arXiv: 2604.20994 · PDF
Authors: Yannis Belkhiter, Giulio Zizzo, Sergio Maffeis, Seshu Tirupathi, John D. Kelleher
Primary category: cs.CR · all: cs.AI, cs.CL, cs.CR
Matched keywords: large language model, llm, agent, agentic, reasoning, attention
TL;DR
This paper introduces Function Hijacking Attacks (FHA), a novel adversarial technique that manipulates agentic LLMs’ tool selection to force invocation of attacker-chosen functions, achieving 70-100% attack success rates across five models on the BFCL benchmark, largely independent of query semantics.
Key Ideas
- Novel Function Hijacking Attack (FHA) targeting the tool/function selection mechanism of agentic LLMs rather than prompt content.
- Attack is semantics-agnostic and robust across different function sets and domains.
- Demonstrates universal adversarial functions: a single crafted function hijacks selection across multiple queries and payloads.
- Exposes vulnerability in MCP-style (Model Context Protocol) function-calling interfaces beyond classical prompt injection/jailbreaking.
Approach
FHA trains adversarial function definitions (name, description, schema) that bias the model’s tool selection routine toward the attacker’s function regardless of user intent. The attack optimizes for universal transferability so one poisoned function works across many queries. Specific optimization details are not spelled out in the abstract.
Experiments
- Models: 5 function-calling LLMs, spanning instruction-tuned and reasoning variants.
- Benchmark: BFCL (Berkeley Function Calling Leaderboard).
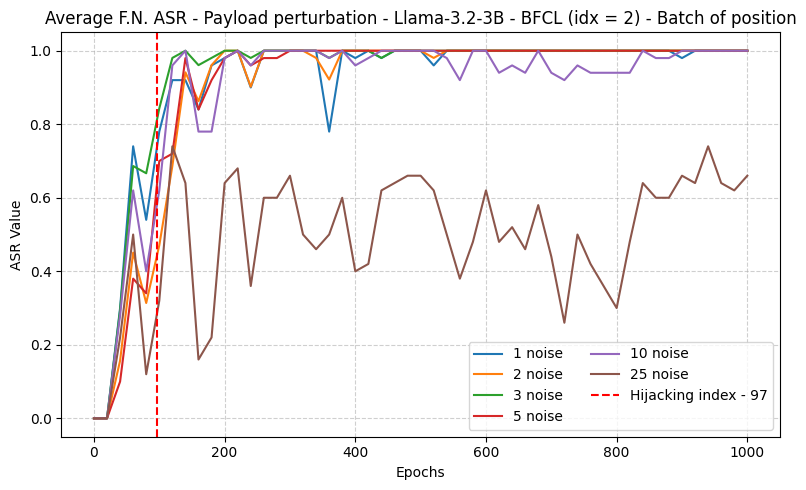
- Metric: Attack Success Rate (ASR) — fraction of queries where the hijacked function is invoked.
- Baselines and ablations not detailed in the abstract.
Results
- ASR between 70% and 100% across the 5 tested models on BFCL.
- Universal adversarial functions generalize across queries/payloads.
- Abstract gives only aggregate ranges; per-model breakdown and comparison to prior function-calling attacks aren’t quantified here.
Why It Matters
Agentic systems, MCP servers, and tool-using LLMs often trust registered function metadata. FHA shows that malicious tool listings can silently reroute execution — a supply-chain-style risk for marketplaces of MCP tools, plugin ecosystems, and multi-agent orchestrators. Argues for mandatory guardrails, tool-provenance checks, and isolation layers in agent stacks.
Connections to Prior Work
- Extends prompt injection and jailbreaking literature to the tool-selection layer.
- Builds on function-calling abuse work showing data tampering, infinite loops, and harmful-content elicitation via tools.
- Related to universal adversarial triggers in NLP, now applied to tool schemas.
- Relevant to MCP security and agentic-AI red-teaming efforts.
Open Questions
- What defenses (schema sanitization, tool vetting, dual-model verification) actually blunt FHA?
- Does FHA transfer to closed models (GPT, Claude, Gemini) beyond the 5 tested?
- How does it interact with reasoning traces — do chain-of-thought models resist or amplify the attack?
- Can detection classifiers flag adversarial function definitions pre-registration?
- Real-world MCP deployment impact vs. BFCL benchmark conditions remains unquantified.
Figures
Figure 1: Figure 1 (extracted from PDF)
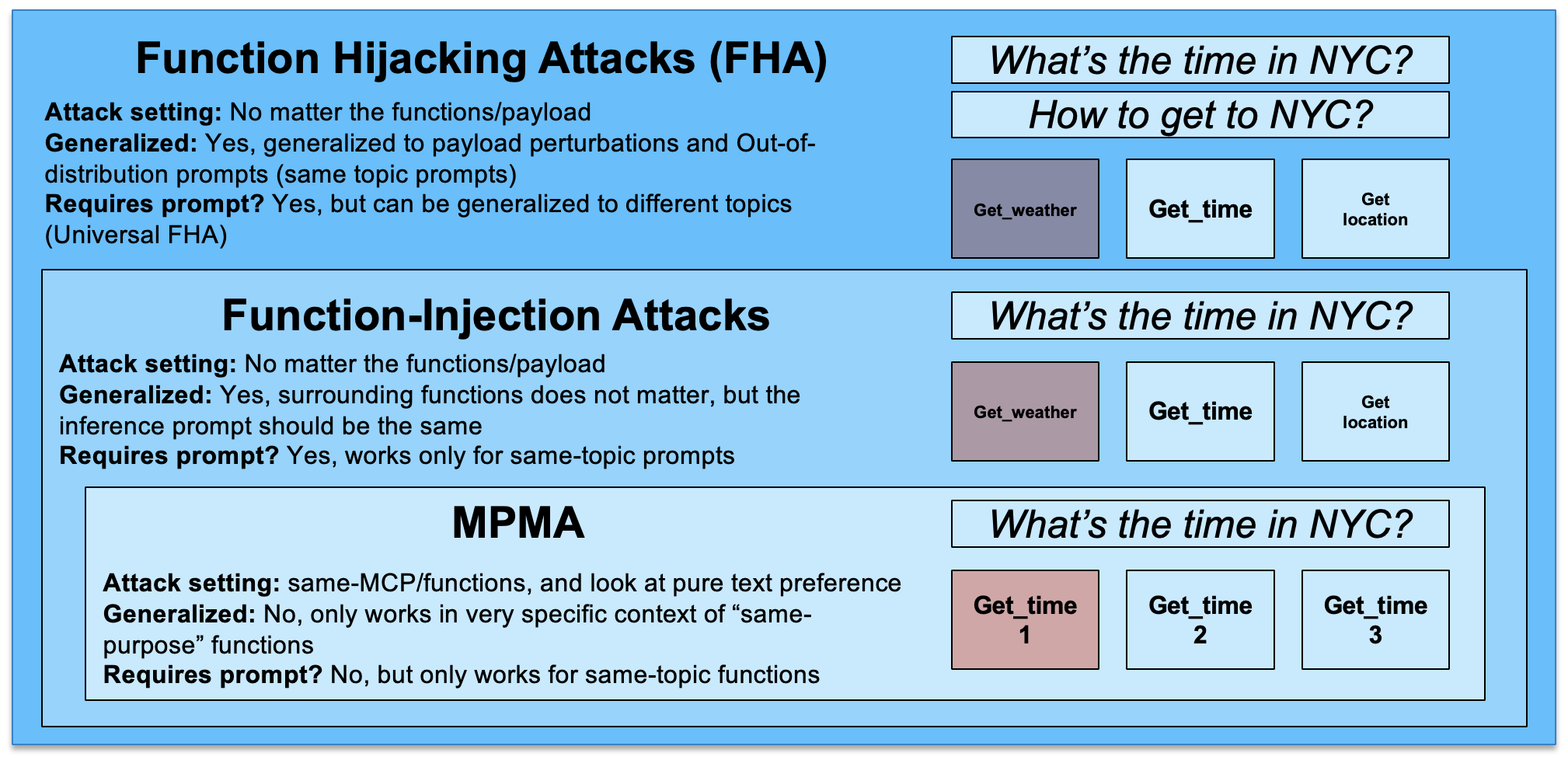
Figure 2: Figure 2 (extracted from PDF)
Figure 3: Figure 3 (extracted from PDF)
Original abstract
The growth of agentic AI has drawn significant attention to function calling Large Language Models (LLMs), which are designed to extend the capabilities of AI-powered system by invoking external functions. Injection and jailbreaking attacks have been extensively explored to showcase the vulnerabilities of LLMs to user prompt manipulation. The expanded capabilities of agentic models introduce further vulnerabilities via their function calling interface. Recent work in LLM security showed that function calling can be abused, leading to data tampering and theft, causing disruptive behavior such as endless loops, or causing LLMs to produce harmful content in the style of jailbreaking attacks. This paper introduces a novel function hijacking attack (FHA) that manipulates the tool selection process of agentic models to force the invocation of a specific, attacker-chosen function. While existing attacks focus on semantic preference of the model for function-calling tasks, we show that FHA is largely agnostic to the context semantics and robust to the function sets, making it applicable across diverse domains. We further demonstrate that FHA can be trained to produce universal adversarial functions, enabling a single attacked function to hijack tool selection across multiple queries and payload configurations. We conducted experiments on 5 different models, including instructed and reasoning variants, reaching 70% to 100% ASR over the established BFCL dataset. Our findings further demonstrate the need for strong guardrails and security modules for agentic systems.