arXiv: 2604.19157 · PDF
Authors: Jinda Jia, Jisen Li, Zhongzhu Zhou, Jung Hwan Heo, Jue Wang, Tri Dao, Shuaiwen Leon Song, Ben Athiwaratkun, Chenfeng Xu, Tianyi Zhang, Xiaoxia Wu
Primary category: cs.LG · all: cs.LG
Matched keywords: llm, serving, kv-cache, quantization, attention, throughput, latency
TL;DR
SAW-INT4 proposes token-wise INT4 KV-cache quantization with block-diagonal Hadamard rotation, the simplest scheme compatible with paged memory and fused attention in real LLM serving. A fused rotation-quantization kernel matches plain INT4 throughput while recovering nearly all accuracy lost to naive INT4.
Key Ideas
- KV-cache compression must respect serving constraints: paged layouts, regular access, fused attention.
- Most “advanced” quantization methods (vector quantization, Hessian-aware) become impractical or only marginally better under these constraints.
- Token-wise INT4 + block-diagonal Hadamard rotation is the minimal viable recipe.
- Compression is fundamentally a systems co-design problem, not just an accuracy problem.
Approach
- Enumerate 4-bit KV-cache quantization variants and filter by serving compatibility (paging, fused attention).
- Apply per-token INT4 quantization with block-diagonal Hadamard rotation to smooth outliers without full-matrix rotation cost.
- Implement a fused rotation + quantization CUDA kernel that writes directly into paged KV-cache blocks.
- Integrate with standard serving stacks so rotation adds zero end-to-end overhead.
Experiments
Abstract mentions “multiple models and benchmarks” but does not name specific LLMs, datasets, or baselines. Comparisons are against naive INT4, vector quantization, and Hessian-aware quantization, measured on accuracy recovery and serving throughput across concurrency levels.
Results
- Token-wise INT4 + block-diagonal Hadamard recovers nearly all accuracy lost by naive INT4.
- Complex methods (VQ, Hessian-aware) yield only marginal extra gains once serving constraints apply.
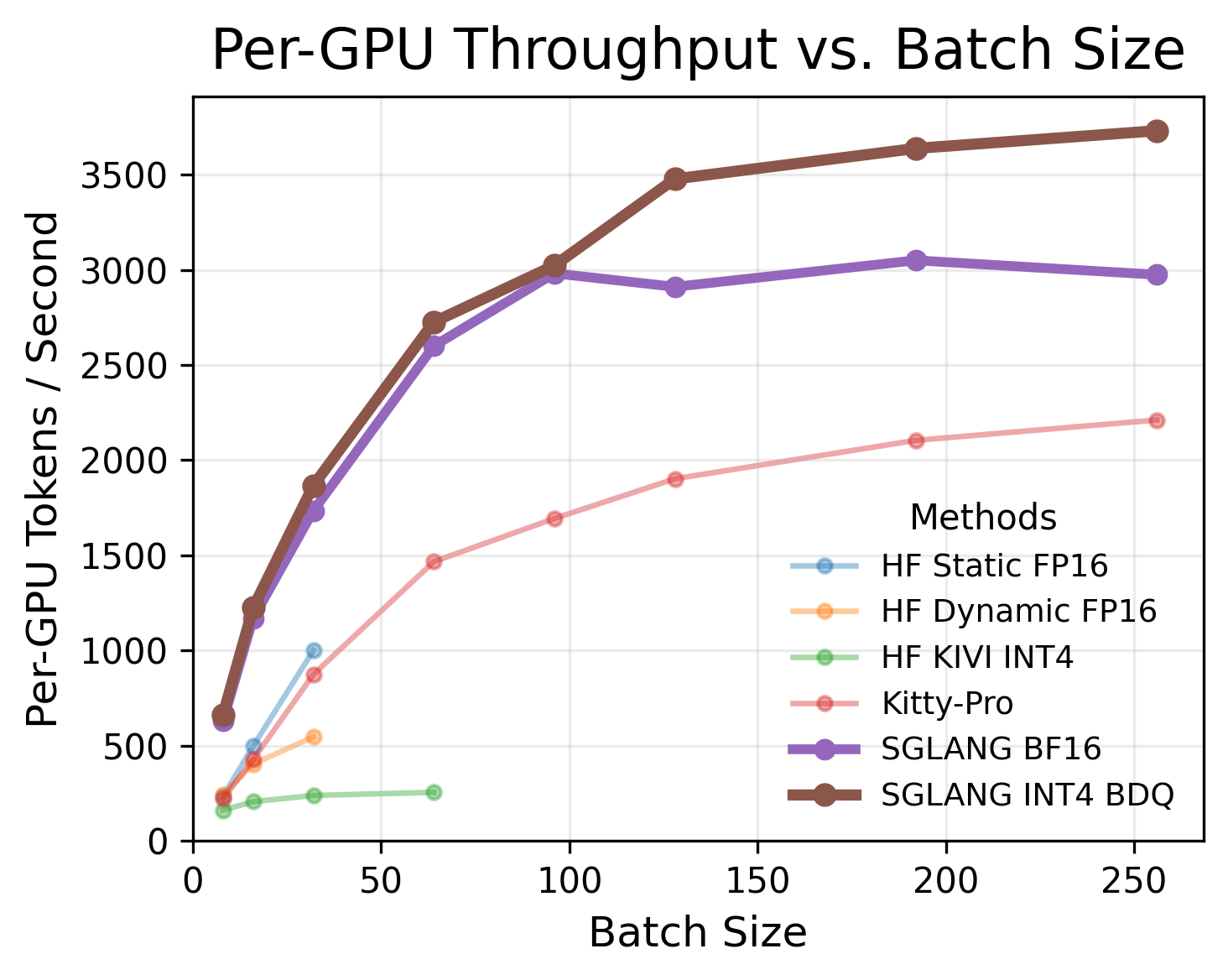
- Fused kernel: zero measurable end-to-end overhead vs plain INT4 across concurrency levels.
- Specific numbers not provided in the abstract.
Why It Matters
Gives serving-system engineers a drop-in KV-cache compressor that halves KV memory without hurting latency or throughput, enabling larger batches and longer contexts. Reframes KV quantization research: accuracy-only benchmarks overstate gains of fancy methods that break paging or fused attention.
Connections to Prior Work
- KV-cache quantization: KIVI, KVQuant, QServe.
- Rotation-based quantization: QuaRot, SpinQuant, Hadamard-based smoothing (QuIP#).
- Paged attention serving: vLLM / PagedAttention, FlashAttention fused kernels.
- Hessian-aware quantization: GPTQ lineage.
- Vector quantization for KV: AQLM-style approaches.
Open Questions
- Which models and benchmarks were evaluated, and at what context lengths?
- How does it behave at INT3/INT2 or mixed precision?
- Interaction with KV eviction / sparsity methods (H2O, StreamingLLM)?
- Robustness on long-context reasoning and agentic workloads where outliers differ?
- Training-time or QAT variants to further close the accuracy gap?
Figures
Figure 1: Figure 1 (extracted from PDF)
Figure 2: Figure 2 (extracted from PDF)
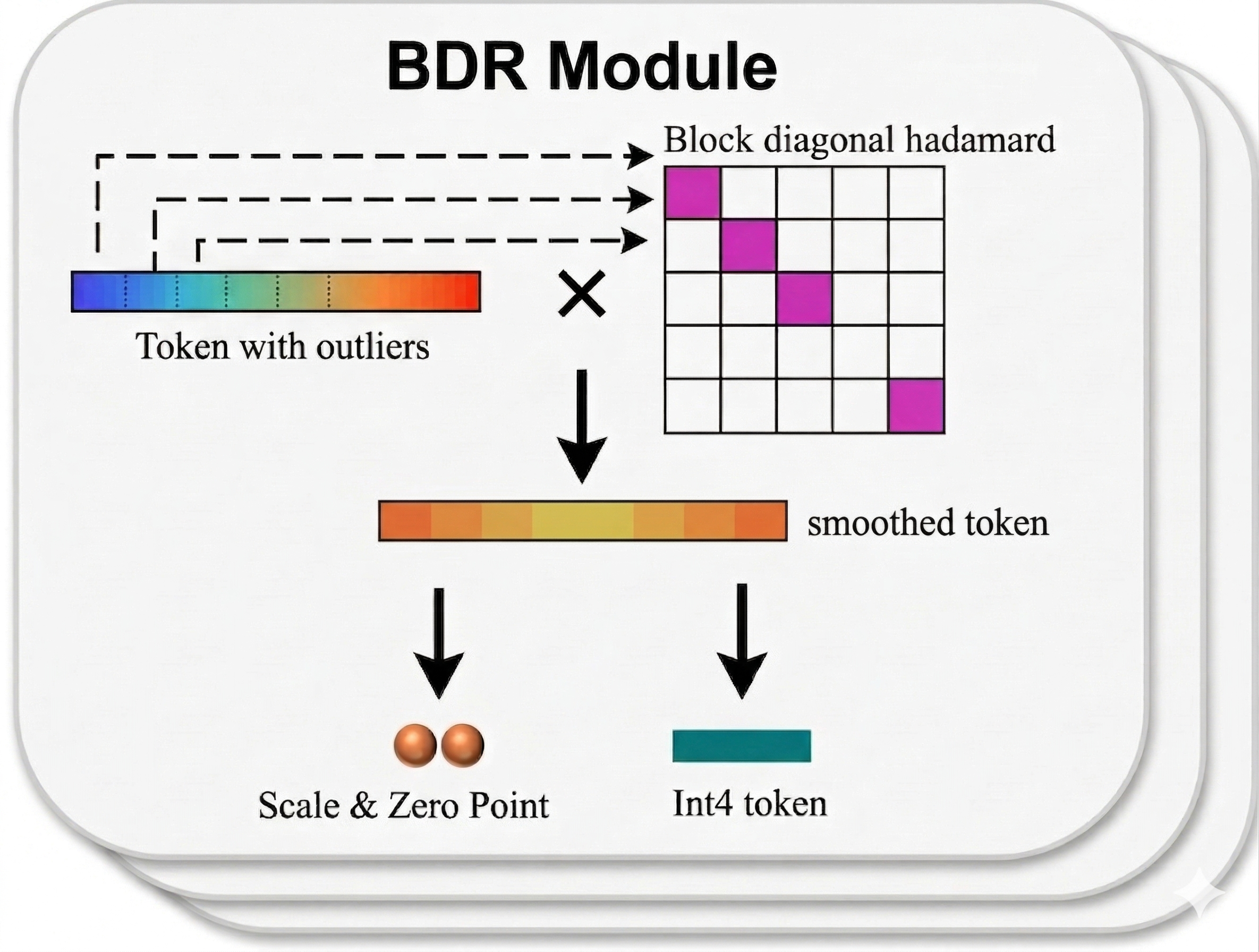
Figure 3: Figure 3 (extracted from PDF)
Original abstract
KV-cache memory is a major bottleneck in real-world LLM serving, where systems must simultaneously support latency-sensitive small-batch requests and high-throughput concurrent workloads. Although many KV-cache compression methods improve offline accuracy or compression ratio, they often violate practical serving constraints such as paged memory layouts, regular memory access, and fused attention execution, limiting their effectiveness in deployment. In this work, we identify the minimal set of 4-bit KV-cache quantization methods that remain viable under these constraints. Our central finding is that a simple design–token-wise INT4 quantization with block-diagonal Hadamard rotation–consistently achieves the best accuracy-efficiency trade-off. Across multiple models and benchmarks, this approach recovers nearly all of the accuracy lost by naive INT4, while more complex methods such as vector quantization and Hessian-aware quantization provide only marginal additional gains once serving compatibility is taken into account. To make this practical, we implement a fused rotation-quantization kernel that integrates directly into paged KV-cache layouts and introduces zero measurable end-to-end overhead, matching plain INT4 throughput across concurrency levels. Our results show that effective KV-cache compression is fundamentally a systems co-design problem: under real serving constraints, lightweight block-diagonal Hadamard rotation is a viable method that delivers near-lossless accuracy without sacrificing serving efficiency.