arXiv: 2604.20452 · PDF
Authors: Peng Peng, Weiwei Lin, Wentai Wu, Xinyang Wang, Yongheng Liu
Primary category: cs.IR · all: cs.CL, cs.IR
Matched keywords: large language model, llm, agent, agentic, retrieval, rag, inference, latency
TL;DR
HaS accelerates Retrieval-Augmented Generation by speculatively retrieving from a restricted scope, then validating candidates via “homologous query re-identification” — checking whether the incoming query matches a previously-seen one. This bypasses full-database search for repeat-like queries, cutting latency 24–37% with 1–2% accuracy loss.
Key Ideas
- Observation: real-world RAG traffic has popularity skew → many queries are homologous (semantically equivalent re-encounters) to past ones.
- Existing acceleration is bimodal: approximate ANN (hurts accuracy) or exact-duplicate caching (marginal gain). HaS fills the middle.
- Frames draft validation as a re-identification task rather than approximate similarity.
- Plug-and-play, no model retraining; extends to multi-hop agentic RAG.
Approach
Two-stage speculative pipeline analogous to speculative decoding in LLMs:
- Draft: low-latency retrieval over a restricted scope (subset of the corpus) yields candidate documents.
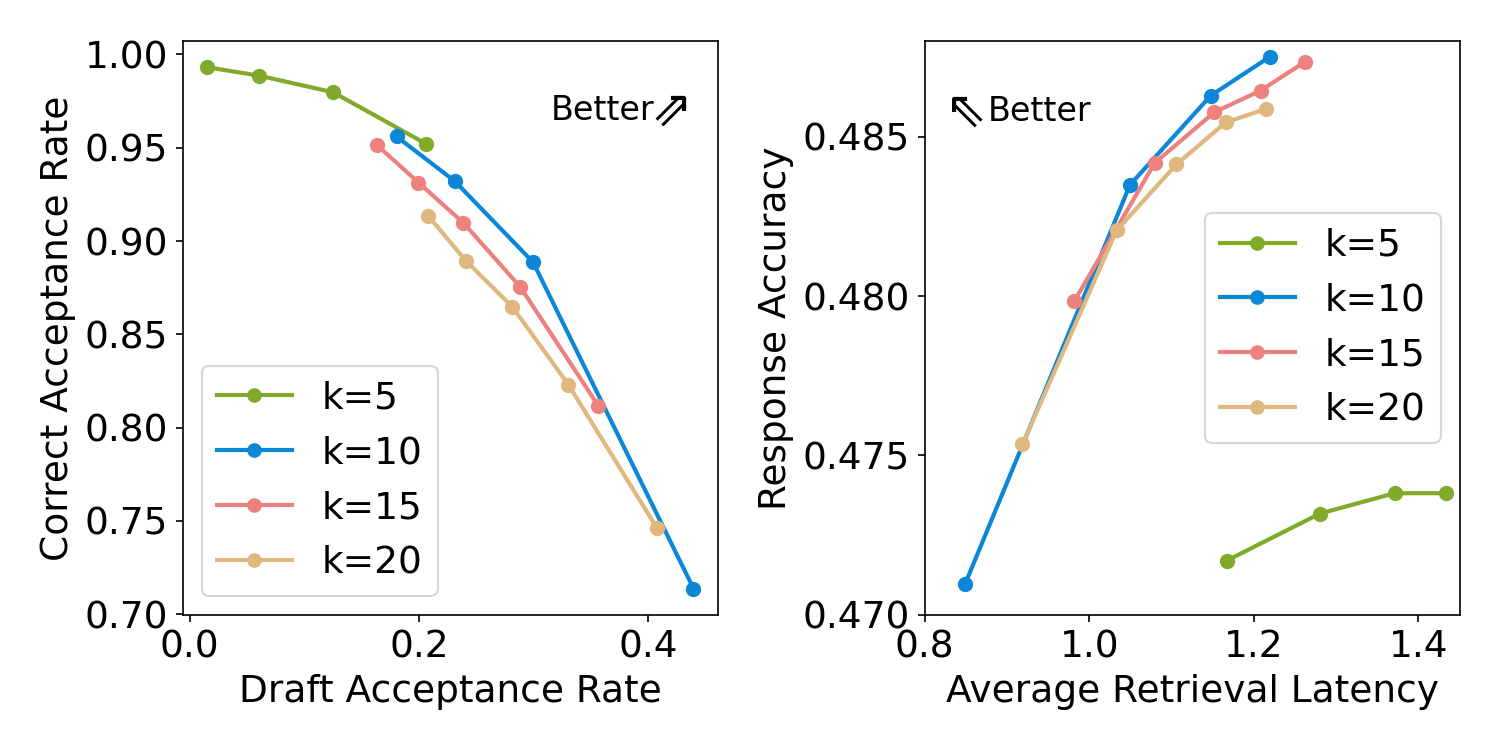
- Verify: a homology re-identification module decides whether the incoming query is a homologous re-encounter of a prior observed query whose retrieval result is cached. If yes, accept the draft and skip full retrieval; else fall back to full-database search. Validation is grounded in a learned homology relation between queries (exact method underspecified in abstract).
Experiments
Abstract reports results on multiple datasets (unnamed here) measuring retrieval latency and downstream accuracy. Includes an agentic / multi-hop RAG scenario. Baselines implied: full retrieval, approximate retrieval, and exact-query caching. Code is released.
Results
- Retrieval latency reduced by 23.74% and 36.99% on two datasets.
- Accuracy drop limited to 1–2%.
- Reports additional speedups on multi-hop agentic RAG pipelines (magnitudes not quoted in abstract). Claims are plausible but the abstract does not disclose dataset names, query-distribution assumptions, or index type — so real-world generality needs inspection.
Why It Matters
Gives RAG serving systems a speculative-execution primitive that trades almost no accuracy for meaningful latency cuts, especially valuable for agentic pipelines where each step pays retrieval cost. Useful for infra teams running vector DBs under skewed query loads.
Connections to Prior Work
- Speculative decoding (Leviathan et al., Medusa) — same draft/verify pattern applied to retrieval.
- Semantic/GPT caching (GPTCache) — exact/near-duplicate query reuse; HaS generalizes beyond strict identity.
- Approximate nearest-neighbor search (HNSW, IVF-PQ) — HaS positions itself as accuracy-preserving alternative.
- Query re-identification / paraphrase detection literature.
- Agentic RAG and multi-hop retrieval (IRCoT, Self-RAG).
Open Questions
- How is the homology classifier trained, and how does it generalize to unseen domains?
- Behavior under cold start or low query repetition (long-tail workloads).
- How is the “restricted scope” chosen, and can it be learned adaptively?
- Memory/storage overhead of the observed-query cache at production scale.
- Robustness to adversarial or drifting query distributions.
Figures
Figure 1: Figure 1 (extracted from PDF)
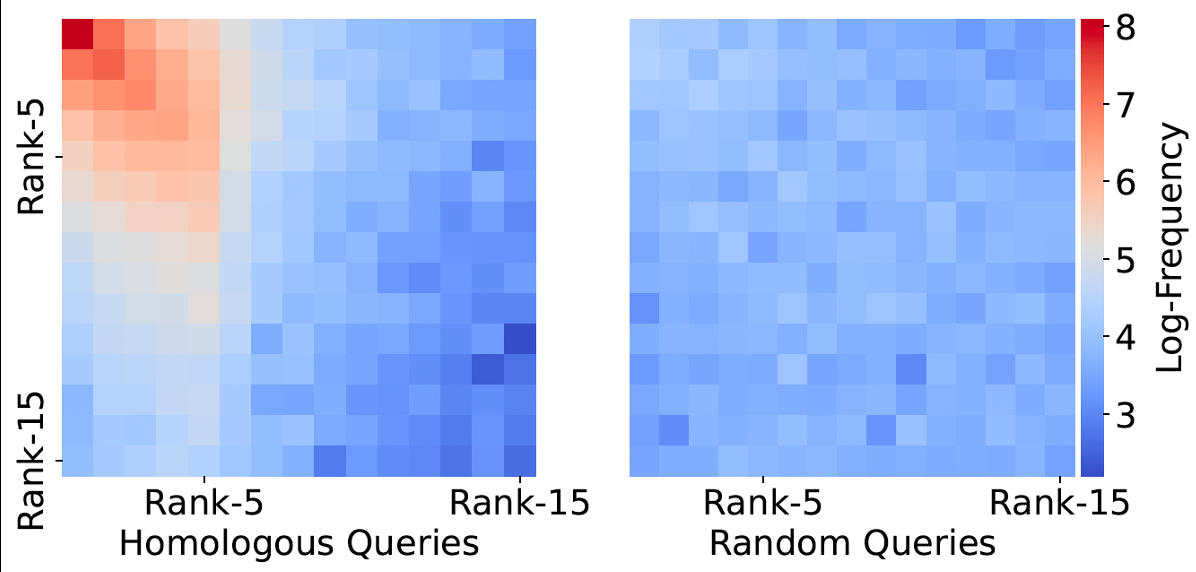
Figure 2: Figure 2 (extracted from PDF)
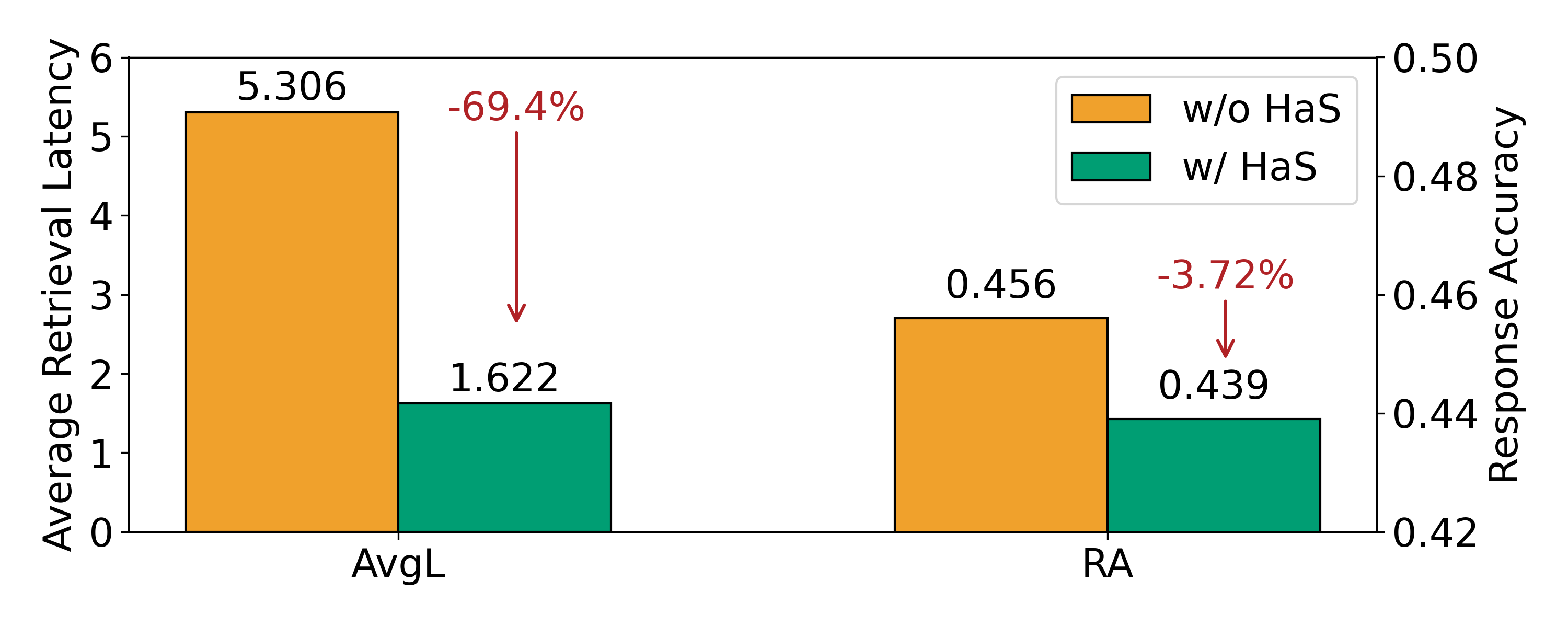
Figure 3: Figure 3 (extracted from PDF)
Original abstract
Retrieval-Augmented Generation (RAG) expands the knowledge boundary of large language models (LLMs) at inference by retrieving external documents as context. However, retrieval becomes increasingly time-consuming as the knowledge databases grow in size. Existing acceleration strategies either compromise accuracy through approximate retrieval, or achieve marginal gains by reusing results of strictly identical queries. We propose HaS, a homology-aware speculative retrieval framework that performs low-latency speculative retrieval over restricted scopes to obtain candidate documents, followed by validating whether they contain the required knowledge. The validation, grounded in the homology relation between queries, is formulated as a homologous query re-identification task: once a previously observed query is identified as a homologous re-encounter of the incoming query, the draft is deemed acceptable, allowing the system to bypass slow full-database retrieval. Benefiting from the prevalence of homologous queries under real-world popularity patterns, HaS achieves substantial efficiency gains. Extensive experiments demonstrate that HaS reduces retrieval latency by 23.74% and 36.99% across datasets with only a 1-2% marginal accuracy drop. As a plug-and-play solution, HaS also significantly accelerates complex multi-hop queries in modern agentic RAG pipelines. Source code is available at: https://github.com/ErrEqualsNil/HaS.