arXiv: 2604.20452 · PDF
作者: Peng Peng, Weiwei Lin, Wentai Wu, Xinyang Wang, Yongheng Liu
主分类: cs.IR · 全部: cs.CL, cs.IR
命中关键词: large language model, llm, agent, agentic, retrieval, rag, inference, latency
TL;DR
HaS 提出一种同源感知的推测式检索框架,通过小范围推测 + 同源查询再识别验证,在几乎不损精度的前提下显著加速 RAG 检索。
核心观点
- 现有 RAG 加速要么牺牲精度(近似检索),要么仅对完全相同的查询复用结果,收益有限。
- 现实查询分布具有流行度特征,存在大量"同源"查询,可被利用。
- 将推测执行思想迁移到检索层:先低延迟草稿,再快速验证。
- 把验证问题形式化为"同源查询再识别"任务。
- 作为即插即用模块,也能加速多跳 agentic RAG。
方法
HaS 分两阶段:
- 推测检索 (Speculative Retrieval):在受限范围内以低延迟获取候选文档草稿,绕过对全库的昂贵检索。
- 同源验证 (Homology-Aware Validation):判断当前 query 与历史 query 是否构成同源再遇;若是,则接受草稿,跳过完整检索;否则回退到全库检索。 验证依托查询间的同源关系,本质是分类/再识别任务。
实验
- 多个 RAG 数据集(摘要未具名)。
- 基线:完整全库检索与现有近似/缓存式加速策略。
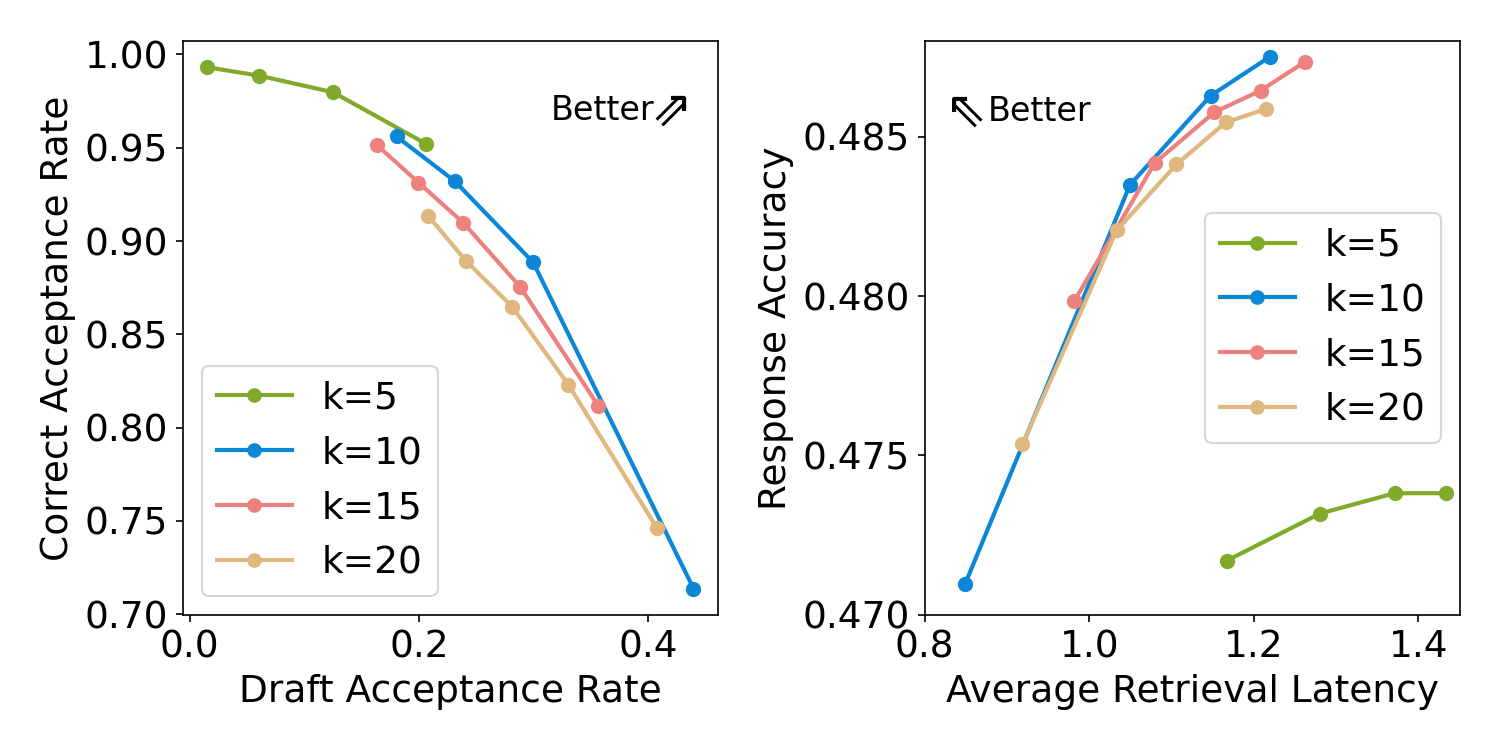
- 指标:检索延迟、端到端精度、对复杂 multi-hop agentic RAG 的加速比。
结果
- 检索延迟降低 23.74% 与 36.99%(跨不同数据集)。
- 精度仅下降 1–2%。
- 在 agentic multi-hop RAG pipeline 中也带来显著加速。
- 具体绝对数字与 agentic 加速比摘要未披露。
为什么重要
对 LLM / Agent 基础设施:大规模知识库下检索已成 RAG 延迟瓶颈,HaS 把 LLM 推理中的 speculative decoding 思路带到检索层,几乎零精度代价换显著延迟下降;对高 QPS、多跳 agent 场景尤其有用,可作为现有 RAG 栈的 drop-in 组件。
与已有工作的关系
- RAG 与 agentic RAG:扩展 vanilla RAG、Self-RAG、multi-hop agent 检索。
- 近似最近邻检索:区别于 HNSW / IVF-PQ 等以精度换速度的方案。
- 缓存式检索复用:比只命中完全相同 query 的缓存更泛化。
- Speculative decoding:把 draft-then-verify 思想从 token 生成迁移到 document 检索层。
尚未回答的问题
- 同源判定器的具体实现与误判代价?对抗性或长尾 query 下是否失效。
- “受限范围"如何选取?是否依赖历史日志、冷启动表现如何。
- 在知识库频繁更新或高度动态 corpus 下稳定性未知。
- 相比 ANN(HNSW、ScaNN)及 learned index 的正面对比缺失。
- 1–2% 精度下降在高精度要求场景(医疗/法律 RAG)是否可接受。
- 多跳 agentic RAG 中同源关系是否仍成立的分析不足。
论文图表
图 1: Figure 1 (extracted from PDF)
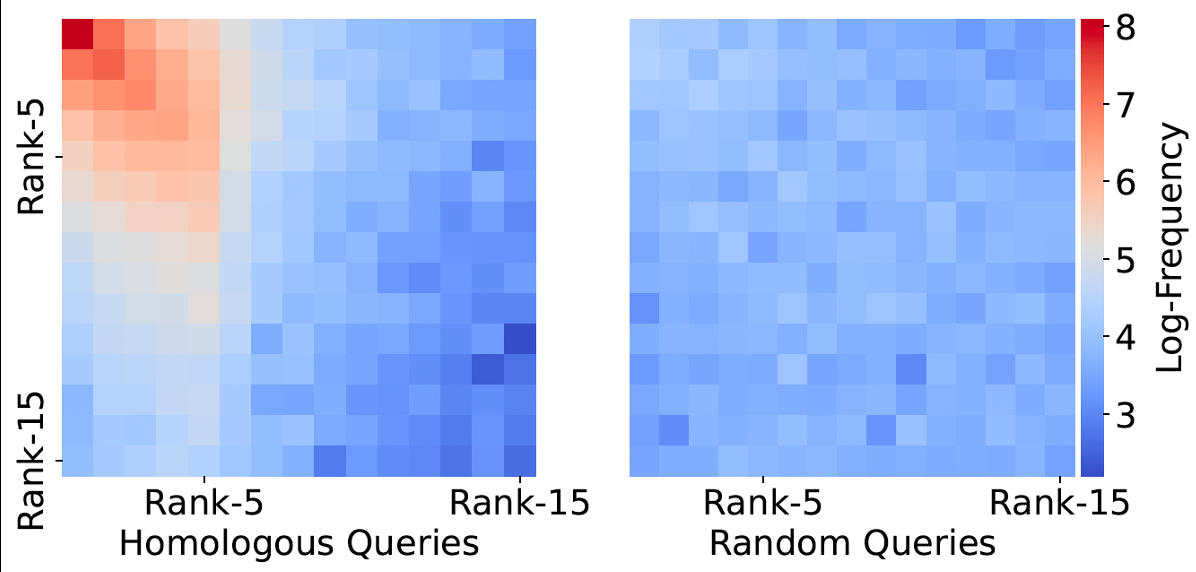
图 2: Figure 2 (extracted from PDF)
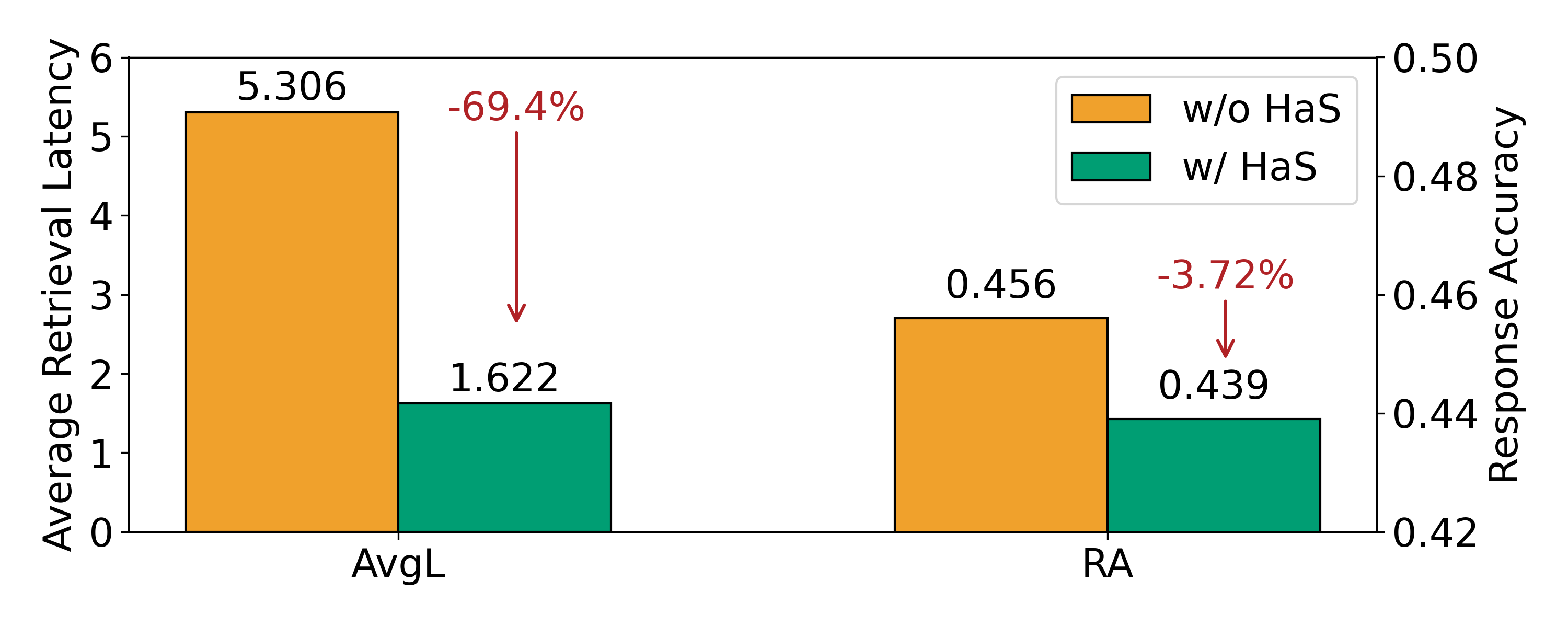
图 3: Figure 3 (extracted from PDF)
原始摘要
Retrieval-Augmented Generation (RAG) expands the knowledge boundary of large language models (LLMs) at inference by retrieving external documents as context. However, retrieval becomes increasingly time-consuming as the knowledge databases grow in size. Existing acceleration strategies either compromise accuracy through approximate retrieval, or achieve marginal gains by reusing results of strictly identical queries. We propose HaS, a homology-aware speculative retrieval framework that performs low-latency speculative retrieval over restricted scopes to obtain candidate documents, followed by validating whether they contain the required knowledge. The validation, grounded in the homology relation between queries, is formulated as a homologous query re-identification task: once a previously observed query is identified as a homologous re-encounter of the incoming query, the draft is deemed acceptable, allowing the system to bypass slow full-database retrieval. Benefiting from the prevalence of homologous queries under real-world popularity patterns, HaS achieves substantial efficiency gains. Extensive experiments demonstrate that HaS reduces retrieval latency by 23.74% and 36.99% across datasets with only a 1-2% marginal accuracy drop. As a plug-and-play solution, HaS also significantly accelerates complex multi-hop queries in modern agentic RAG pipelines. Source code is available at: https://github.com/ErrEqualsNil/HaS.