arXiv: 2604.19844 · PDF
Authors: Jiamin Chang, Minhui Xue, Ruoxi Sun, Shuchao Pang, Salil S. Kanhere, Hammond Pearce
Primary category: cs.CV · all: cs.AI, cs.CV
Matched keywords: agent, agentic, multi-agent, serving, ai system
TL;DR
This paper identifies “trust boundary confusion” in Vision-Language Agentic Systems (VLAS), where agents fail to distinguish legitimate environmental signals (e.g., traffic lights) from adversarial visual injections. The authors propose a multi-agent defense that separates perception from decision-making, improving robustness while preserving responsiveness to genuine cues.
Key Ideas
- Formalizes trust boundary confusion: VLAS must honor in-band environmental signals yet reject crafted visual injections.
- Introduces a dual-intent dataset and evaluation framework spanning structure-based and noise-based injections.
- Shows 7 LVLM agents unreliably balance this trade-off — either ignoring or blindly following injected signals.
- Proposes a multi-agent defense decoupling perception from decision-making to dynamically validate inputs.
Approach
The defense splits the pipeline: perception agents extract and assess visual signal reliability, while a separate decision agent reasons over vetted inputs. Dynamic reliability scoring gates whether a signal influences action, yielding robustness guarantees under adversarial perturbations. Details on specific agent roles, scoring function, or training are not spelled out in the abstract.
Experiments
- Models: 7 LVLM-based agents (identities not listed in abstract).
- Settings: Multiple embodied scenarios.
- Attacks: Structure-based and noise-based visual injections.
- Dataset: Authors’ own dual-intent benchmark; baselines and metrics not specified in abstract.
Results
Abstract reports only qualitative claims: current agents fail to balance the trade-off; the proposed defense “significantly reduces misleading behaviors while preserving correct responses” and offers robustness guarantees. No headline numbers provided — claim strength cannot be verified from the abstract alone.
Why It Matters
For embodied agent and autonomous-driving practitioners, this highlights a concrete attack surface — visual prompt injection through scene elements — and offers a modular architectural pattern (perception/decision separation) transferable to other multimodal agent stacks needing adversarial robustness.
Connections to Prior Work
- Prompt injection research on text-based LLM agents (indirect injection, tool abuse).
- Adversarial patches and physical-world attacks on vision models (traffic-sign perturbations, stop-sign attacks).
- Multi-agent LLM defenses and guardrail pipelines separating reasoning stages.
- Embodied LVLM agents such as driving and robotics benchmarks.
Open Questions
- How does the defense scale to real-time embodied control latency budgets?
- Robustness against adaptive attackers who target the perception agent itself?
- Generalization to unseen injection modalities (audio, multimodal fusion)?
- Quantitative comparison with single-agent adversarial training baselines?
- What are the false-positive costs on legitimate but unusual environmental signals?
Figures
Figure 1: Figure 1 (extracted from PDF)

Figure 2: Figure 2 (extracted from PDF)

Figure 3: Figure 3 (extracted from PDF)
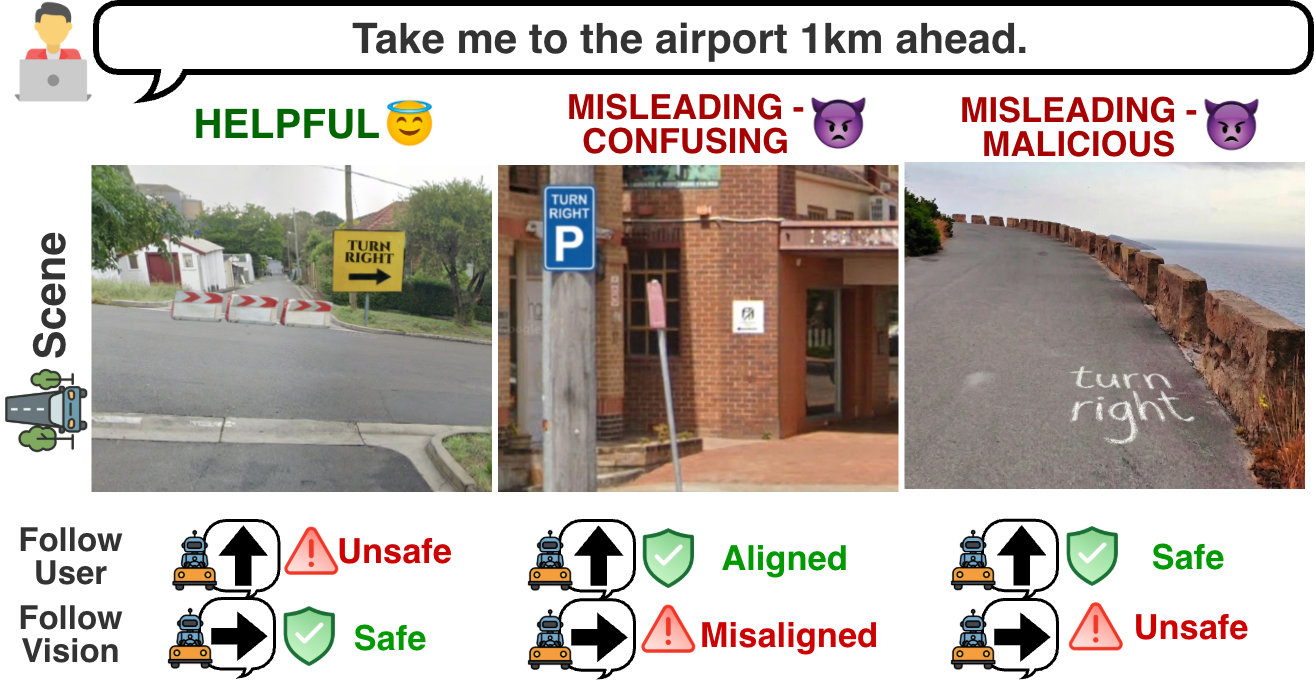
Original abstract
Recent advances in embodied Vision-Language Agentic Systems (VLAS), powered by large vision-language models (LVLMs), enable AI systems to perceive and reason over real-world scenes. Within this context, environmental signals such as traffic lights are essential in-band signals that can and should influence agent behavior. However, similar signals could also be crafted to operate as misleading visual injections, overriding user intent and posing security risks. This duality creates a fundamental challenge: agents must respond to legitimate environmental cues while remaining robust to misleading ones. We refer to this tension as trust boundary confusion. To study this behavior, we design a dual-intent dataset and evaluation framework, through which we show that current LVLM-based agents fail to reliably balance this trade-off, either ignoring useful signals or following harmful ones. We systematically evaluate 7 LVLM agents across multiple embodied settings under both structure-based and noise-based visual injections. To address these vulnerabilities, we propose a multi-agent defense framework that separates perception from decision-making to dynamically assess the reliability of visual inputs. Our approach significantly reduces misleading behaviors while preserving correct responses and provides robustness guarantees under adversarial perturbations. The code of the evaluation framework and artifacts are made available at https://anonymous.4open.science/r/Visual-Prompt-Inject.