arXiv: 2604.19533 · PDF
Authors: Alankrit Chona, Igor Kozlov, Ambuj Kumar
Primary category: cs.CR · all: cs.AI, cs.CR
Matched keywords: large language model, llm, agent, agentic, rag
TL;DR
Cyber Defense Benchmark evaluates LLM agents on open-ended threat hunting over raw Windows logs via iterative SQL queries. Across five frontier models, all fail dramatically — the best (Claude Opus 4.6) flags only 3.8% of malicious events, and none meet the >=50% per-tactic recall bar for unsupervised SOC deployment.
Key Ideas
- Benchmarks unguided threat hunting, not curated Q&A security tasks.
- Wraps 106 real attack procedures (86 MITRE ATT&CK sub-techniques, 12 tactics) from OTRF Security-Datasets into a Gymnasium RL env.
- Uses a deterministic campaign simulator with time-shift and entity obfuscation to prevent memorization.
- CTF-style scoring against Sigma-rule-derived ground truth on exact malicious timestamps.
Approach
Each episode loads an in-memory SQLite DB of 75k–135k Windows event log records. The agent iteratively issues SQL queries and explicitly submits flags for timestamps it believes are malicious. Scoring compares submitted timestamps to Sigma-rule ground truth; “passing” requires >=50% recall on every ATT&CK tactic — the authors’ threshold for unsupervised SOC use.
Experiments
- Models: Claude Opus 4.6, GPT-5, Gemini 3.1 Pro, Kimi K2.5, Gemini 3 Flash.
- 26 campaigns covering 105 of 106 procedures.
- Metric: recall of correctly flagged malicious timestamps, reported overall and per-tactic.
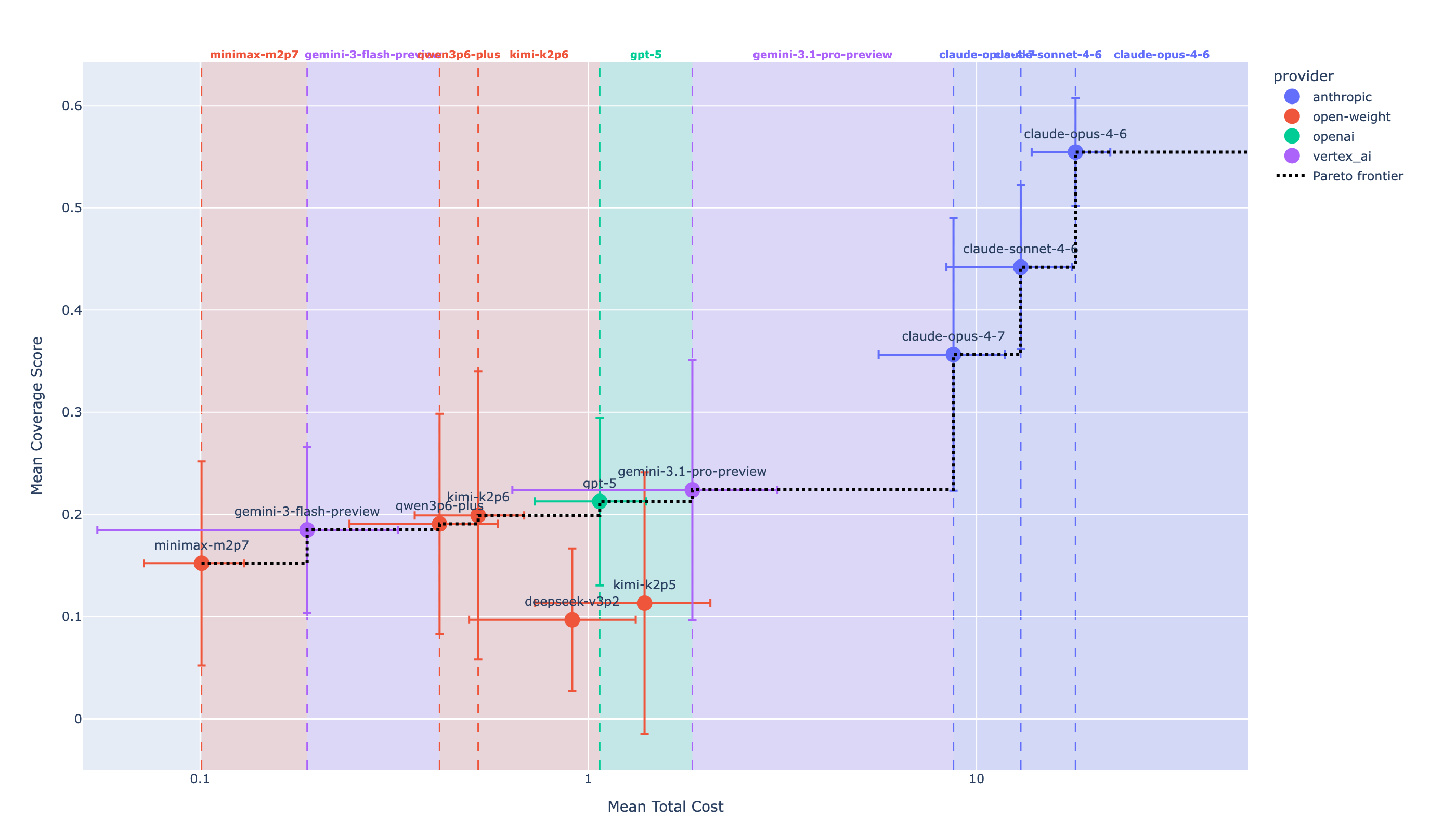
Results
- Best model (Claude Opus 4.6): 3.8% average correct-flag rate.
- No run from any model found all flags in any campaign.
- No model passes the 50%-per-tactic bar; leader clears it on 5/13 tactics, remaining four models on 0 tactics.
Why It Matters
Shows that strong scores on curated security Q&A benchmarks don’t transfer to realistic, evidence-driven SOC work over raw telemetry. For agent/infra practitioners, it sets a concrete, RL-style environment for measuring progress on long-horizon SQL-driven investigation, and flags that current frontier LLMs are not ready for unsupervised threat-hunting deployment.
Connections to Prior Work
- MITRE ATT&CK taxonomy and Sigma detection rules for ground truth.
- OTRF Security-Datasets as attack-telemetry corpus.
- Prior cyber LLM benchmarks (e.g., CyberSecEval, CTIBench, SecBench-style Q&A) — this work contrasts with their curated, hint-rich formats.
- Gymnasium / agentic-RL evaluation harnesses and tool-use agent benchmarks (SWE-bench, τ-bench).
Open Questions
- Do specialized SOC fine-tunes, retrieval over Sigma/ATT&CK, or multi-agent decompositions close the gap?
- How much of the failure is query-strategy vs. log-schema comprehension vs. context-length limits on 100k+ records?
- Would giving hints (scoped time windows, suspected entities) raise recall enough for supervised triage?
- Robustness: how sensitive are scores to the obfuscation/time-shift parameters and to non-Windows telemetry?
Figures
Figure 1: Figure 1 (extracted from PDF)
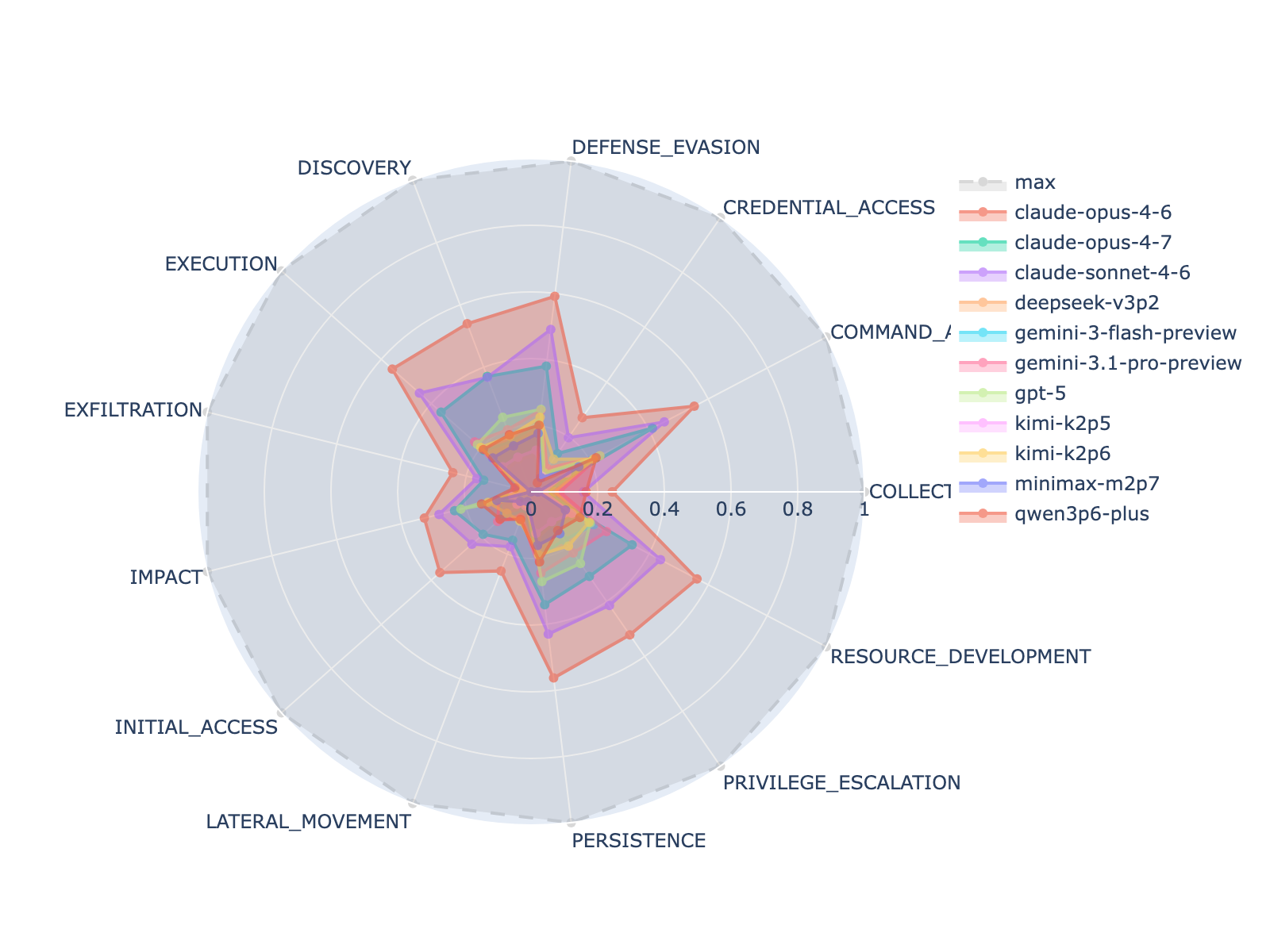
Figure 2: Figure 2 (extracted from PDF)
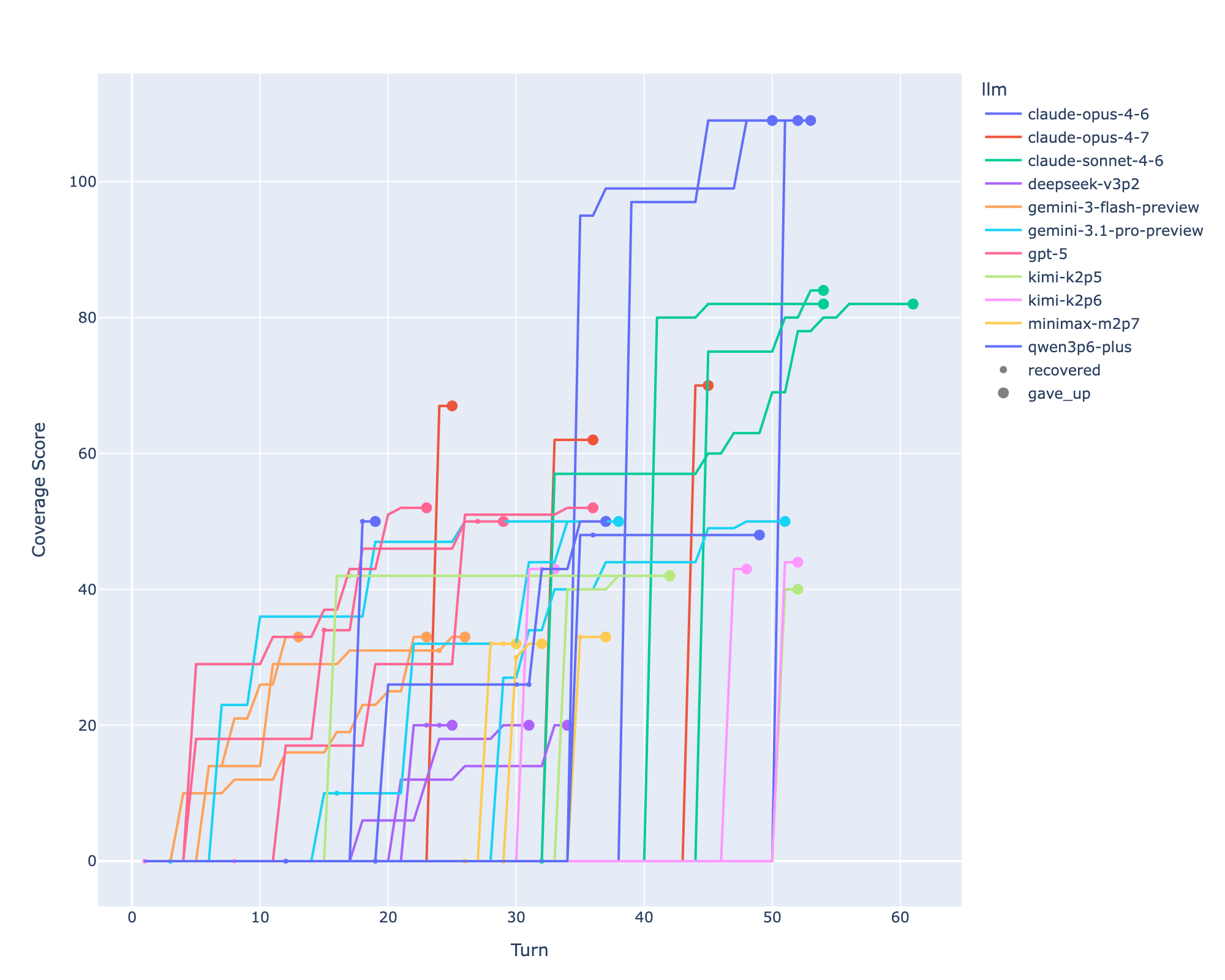
Figure 3: Figure 3 (extracted from PDF)
Original abstract
We introduce the Cyber Defense Benchmark, a benchmark for measuring how well large language model (LLM) agents perform the core SOC analyst task of threat hunting: given a database of raw Windows event logs with no guided questions or hints, identify the exact timestamps of malicious events. The benchmark wraps 106 real attack procedures from the OTRF Security-Datasets corpus - spanning 86 MITRE ATT&CK sub-techniques across 12 tactics - into a Gymnasium reinforcement-learning environment. Each episode presents the agent with an in-memory SQLite database of 75,000-135,000 log records produced by a deterministic campaign simulator that time-shifts and entity-obfuscates the raw recordings. The agent must iteratively submit SQL queries to discover malicious event timestamps and explicitly flag them, scored CTF-style against Sigma-rule-derived ground truth. Evaluating five frontier models - Claude Opus 4.6, GPT-5, Gemini 3.1 Pro, Kimi K2.5, and Gemini 3 Flash - on 26 campaigns covering 105 of 106 procedures, we find that all models fail dramatically: the best model (Claude Opus 4.6) submits correct flags for only 3.8% of malicious events on average, and no run across any model ever finds all flags. We define a passing score as >= 50% recall on every ATT&CK tactic - the minimum bar for unsupervised SOC deployment. No model passes: the leader clears this bar on 5 of 13 tactics and the remaining four on zero. These results suggest that current LLMs are poorly suited for open-ended, evidence-driven threat hunting despite strong performance on curated Q&A security benchmarks.