arXiv: 2604.20795 · PDF
Authors: Pavel Salovskii, Iuliia Gorshkova
Primary category: cs.AI · all: cs.AI
Matched keywords: large language model, llm, agent, retrieval, rag, reasoning, inference
TL;DR
The paper proposes a hybrid architecture augmenting LLMs with an external RDF/OWL ontological memory layer, automatically constructed from heterogeneous sources, to enable persistent, verifiable, and semantically grounded reasoning beyond vector-based RAG.
Key Ideas
- LLMs suffer from weak long-term memory, poor structure, and unreliable multi-step reasoning.
- An external ontology (RDF/OWL knowledge graph) acts as verifiable memory and planning substrate.
- Automated pipeline builds and maintains the ontology from documents, APIs, and dialogue logs.
- SHACL/OWL constraints turn inference into a generation–verification–correction loop.
- Hybrid inference combines vector retrieval, graph reasoning, and external tool calls.
Approach
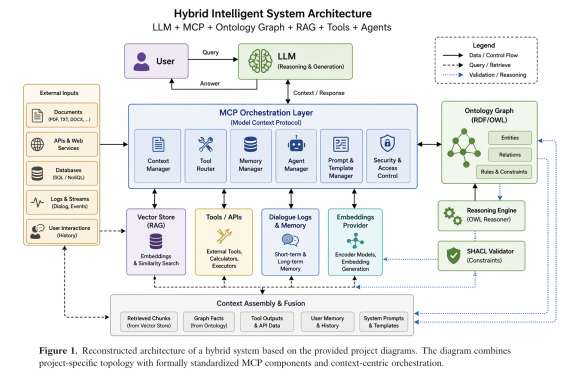
The pipeline extracts entities and relations from heterogeneous inputs, normalizes them, and generates RDF triples. Triples are validated against SHACL shapes and OWL axioms, then merged into a continuously updated knowledge graph. At inference time, the LLM conditions on a composite context fusing vector-retrieved passages, graph subqueries, and tool outputs. Generated answers are checked against ontology constraints; violations trigger correction, yielding a closed verify-and-repair loop.
Experiments
The abstract is thin on experimental detail. It mentions “planning tasks” with the Tower of Hanoi benchmark as the concrete test case, comparing the ontology-augmented system against baseline LLM systems. No datasets sizes, model identities, metrics, or ablations are disclosed in the abstract.
Results
Only qualitative claims are given: ontology augmentation “improves performance in multi-step reasoning scenarios” on Tower of Hanoi versus plain LLM baselines, and the ontology layer enables formal validation of outputs. No numerical results, confidence intervals, or failure-case analysis are reported in the abstract, so the strength of the claim cannot be assessed.
Why It Matters
For agent builders and enterprise AI, persistent structured memory with formal validation addresses hallucination, auditability, and long-horizon planning — pain points that pure RAG does not solve. It points toward neuro-symbolic agents where LLMs propose and ontologies dispose, useful for robotics, compliance-heavy domains, and explainable decision systems.
Connections to Prior Work
Builds on neuro-symbolic AI, knowledge-graph–augmented LLMs (KG-RAG, GraphRAG), and classical semantic web stacks (RDF, OWL, SHACL). Relates to tool-using agents (ReAct, Toolformer), retrieval-augmented generation, and planning benchmarks like Tower of Hanoi used in LLM reasoning studies. Echoes long-term memory efforts such as MemGPT and structured scratchpads.
Open Questions
- How does ontology construction scale and handle noisy or contradictory sources?
- What are quantitative results beyond Tower of Hanoi on realistic planning or QA benchmarks?
- Latency and cost of the verify-correct loop versus plain RAG?
- How are ontology schema drift, versioning, and multi-agent concurrent updates managed?
- Robustness when extraction errors propagate into SHACL-valid but semantically wrong triples.
Figures
Figure 1: Figure 1 (extracted from PDF)
Original abstract
This paper presents a hybrid architecture for intelligent systems in which large language models (LLMs) are extended with an external ontological memory layer. Instead of relying solely on parametric knowledge and vector-based retrieval (RAG), the proposed approach constructs and maintains a structured knowledge graph using RDF/OWL representations, enabling persistent, verifiable, and semantically grounded reasoning. The core contribution is an automated pipeline for ontology construction from heterogeneous data sources, including documents, APIs, and dialogue logs. The system performs entity recognition, relation extraction, normalization, and triple generation, followed by validation using SHACL and OWL constraints, and continuous graph updates. During inference, LLMs operate over a combined context that integrates vector-based retrieval with graph-based reasoning and external tool interaction. Experimental observations on planning tasks, including the Tower of Hanoi benchmark, indicate that ontology augmentation improves performance in multi-step reasoning scenarios compared to baseline LLM systems. In addition, the ontology layer enables formal validation of generated outputs, transforming the system into a generation-verification-correction pipeline. The proposed architecture addresses key limitations of current LLM-based systems, including lack of long-term memory, weak structural understanding, and limited reasoning capabilities. It provides a foundation for building agent-based systems, robotics applications, and enterprise AI solutions that require persistent knowledge, explainability, and reliable decision-making.