arXiv: 2604.20146 · PDF
Authors: Jielong Tang, Xujie Yuan, Jiayang Liu, Jianxing Yu, Xiao Dong, Lin Chen, Yunlai Teng, Shimin Di, Jian Yin
Primary category: cs.IR · all: cs.CL, cs.IR
Matched keywords: large language model, llm, agent, agentic, tool-use, retrieval, reasoning, chain-of-thought, serving, fine-tun
TL;DR
SAKE is an end-to-end agentic framework for Grounded Multimodal Named Entity Recognition (GMNER) that blends internal MLLM knowledge with external retrieval via self-aware reasoning, deciding when to invoke search tools to handle long-tailed and unseen entities on social media.
Key Ideas
- Harmonize internal knowledge exploitation and external knowledge exploration through a single agentic policy.
- Quantify entity-level uncertainty via multiple forward samplings to produce explicit knowledge-gap signals.
- Train the model to decide when retrieval is truly necessary, rather than always or never searching.
- Penalize unnecessary retrieval through a hybrid RL reward, reducing noise from heuristic search.
Approach
Two-stage training pipeline:
- Difficulty-aware Search Tag Generation: multi-sample forward passes estimate per-entity uncertainty; these signals label when a search is needed.
- SAKE-SeCoT dataset + SFT: a curated Chain-of-Thought corpus instills self-awareness and tool-use behavior.
- Agentic RL: hybrid reward balances recognition/grounding accuracy against a penalty for superfluous retrieval, pushing the model from imitation to genuine decision-making about tool invocation.
Experiments
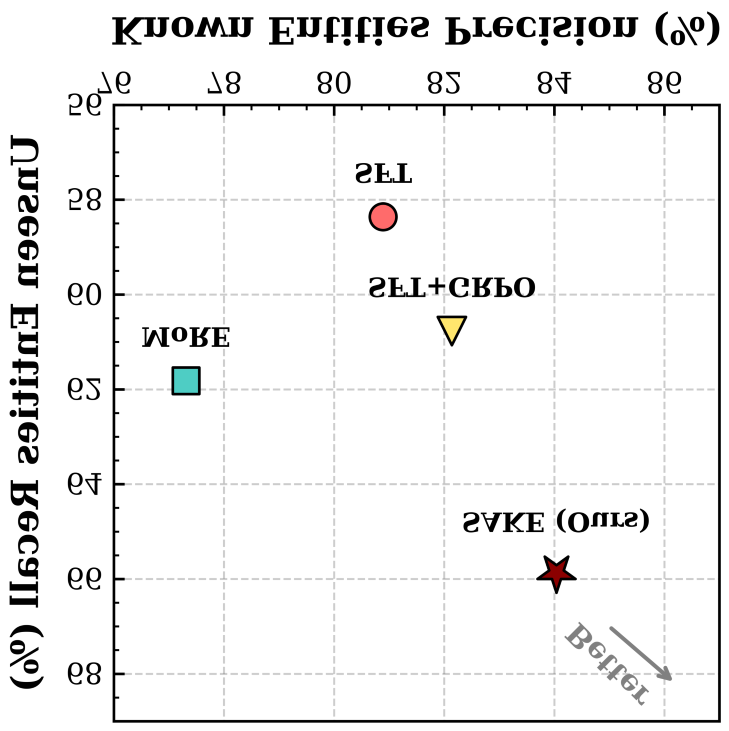
Two widely used social media GMNER benchmarks (unnamed in abstract, likely Twitter-GMNER variants). Baselines and metrics are not specified in the abstract; presumably standard GMNER precision/recall/F1 for entity typing and visual grounding.
Results
Abstract only states “extensive experiments demonstrate SAKE’s effectiveness”—no concrete numbers or ablations are disclosed. Claims cannot be independently verified from the abstract.
Why It Matters
Shows a practical recipe for training MLLM agents to selectively invoke retrieval, a recurring pain point in RAG-style and tool-using agents. The uncertainty-driven “when to search” signal and retrieval-cost-aware RL reward are transferable beyond GMNER to any agentic LLM workflow where over-retrieval hurts precision.
Connections to Prior Work
- GMNER lineage (Yu et al.’s Twitter-GMNER benchmark, grounded entity extraction).
- Retrieval-augmented MLLMs and heuristic external-knowledge approaches.
- Self-refinement / iterative reasoning in MLLMs (constrained by knowledge boundaries, prone to hallucination).
- Agentic RL for tool use: ReAct, Toolformer, and recent RLHF/GRPO-style tool-invocation training.
- Uncertainty-driven retrieval (e.g., FLARE, self-RAG).
Open Questions
- Which benchmarks, baselines, and metrics—and how large are the gains?
- How robust is the uncertainty signal from forward sampling across MLLM scales?
- Does the retrieval-penalty reward overfit to benchmark distributions and hurt recall on truly unseen entities?
- Cost/latency trade-off of multi-sample uncertainty estimation at inference.
- Generalization beyond social media (news, e-commerce, scientific imagery).
Figures
Figure 1: Figure 1 (extracted from PDF)
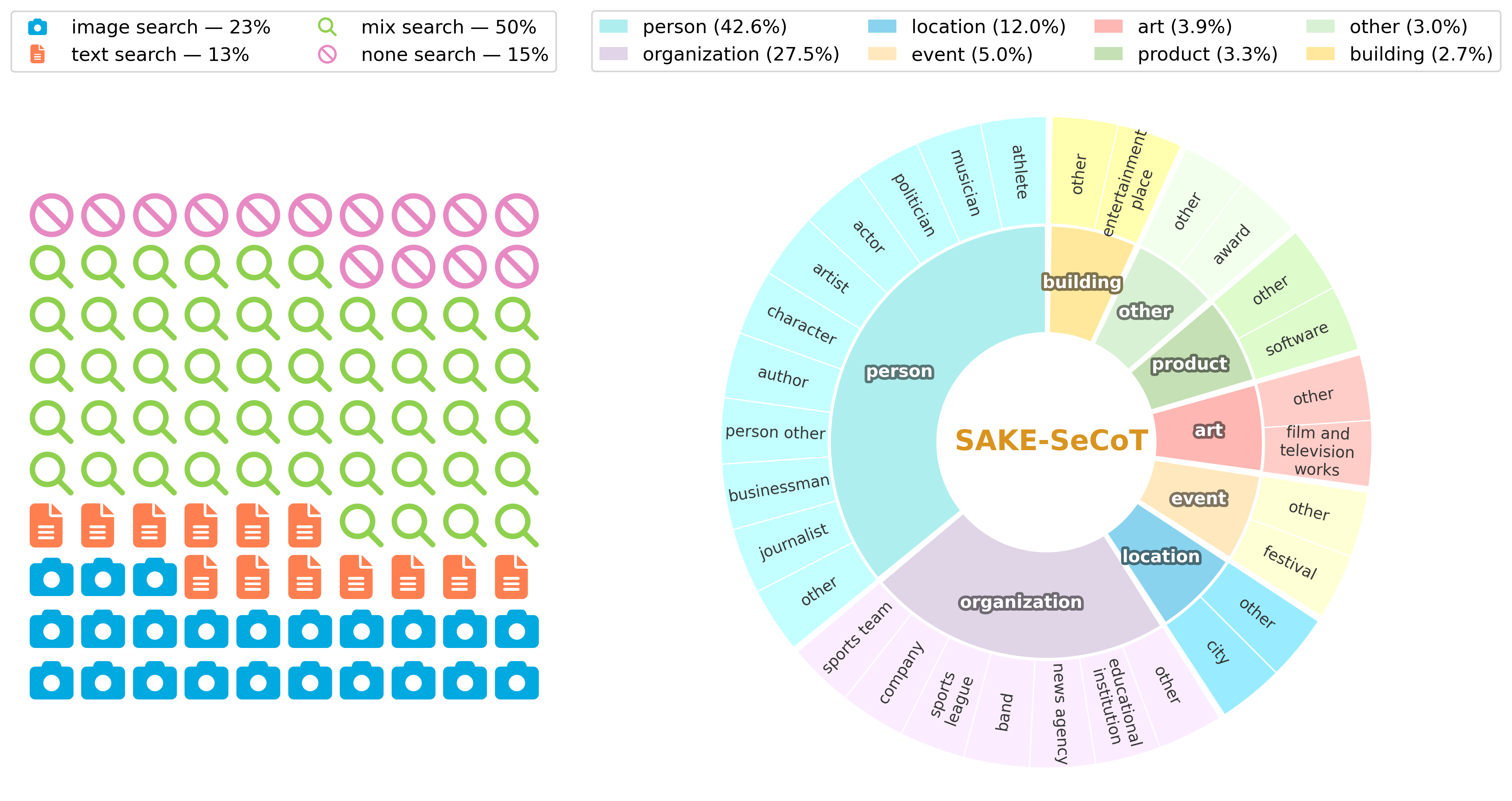
Figure 2: Figure 2 (extracted from PDF)
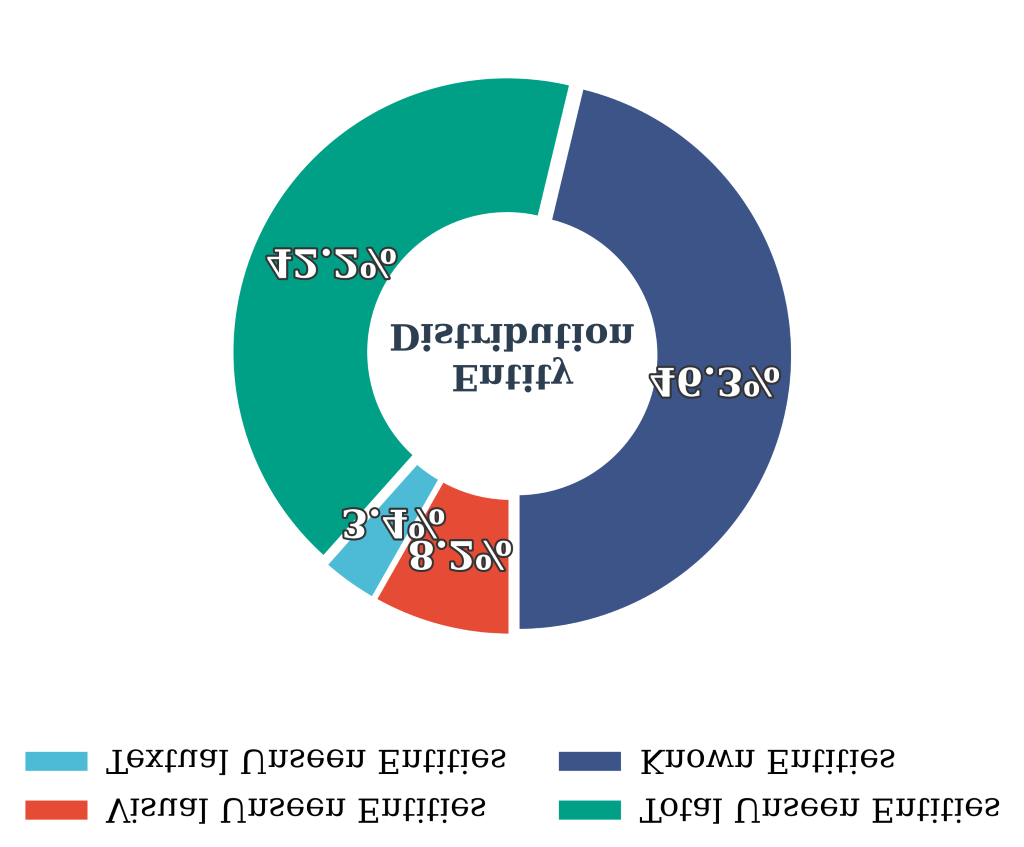
Figure 3: Figure 3 (extracted from PDF)
Original abstract
Grounded Multimodal Named Entity Recognition (GMNER) aims to extract named entities and localize their visual regions within image-text pairs, serving as a pivotal capability for various downstream applications. In open-world social media platforms, GMNER remains challenging due to the prevalence of long-tailed, rapidly evolving, and unseen entities. To tackle this, existing approaches typically rely on either external knowledge exploration through heuristic retrieval or internal knowledge exploitation via iterative refinement in Multimodal Large Language Models (MLLMs). However, heuristic retrieval often introduces noisy or conflicting evidence that degrades precision on known entities, while solely internal exploitation is constrained by the knowledge boundaries of MLLMs and prone to hallucinations. To address this, we propose SAKE, an end-to-end agentic framework that harmonizes internal knowledge exploitation and external knowledge exploration via self-aware reasoning and adaptive search tool invocation. We implement this via a two-stage training paradigm. First, we propose Difficulty-aware Search Tag Generation, which quantifies the model’s entity-level uncertainty through multiple forward samplings to produce explicit knowledge-gap signals. Based on these signals, we construct SAKE-SeCoT, a high-quality Chain-of-Thought dataset that equips the model with basic self-awareness and tool-use capabilities through supervised fine-tuning. Second, we employ agentic reinforcement learning with a hybrid reward function that penalizes unnecessary retrieval, enabling the model to evolve from rigid search imitation to genuine self-aware decision-making about when retrieval is truly necessary. Extensive experiments on two widely used social media benchmarks demonstrate SAKE’s effectiveness.