arXiv: 2604.19124 · PDF
Authors: Wei Shao, Yihang Wang, Gaoyu Zhu, Ziqiang Cheng, Lei Yu, Jiafeng Guo, Xueqi Cheng
Primary category: cs.CL · all: cs.CL
Matched keywords: large language model, llm, inference, serving, fine-tun, post-train
TL;DR
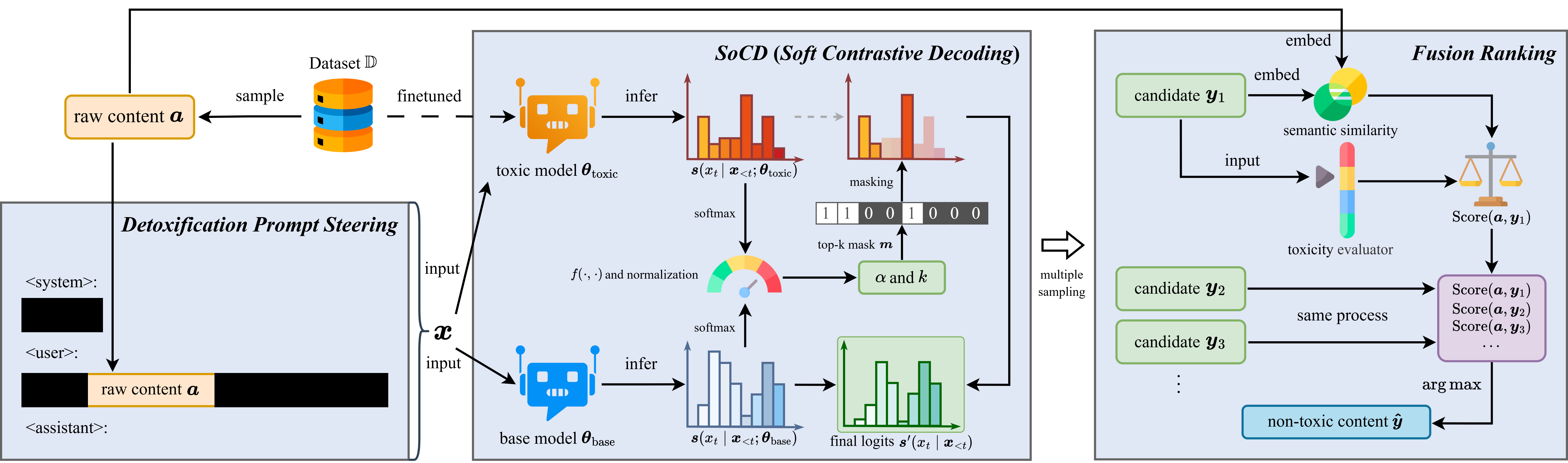
The paper proposes HSPD, a pipeline that detoxifies LLM pretraining corpora at the source by rewriting toxic spans with a Soft Contrastive Decoding (SoCD) method, yielding a drop-in replacement dataset that cuts downstream model toxicity while preserving semantics.
Key Ideas
- Tackle toxicity at the dataset level rather than via post-training alignment or decoding-time filters.
- Introduce SoCD (Soft Contrastive Decoding) to localize and rewrite toxic spans.
- Wrap it in HSPD (Hierarchical Semantic-Preserving Detoxification) pipeline producing a reusable detoxified corpus.
- The cleaned corpus is a drop-in replacement for fine-tuning or pretraining.
Approach
HSPD operates hierarchically on raw text: detect toxic spans, then use SoCD — a contrastive decoding variant that softly biases generation away from a toxic reference distribution while anchored to the original semantics — to rewrite just those spans. The rest of the document is preserved, yielding a corpus-level detox without full regeneration.
Experiments
- Models: GPT2-XL, LLaMA2-7B, OPT-6.7B, Falcon-7B.
- Metrics: Toxicity Probability (TP), Expected Maximum Toxicity (EMT).
- Baselines: implicit comparison against post-training / controllable-decoding detox methods (specific names not stated in abstract).
Results
- GPT2-XL: TP 0.42 → 0.18, EMT 0.43 → 0.20 — claimed SOTA.
- Consistent “best-in-class” improvements on LLaMA2-7B, OPT-6.7B, Falcon-7B (exact numbers not in abstract).
- Claims utility retention, but the abstract does not quantify perplexity or downstream task scores.
Why It Matters
Shifts detox responsibility upstream to the data layer, offering a reusable clean corpus that downstream teams can adopt without per-model alignment overhead. For AI-infra practitioners, it suggests a pipeline stage between crawl and pretrain that can reduce later RLHF/guardrail cost.
Connections to Prior Work
- Contrastive Decoding (Li et al.) and DExperts-style controllable generation.
- Post-training detox: RLHF, DPO, self-debiasing.
- Inference-time filters: PPLM, GeDi.
- Data-centric safety work: C4 filtering, PaLM data curation, toxicity classifiers on CommonCrawl.
Open Questions
- How much utility (perplexity, knowledge benchmarks) is lost after rewriting?
- Does SoCD introduce semantic drift or factual errors in sensitive spans?
- Scalability: cost of rewriting web-scale corpora vs. filtering.
- Robustness across languages and subtle/implicit toxicity (not just overt slurs).
- Interaction with downstream RLHF — is it additive or redundant?
- The arXiv ID “2604.19124” looks anomalous; provenance worth verifying.
Figures
Figure 1: Figure 1 (extracted from PDF)
Original abstract
Existing detoxification methods for large language models mainly focus on post-training stage or inference time, while few tackle the source of toxicity, namely, the dataset itself. Such training-based or controllable decoding approaches cannot completely suppress the model’s inherent toxicity, whereas detoxifying the pretraining dataset can fundamentally reduce the toxicity that the model learns during training. Hence, we attempt to detoxify directly on raw corpora with SoCD (Soft Contrastive Decoding), which guides an LLM to localize and rewrite toxic spans in raw data while preserving semantics, in our proposed HSPD (Hierarchical Semantic-Preserving Detoxification) pipeline, yielding a detoxified corpus that can drop-in replace the original for fine-tuning or other training. On GPT2-XL, HSPD attains state-of-the-art detoxification, reducing Toxicity Probability (TP) from 0.42 to 0.18 and Expected Maximum Toxicity (EMT) from 0.43 to 0.20. We further validate consistent best-in-class results on LLaMA2-7B, OPT-6.7B, and Falcon-7B. These findings show that semantics-preserving, corpus-level rewriting with HSPD effectively suppresses downstream toxicity while retaining data utility and allowing seamless source-level mitigation, thereby reducing the cost of later model behavior adjustment. (Code is available at: https://github.com/ntsw2001/data_detox_for_llm)