arXiv: 2604.19124 · PDF
作者: Wei Shao, Yihang Wang, Gaoyu Zhu, Ziqiang Cheng, Lei Yu, Jiafeng Guo, Xueqi Cheng
主分类: cs.CL · 全部: cs.CL
命中关键词: large language model, llm, inference, serving, fine-tun, post-train
TL;DR
提出 HSPD pipeline + SoCD 解码,直接在预训练语料层面改写有毒片段,从源头降低 LLM 毒性,同时保留语义与数据可用性。
核心观点
- 现有去毒方法聚焦 post-training 或 inference-time,难以根除模型内在毒性
- 毒性真正的源头是数据集本身,应在 corpus 层面做治理
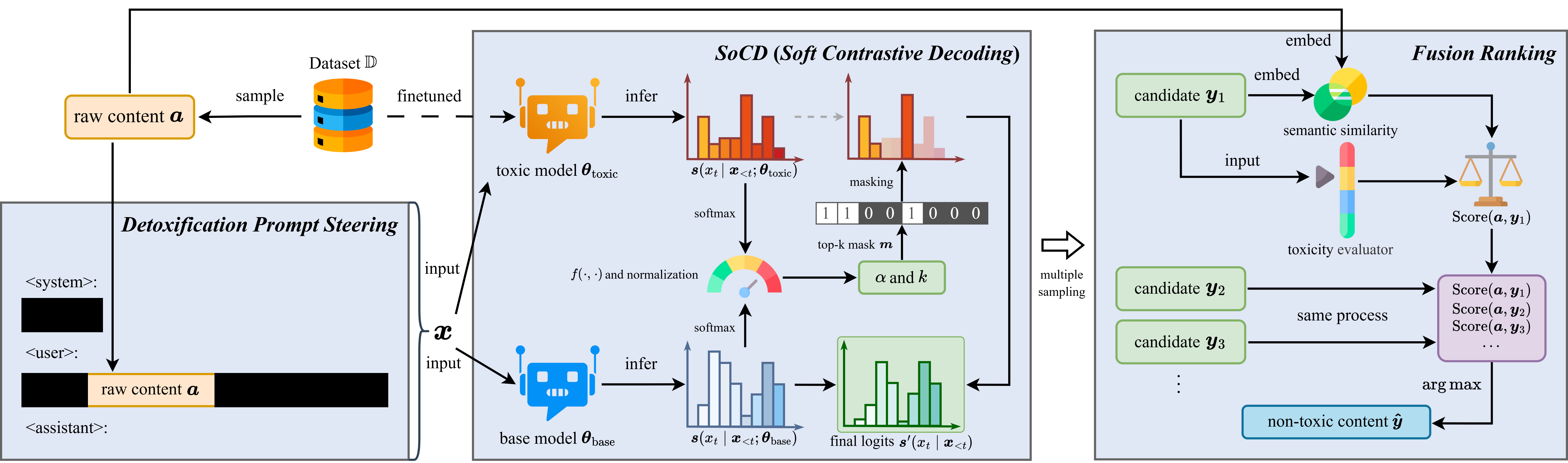
- 提出 HSPD(Hierarchical Semantic-Preserving Detoxification)pipeline,输出可直接替换原始语料用于 fine-tuning
- 引入 SoCD(Soft Contrastive Decoding),引导 LLM 定位并重写毒性片段,保留语义
- 在多种主流 LLM 上取得 SOTA 去毒效果
方法
- HSPD 是一个分层、语义保持的 corpus-level 去毒 pipeline
- 核心解码机制 SoCD:对原始语料中的毒性 span 做定位与改写,而非简单删除或屏蔽
- 通过对比解码抑制毒性表达、保持语义一致,产出 drop-in 替换的去毒语料
- 下游训练流程(fine-tuning 等)不需修改,仅更换训练数据
实验
- 模型:GPT2-XL、LLaMA2-7B、OPT-6.7B、Falcon-7B
- 指标:Toxicity Probability (TP)、Expected Maximum Toxicity (EMT)
- 基线:摘要未具体列出,仅声称对比主流 detox 方法取得 best-in-class
- 代码开源:github.com/ntsw2001/data_detox_for_llm
结果
- GPT2-XL:TP 0.42 → 0.18,EMT 0.43 → 0.20
- LLaMA2-7B / OPT-6.7B / Falcon-7B 上也报告一致的 best-in-class 结果
- 声称在降低毒性的同时保留数据效用(utility),但摘要未给出 utility 的量化数字
为什么重要
- 将 detox 从推理期/后训练迁移到数据源头,是一种更根本的治理路径
- 产出的去毒语料可直接替换原始数据,不改训练代码,落地成本低
- 为安全对齐团队提供"数据层防线",可减少后续 RLHF / 解码端修补负担
与已有工作的关系
- 相对 DAPT、Self-Debias、GeDi、DExperts 等 post-training / controllable decoding 方法,把干预点前移
- 延续 contrastive decoding 思路,但将其从生成控制用于 corpus 改写
- 与数据清洗/过滤式 detox(如 RealToxicityPrompts 过滤)相比,采用改写而非丢弃以保留 utility
尚未回答的问题
- utility 损失的具体量化(perplexity、下游任务精度)未在摘要中给出
- SoCD 改写是否引入新的 bias 或事实性错误
- 对超大规模预训练语料(trillion tokens)的可扩展性与算力开销
- 在多语言 / 多毒性类型(仇恨、性别、政治)上的泛化性
- 与 RLHF、constitutional AI 等对齐手段的叠加收益
论文图表
图 1: Figure 1 (extracted from PDF)
原始摘要
Existing detoxification methods for large language models mainly focus on post-training stage or inference time, while few tackle the source of toxicity, namely, the dataset itself. Such training-based or controllable decoding approaches cannot completely suppress the model’s inherent toxicity, whereas detoxifying the pretraining dataset can fundamentally reduce the toxicity that the model learns during training. Hence, we attempt to detoxify directly on raw corpora with SoCD (Soft Contrastive Decoding), which guides an LLM to localize and rewrite toxic spans in raw data while preserving semantics, in our proposed HSPD (Hierarchical Semantic-Preserving Detoxification) pipeline, yielding a detoxified corpus that can drop-in replace the original for fine-tuning or other training. On GPT2-XL, HSPD attains state-of-the-art detoxification, reducing Toxicity Probability (TP) from 0.42 to 0.18 and Expected Maximum Toxicity (EMT) from 0.43 to 0.20. We further validate consistent best-in-class results on LLaMA2-7B, OPT-6.7B, and Falcon-7B. These findings show that semantics-preserving, corpus-level rewriting with HSPD effectively suppresses downstream toxicity while retaining data utility and allowing seamless source-level mitigation, thereby reducing the cost of later model behavior adjustment. (Code is available at: https://github.com/ntsw2001/data_detox_for_llm)