arXiv: 2604.20146 · PDF
作者: Jielong Tang, Xujie Yuan, Jiayang Liu, Jianxing Yu, Xiao Dong, Lin Chen, Yunlai Teng, Shimin Di, Jian Yin
主分类: cs.IR · 全部: cs.CL, cs.IR
命中关键词: large language model, llm, agent, agentic, tool-use, retrieval, reasoning, chain-of-thought, serving, fine-tun
TL;DR
SAKE 是一个端到端 agentic 框架,通过自我感知推理与自适应检索工具调用,在 Grounded Multimodal NER 任务上协调 MLLM 的内部知识利用与外部知识探索。
核心观点
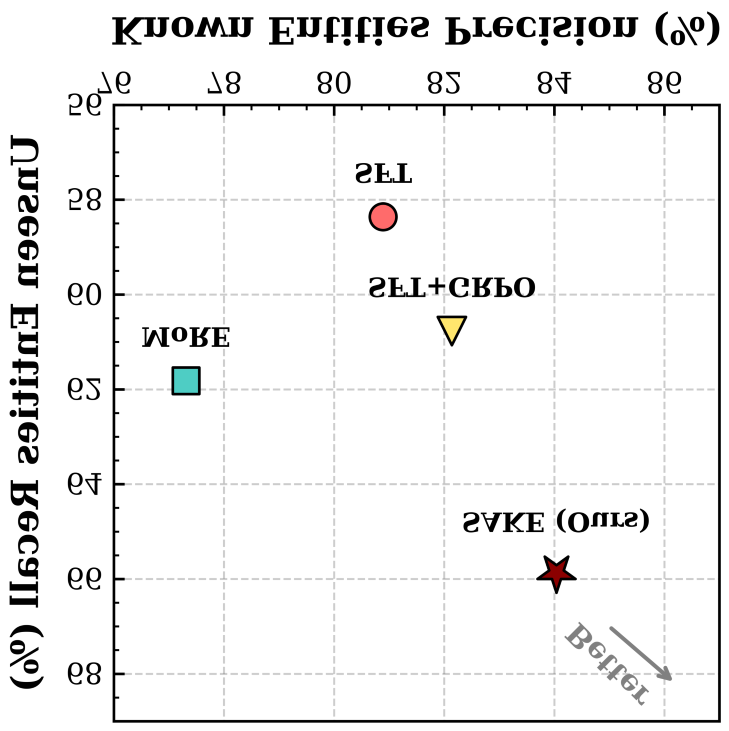
- 纯启发式外部检索会引入噪声与冲突证据,损害已知实体精度;而纯内部迭代又受 MLLM 知识边界限制、易幻觉。
- 提出"自我感知"范式:让模型自己判断何时需要检索,从而融合 exploitation 与 exploration。
- 通过两阶段训练(SFT + agentic RL)把这种能力落地。
方法
- Difficulty-aware Search Tag Generation:通过多次 forward 采样量化实体级不确定性,生成显式的知识缺口信号。
- SAKE-SeCoT 数据集:基于上述信号构建高质量 CoT 数据,SFT 阶段教会模型基础的自我感知与工具调用能力。
- Agentic RL:混合奖励函数惩罚"不必要的检索",推动模型从机械模仿搜索行为进化为真正基于需求的自我感知决策。
实验
- 数据集:两个主流社交媒体 GMNER benchmark(摘要未点名,通常指 Twitter-GMNER 等)。
- 基线与指标:摘要未给出具体基线与数值指标。
结果
摘要仅声称"extensive experiments … demonstrate SAKE’s effectiveness",未披露具体数字,无法独立核验其增幅幅度。
为什么重要
为 multimodal agent 提供了一种"按需检索"的训练配方:用不确定性信号驱动工具调用,用 RL 惩罚冗余检索。这对构建更节省、更少幻觉的 retrieval-augmented multimodal agent 有直接借鉴价值。
与已有工作的关系
- 延续 GMNER 任务线(Twitter-GMNER 等社交媒体实体识别)。
- 与 MLLM 自我反思 / iterative refinement 方法(如 self-refine 类)对比。
- 与 retrieval-augmented MLLM、tool-use agent(ReAct、Toolformer)和 agentic RL(RLHF-for-tools)思路衔接。
尚未回答的问题
- 具体 benchmark 指标与相对提升幅度多少?
- 混合奖励中各项权重如何敏感?
- 在长尾 / 未见实体上的 localization 精度是否同步提升?
- 检索延迟与调用频率的实际开销?
- 能否迁移到 GMNER 之外的 multimodal agent 任务(VQA、grounding 等)?
论文图表
图 1: Figure 1 (extracted from PDF)
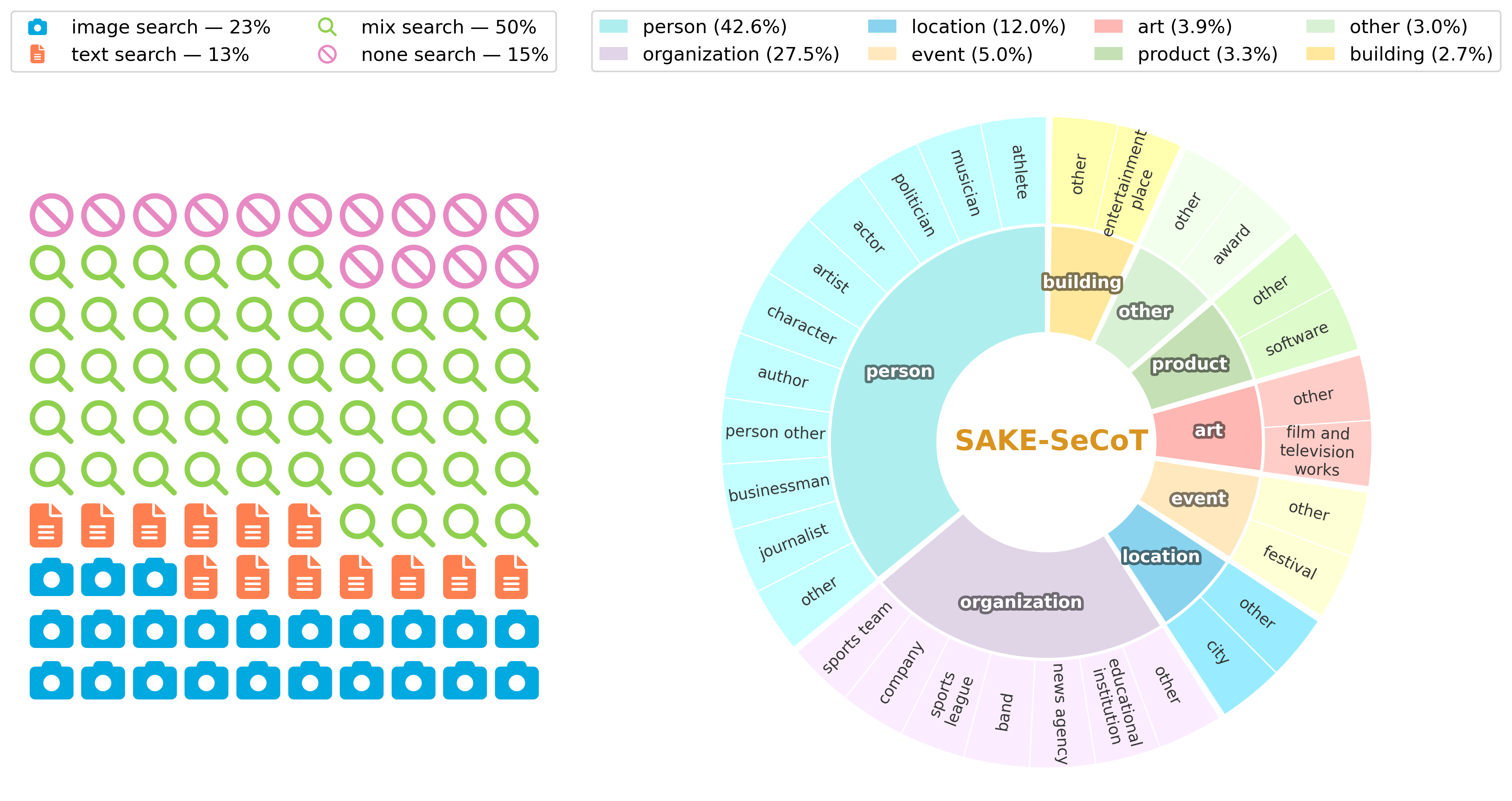
图 2: Figure 2 (extracted from PDF)
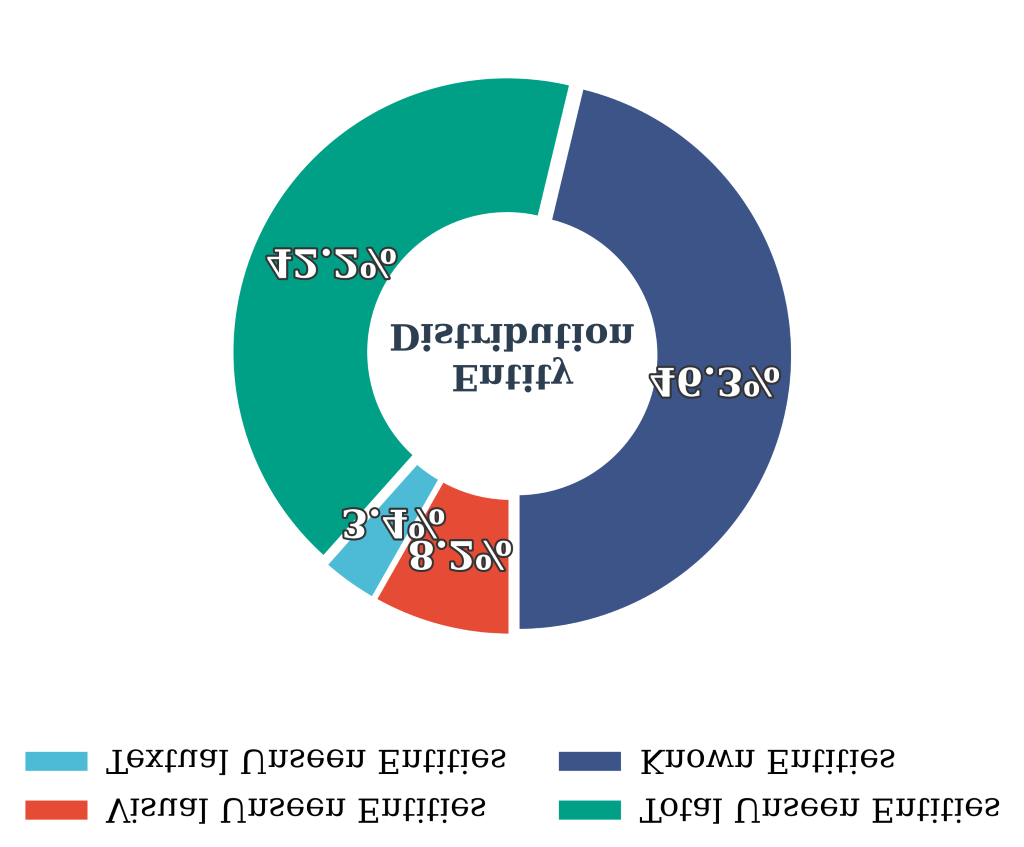
图 3: Figure 3 (extracted from PDF)
原始摘要
Grounded Multimodal Named Entity Recognition (GMNER) aims to extract named entities and localize their visual regions within image-text pairs, serving as a pivotal capability for various downstream applications. In open-world social media platforms, GMNER remains challenging due to the prevalence of long-tailed, rapidly evolving, and unseen entities. To tackle this, existing approaches typically rely on either external knowledge exploration through heuristic retrieval or internal knowledge exploitation via iterative refinement in Multimodal Large Language Models (MLLMs). However, heuristic retrieval often introduces noisy or conflicting evidence that degrades precision on known entities, while solely internal exploitation is constrained by the knowledge boundaries of MLLMs and prone to hallucinations. To address this, we propose SAKE, an end-to-end agentic framework that harmonizes internal knowledge exploitation and external knowledge exploration via self-aware reasoning and adaptive search tool invocation. We implement this via a two-stage training paradigm. First, we propose Difficulty-aware Search Tag Generation, which quantifies the model’s entity-level uncertainty through multiple forward samplings to produce explicit knowledge-gap signals. Based on these signals, we construct SAKE-SeCoT, a high-quality Chain-of-Thought dataset that equips the model with basic self-awareness and tool-use capabilities through supervised fine-tuning. Second, we employ agentic reinforcement learning with a hybrid reward function that penalizes unnecessary retrieval, enabling the model to evolve from rigid search imitation to genuine self-aware decision-making about when retrieval is truly necessary. Extensive experiments on two widely used social media benchmarks demonstrate SAKE’s effectiveness.