arXiv: 2604.19533 · PDF
作者: Alankrit Chona, Igor Kozlov, Ambuj Kumar
主分类: cs.CR · 全部: cs.AI, cs.CR
命中关键词: large language model, llm, agent, agentic, rag
TL;DR
提出 Cyber Defense Benchmark,用 106 条真实攻击、75k–135k 条 Windows 日志的 SQLite 环境让 LLM agent 做无提示威胁狩猎;五大前沿模型最高召回仅 3.8%,全部不及格。
核心观点
- 首个面向 SOC 威胁狩猎核心任务的 agentic benchmark,强调无引导问题、纯证据驱动。
- 将 OTRF Security-Datasets 的 106 个攻击程序打包进 Gymnasium RL 环境,CTF 式评分。
- 结论鲜明:当前 frontier LLM 在开放式威胁狩猎上尚不可用,Q&A 榜单成绩具有误导性。
方法
- 数据基于 OTRF Security-Datasets,覆盖 MITRE ATT&CK 12 tactics、86 sub-techniques。
- 用确定性 campaign simulator 对原始日志做时间平移和实体混淆,得到每集 75k–135k 条的 in-memory SQLite 库。
- Agent 通过迭代提交 SQL 查询检索恶意事件,并显式 flag 时间戳;ground truth 来自 Sigma 规则。
- 包装成 Gymnasium RL 环境,支持标准化评测与 CTF 式打分。
实验
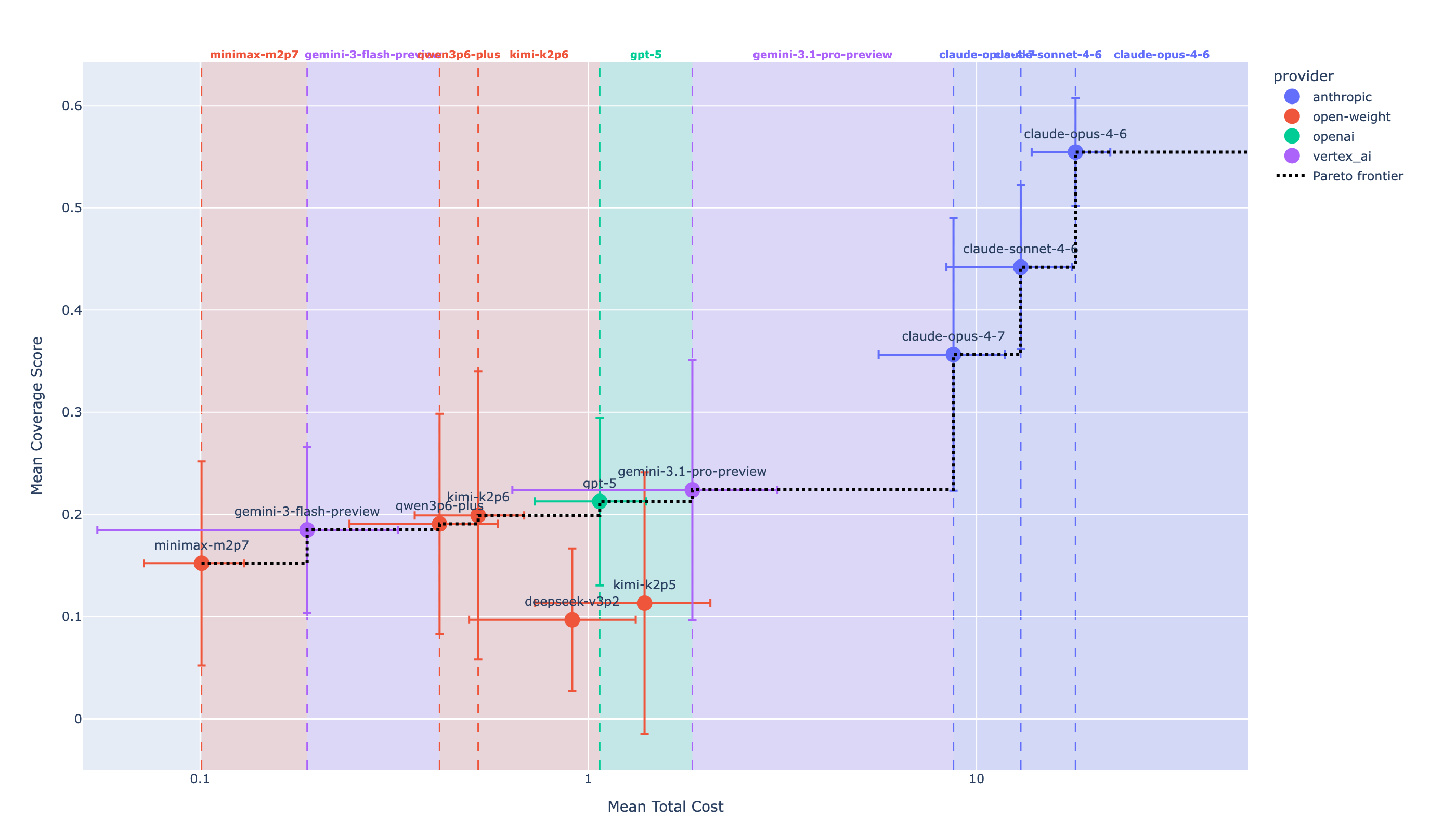
- 评测 5 个 frontier 模型:Claude Opus 4.6、GPT-5、Gemini 3.1 Pro、Kimi K2.5、Gemini 3 Flash。
- 跑 26 个 campaigns,覆盖 106 个 procedures 中的 105 个。
- 指标:每个恶意事件的 flag 正确率;通过标准为每个 ATT&CK tactic 召回 ≥ 50%。
结果
- 最强模型 Claude Opus 4.6 平均只 flag 出 3.8% 的恶意事件。
- 没有任何一次运行找全所有 flag。
- 通过线(13 tactics 全部 ≥50%)无模型达成;leader 仅在 5/13 tactics 达标,其余四个模型 0/13。
为什么重要
- 给 SecOps / agent 基础设施从业者一个真实、可复现的 RL-style 评测,而非多选题。
- 揭示 frontier LLM 在长上下文、多轮 SQL 证据检索和 ATT&CK 覆盖上的系统性短板。
- 为 tool-use、memory、planning、RL 微调等方向提供明确 target 和 headroom。
与已有工作的关系
- 延续 MITRE ATT&CK、Sigma rules、OTRF Security-Datasets 的威胁检测脉络。
- 对比已有 curated 安全 Q&A benchmark(如 CyberSecEval、SecQA 类),强调 agentic、open-ended 设定。
- 借鉴 Gymnasium / CTF-style agent benchmark(SWE-bench、Cybench 等)的评测范式。
尚未回答的问题
- 给予工具增强(SIEM、检测库、RAG、notebook)或 fine-tuning 后表现能否质变?
- 失败主因是 SQL 推理、长上下文,还是 ATT&CK 先验知识不足?
- 能否扩展到 Linux、网络流、云日志等非 Windows 数据源?
- 如何防止 benchmark 被训练集污染,保持长期可用?
论文图表
图 1: Figure 1 (extracted from PDF)
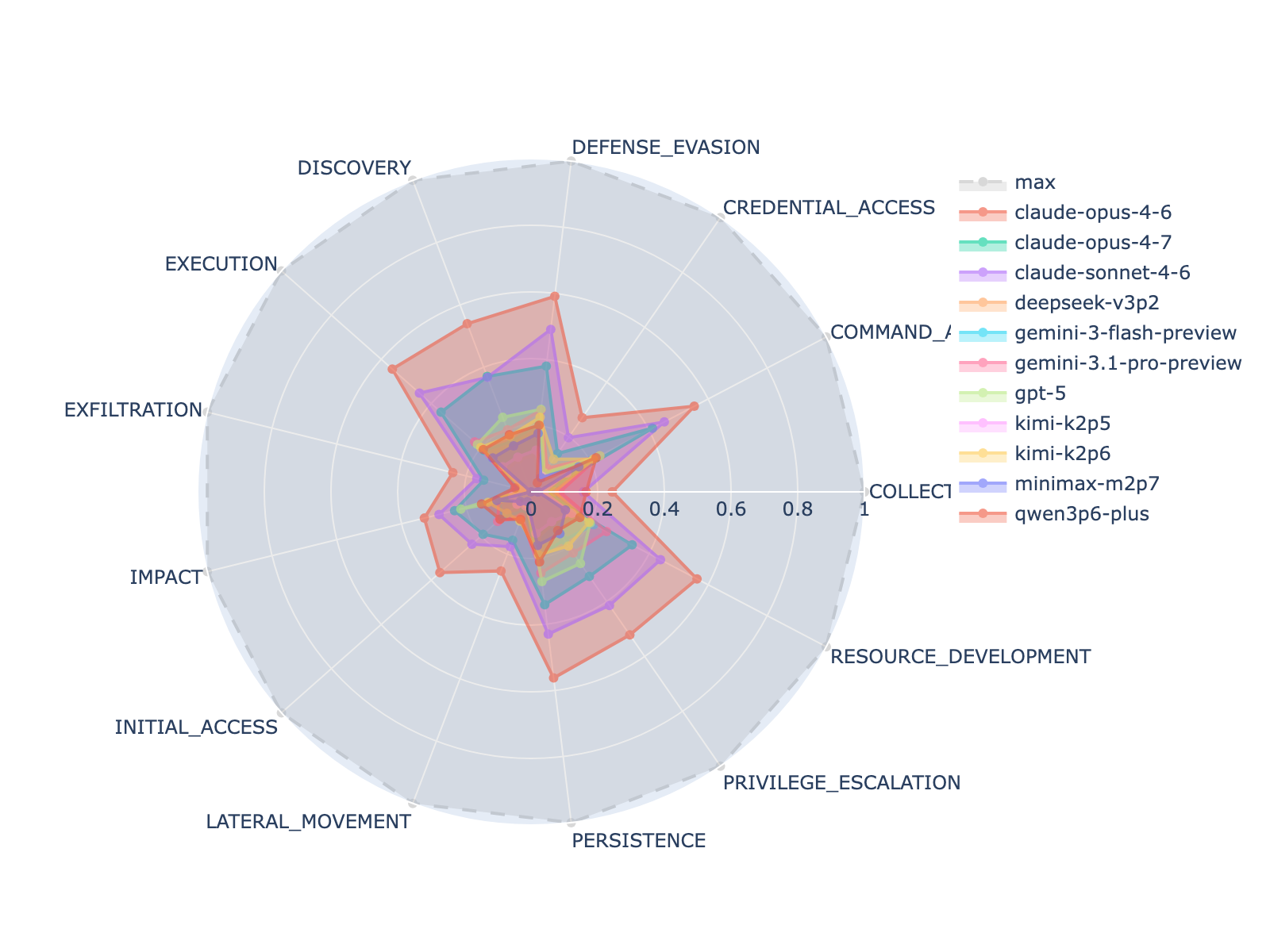
图 2: Figure 2 (extracted from PDF)
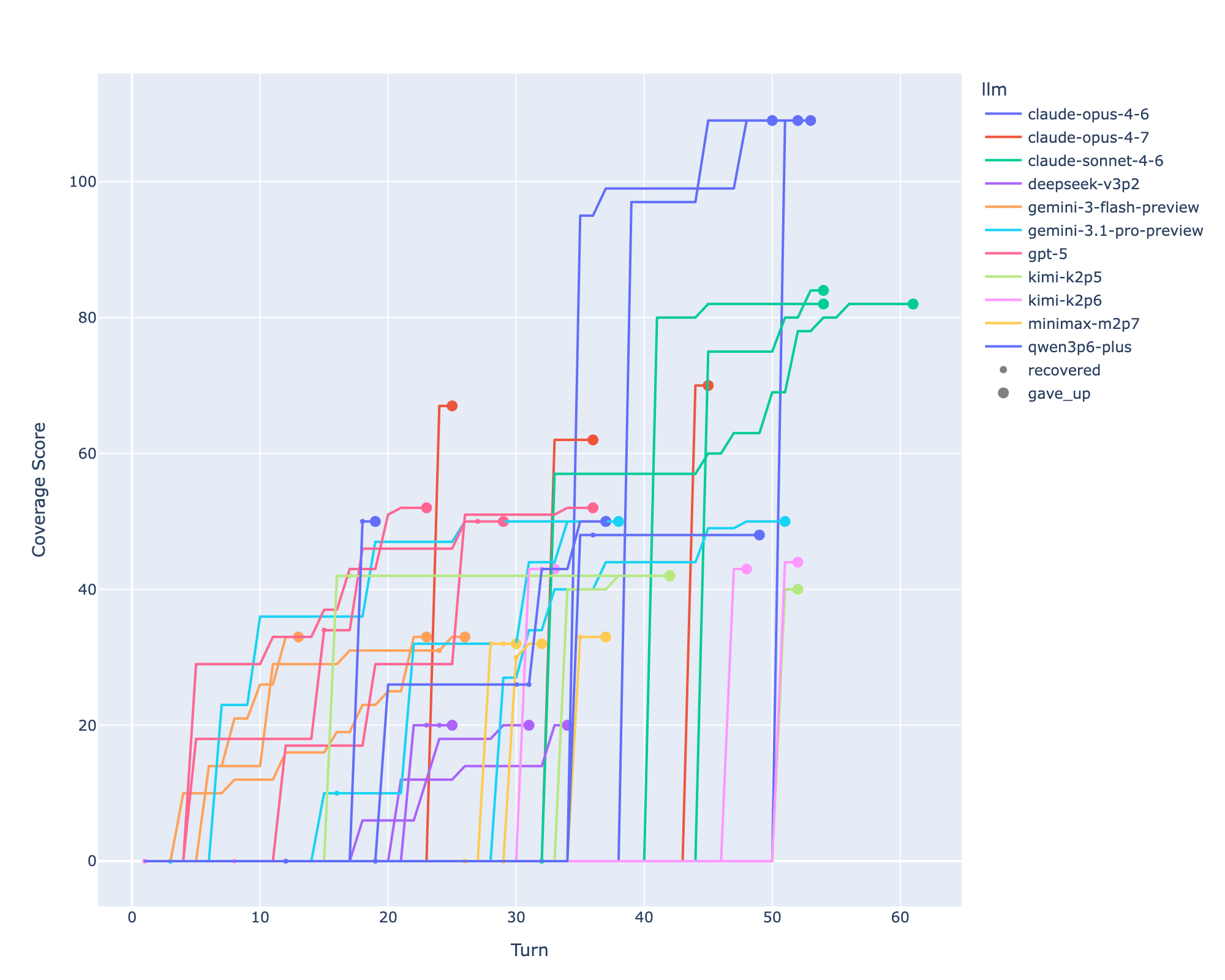
图 3: Figure 3 (extracted from PDF)
原始摘要
We introduce the Cyber Defense Benchmark, a benchmark for measuring how well large language model (LLM) agents perform the core SOC analyst task of threat hunting: given a database of raw Windows event logs with no guided questions or hints, identify the exact timestamps of malicious events. The benchmark wraps 106 real attack procedures from the OTRF Security-Datasets corpus - spanning 86 MITRE ATT&CK sub-techniques across 12 tactics - into a Gymnasium reinforcement-learning environment. Each episode presents the agent with an in-memory SQLite database of 75,000-135,000 log records produced by a deterministic campaign simulator that time-shifts and entity-obfuscates the raw recordings. The agent must iteratively submit SQL queries to discover malicious event timestamps and explicitly flag them, scored CTF-style against Sigma-rule-derived ground truth. Evaluating five frontier models - Claude Opus 4.6, GPT-5, Gemini 3.1 Pro, Kimi K2.5, and Gemini 3 Flash - on 26 campaigns covering 105 of 106 procedures, we find that all models fail dramatically: the best model (Claude Opus 4.6) submits correct flags for only 3.8% of malicious events on average, and no run across any model ever finds all flags. We define a passing score as >= 50% recall on every ATT&CK tactic - the minimum bar for unsupervised SOC deployment. No model passes: the leader clears this bar on 5 of 13 tactics and the remaining four on zero. These results suggest that current LLMs are poorly suited for open-ended, evidence-driven threat hunting despite strong performance on curated Q&A security benchmarks.