs through scaling laws or fine-tuning strategies while overlooking the potential of using agent paradigms, such as tool use and multi-agent collaboration, to systematically compensate for the inherent weaknesses of small models. To address this gap, this paper presents the first large-scale, comprehensive study of <10B open-source models under three paradigms: (1) the base model, (2) a single agent equipped with tools, and (3) a multi-agent system with collaborative capabilities. Our results show that single-agent systems achieve the best balance between performance and cost, while multi-agent setups add overhead with limited gains. Our findings highlight the importance of agent-centric design for efficient and trustworthy deployment in resource-constrained settings.