arXiv: 2604.19844 · PDF
作者: Jiamin Chang, Minhui Xue, Ruoxi Sun, Shuchao Pang, Salil S. Kanhere, Hammond Pearce
主分类: cs.CV · 全部: cs.AI, cs.CV
命中关键词: agent, agentic, multi-agent, serving, ai system
TL;DR
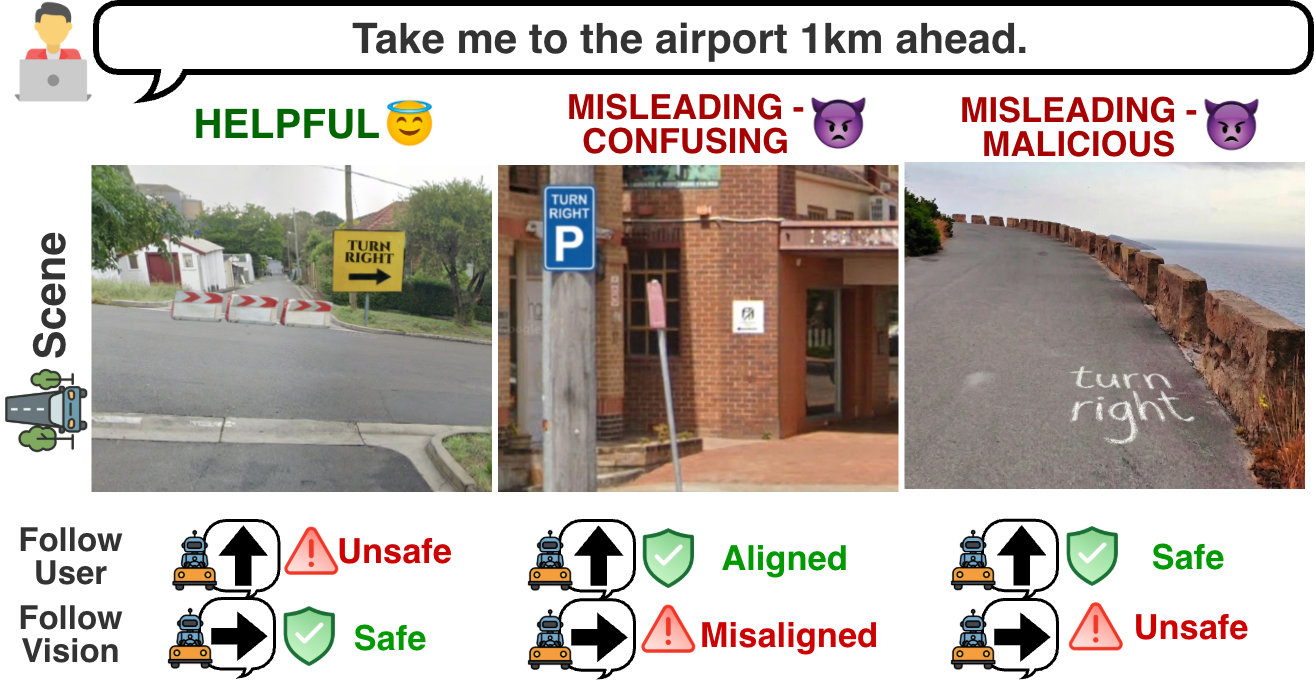
针对视觉语言 agent 在真实环境信号与恶意视觉注入之间的"信任边界混淆"问题,提出双意图评测集与多 agent 防御框架,分离感知与决策以动态评估视觉输入可信度。
核心观点
- 首次定义 trust boundary confusion:VLAS 必须响应合法环境信号(如交通灯),又要抵御伪装成环境信号的视觉注入。
- 现有 LVLM agent 要么忽略有用信号,要么盲从恶意注入,无法平衡权衡。
- 提出将 感知与决策解耦 的多 agent 防御架构,可在对抗扰动下提供鲁棒性保证。
方法
- 构建 dual-intent dataset:同一视觉信号既可能是合法指令也可能是注入攻击,用以测量二元权衡。
- 设计评测框架,覆盖 structure-based(结构伪造,如假交通牌)与 noise-based(像素级扰动)两类视觉注入。
- 防御侧:多 agent 流水线——独立的 perception agent 负责识别/验证视觉线索来源与可信度,decision agent 基于可信度评分执行;二者通信带显式信任信号。
实验
- 在多种 embodied 场景下评测 7 个 LVLM agents。
- 同时施加结构注入与噪声注入两种攻击。
- 指标围绕:对合法环境信号的遵从率、对恶意注入的抵抗率、综合权衡表现。
结果
摘要未给出具体数值,仅称防御框架"显著降低误导行为,同时保留对合法信号的正确响应",并在对抗扰动下具有鲁棒性保证。具体幅度、7 个模型排名、是否存在 trade-off 开销需看正文。
为什么重要
对 embodied agent、自动驾驶、机器人从业者:揭示仅靠单体 LVLM 无法区分环境信号与对抗注入;perception/decision 解耦 是可落地的防御范式,与 prompt injection 防御中的 “planner-executor 分离” 思路呼应,可直接用于 VLA 系统安全加固。
与已有工作的关系
- 延续 prompt injection / indirect injection 在多模态侧的研究(Greshake 等)。
- 承接 adversarial patch / physical adversarial example(交通牌攻击系列)工作。
- 与 multi-agent LLM defense(如 Spotlighting、dual-LLM pattern)在架构上一脉相承,将其迁移到视觉域。
- 评测方式借鉴 embodied agent benchmark(如 VLABench、EmbodiedBench)但聚焦安全维度。
尚未回答的问题
- 多 agent 防御的延迟与算力开销,是否适合实时 embodied 场景?
- perception agent 本身是否会成为新的攻击面?
- 对 自适应/白盒攻击者 是否仍鲁棒,摘要的"robustness guarantees"强度如何?
- 数据集仅覆盖交通灯等少量信号,能否推广到更复杂语义(手势、文本指令牌)?
- 与端到端对抗训练相比,解耦架构的代价/收益曲线如何?
论文图表
图 1: Figure 1 (extracted from PDF)

图 2: Figure 2 (extracted from PDF)

图 3: Figure 3 (extracted from PDF)
原始摘要
Recent advances in embodied Vision-Language Agentic Systems (VLAS), powered by large vision-language models (LVLMs), enable AI systems to perceive and reason over real-world scenes. Within this context, environmental signals such as traffic lights are essential in-band signals that can and should influence agent behavior. However, similar signals could also be crafted to operate as misleading visual injections, overriding user intent and posing security risks. This duality creates a fundamental challenge: agents must respond to legitimate environmental cues while remaining robust to misleading ones. We refer to this tension as trust boundary confusion. To study this behavior, we design a dual-intent dataset and evaluation framework, through which we show that current LVLM-based agents fail to reliably balance this trade-off, either ignoring useful signals or following harmful ones. We systematically evaluate 7 LVLM agents across multiple embodied settings under both structure-based and noise-based visual injections. To address these vulnerabilities, we propose a multi-agent defense framework that separates perception from decision-making to dynamically assess the reliability of visual inputs. Our approach significantly reduces misleading behaviors while preserving correct responses and provides robustness guarantees under adversarial perturbations. The code of the evaluation framework and artifacts are made available at https://anonymous.4open.science/r/Visual-Prompt-Inject.