arXiv: 2604.19157 · PDF
作者: Jinda Jia, Jisen Li, Zhongzhu Zhou, Jung Hwan Heo, Jue Wang, Tri Dao, Shuaiwen Leon Song, Ben Athiwaratkun, Chenfeng Xu, Tianyi Zhang, Xiaoxia Wu
主分类: cs.LG · 全部: cs.LG
命中关键词: llm, serving, kv-cache, quantization, attention, throughput, latency
TL;DR
SAW-INT4 提出 token-wise INT4 + block-diagonal Hadamard 旋转的 KV-cache 量化方案,在 paged attention 等真实 serving 约束下几乎无损恢复精度且零额外开销。
核心观点
- KV-cache 压缩需作为系统协同设计问题看待,必须兼容 paged 内存布局、规则访存与 fused attention。
- 在这些约束下,简单的 token-wise INT4 + 块对角 Hadamard 旋转就能逼近最佳精度-效率折中。
- 更复杂的 vector quantization、Hessian-aware 量化在考虑 serving 兼容性后仅带来边际收益。
- 融合旋转-量化 kernel 可直接嵌入 paged KV-cache,实测端到端零额外开销。
方法
作者筛选出在 serving 约束下仍可行的 4-bit KV 量化方法的最小集合,核心设计为 token-wise INT4 量化配合 block-diagonal Hadamard 旋转以抑制 outlier。随后实现一个 fused rotation-quantization kernel,将旋转与量化与 paged KV-cache 布局对齐,直接与 fused attention 执行路径集成。
实验
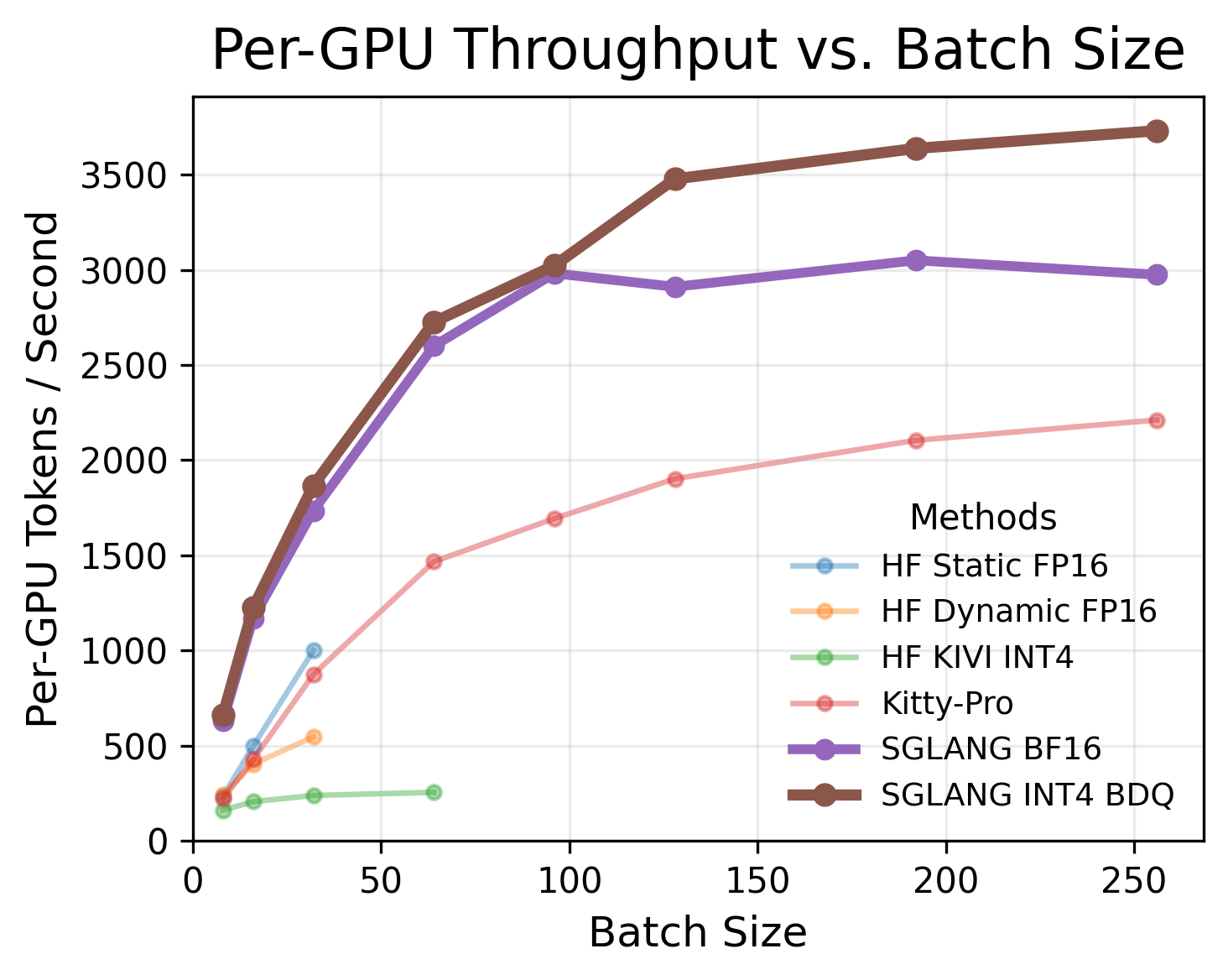
跨多个模型与 benchmark 评估精度恢复程度;与 naive INT4、vector quantization、Hessian-aware quantization 等方案比较;在不同并发度下对比吞吐量与端到端延迟。具体模型与数据集摘要未给出。
结果
token-wise INT4 + 块对角 Hadamard 几乎恢复 naive INT4 损失的全部精度;更复杂方法仅带来边际提升。融合 kernel 达到与 plain INT4 同等吞吐,端到端开销不可测。
为什么重要
对 LLM serving 基础设施团队,给出一个在 paged attention、fused kernel 等工业约束下真正可落地的 KV-cache 压缩方案:近无损精度 + 零额外开销,直接缓解长上下文、高并发场景下的显存瓶颈。
与已有工作的关系
延续 KVQuant、KIVI 等 KV-cache 量化线路;借鉴 QuIP、SpinQuant 的 Hadamard/旋转式 outlier 抑制;对比 vector quantization 与 Hessian-aware(如 GPTQ 系)方法;与 PagedAttention / vLLM 的系统抽象直接对接。
尚未回答的问题
- 在更长上下文(>128k)与 MoE、多模态模型上的表现?
- 是否可与 weight/activation 量化联合,进一步压榨端到端吞吐?
- 块对角 Hadamard 的块大小、旋转选择是否需按模型调参?
- 低于 4-bit(INT3/INT2)时此范式是否仍成立?
论文图表
图 1: Figure 1 (extracted from PDF)
图 2: Figure 2 (extracted from PDF)
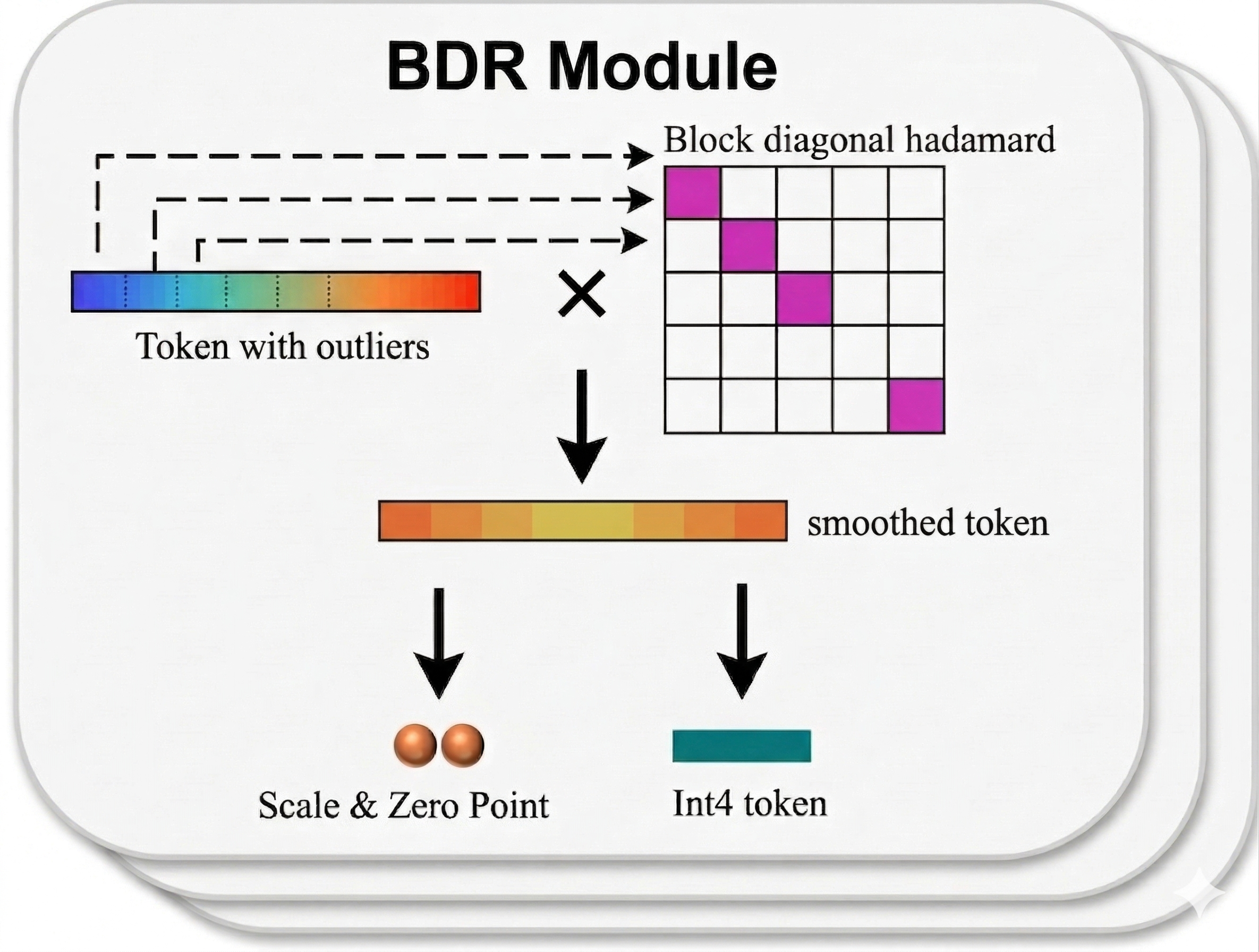
图 3: Figure 3 (extracted from PDF)
原始摘要
KV-cache memory is a major bottleneck in real-world LLM serving, where systems must simultaneously support latency-sensitive small-batch requests and high-throughput concurrent workloads. Although many KV-cache compression methods improve offline accuracy or compression ratio, they often violate practical serving constraints such as paged memory layouts, regular memory access, and fused attention execution, limiting their effectiveness in deployment. In this work, we identify the minimal set of 4-bit KV-cache quantization methods that remain viable under these constraints. Our central finding is that a simple design–token-wise INT4 quantization with block-diagonal Hadamard rotation–consistently achieves the best accuracy-efficiency trade-off. Across multiple models and benchmarks, this approach recovers nearly all of the accuracy lost by naive INT4, while more complex methods such as vector quantization and Hessian-aware quantization provide only marginal additional gains once serving compatibility is taken into account. To make this practical, we implement a fused rotation-quantization kernel that integrates directly into paged KV-cache layouts and introduces zero measurable end-to-end overhead, matching plain INT4 throughput across concurrency levels. Our results show that effective KV-cache compression is fundamentally a systems co-design problem: under real serving constraints, lightweight block-diagonal Hadamard rotation is a viable method that delivers near-lossless accuracy without sacrificing serving efficiency.