arXiv: 2604.20994 · PDF
作者: Yannis Belkhiter, Giulio Zizzo, Sergio Maffeis, Seshu Tirupathi, John D. Kelleher
主分类: cs.CR · 全部: cs.AI, cs.CL, cs.CR
命中关键词: large language model, llm, agent, agentic, reasoning, attention
TL;DR
提出 Function Hijacking Attack (FHA),通过操纵 agentic LLM 的工具选择过程,强制调用攻击者指定的函数,在 BFCL 上对 5 个模型实现 70%–100% 攻击成功率。
核心观点
- 现有 injection/jailbreaking 攻击主要针对 prompt,而 function calling 接口本身是一个被低估的新攻击面。
- FHA 与上下文语义无关、对函数集合鲁棒,可跨领域迁移。
- 可训练出 universal adversarial functions:单个被污染函数即可劫持多种 query 和 payload 的工具选择。
- 结果凸显 agentic / MCP 系统亟需更强的 guardrails 与安全模块。
方法
作者针对 function calling LLM 的 tool selection 过程设计对抗扰动,不改 prompt 而是改"候选函数"本身(名字、描述、schema 等),让模型在面对任意用户请求时都倾向于选中攻击者指定的 function。在此基础上通过优化训练出 universal 版本,使单一恶意函数对多种 query 与 payload 均有效。摘要未披露具体损失函数与优化算法细节。
实验
- 模型:5 个 function-calling LLM,涵盖 instructed 与 reasoning 两类变体(具体型号未在摘要列出)。
- 数据集 / benchmark:Berkeley Function Calling Leaderboard (BFCL)。
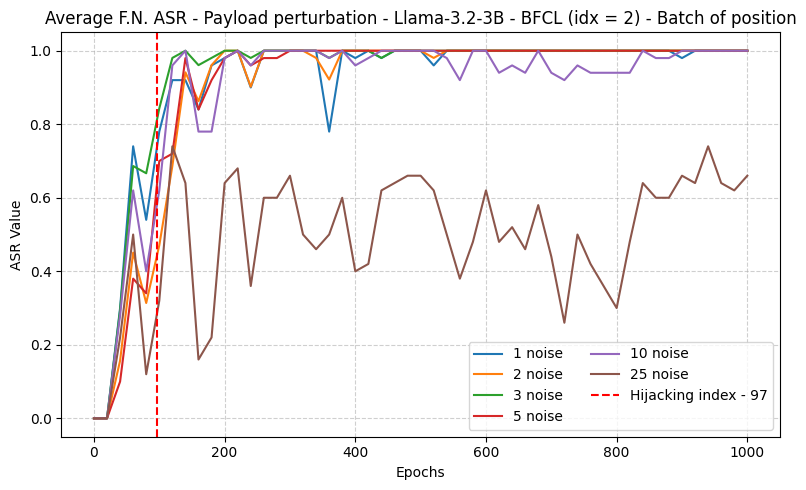
- 指标:Attack Success Rate (ASR),即模型被迫选择攻击者指定函数的比例。
- 基线:摘要未明确列出对比方法。
结果
跨 5 个模型在 BFCL 上取得 70%–100% ASR。universal adversarial function 能在多 query、多 payload 配置下保持有效。摘要未给出具体每个模型数字与消融,因此横向比较与鲁棒性边界需看正文。
为什么重要
对 MCP、tool-use agent、function-calling 生态而言,这类攻击意味着:只要一个工具/插件被污染或被攻击者注册进工具池,就可能在语义无关的情况下劫持整个 agent 的行为,导致数据外泄、越权调用、破坏性操作。现有以 prompt 为中心的防御无法覆盖,需要面向 tool registry、schema 校验、tool ranking 的新安全栈。
与已有工作的关系
延续 prompt injection / jailbreaking 对 LLM 攻击面的探索,并扩展到近期的 function calling 滥用研究(数据篡改、死循环、有害内容生成)。相较于 BFCL 等 benchmark 关注能力,本文把它当作攻击评测床;与 universal adversarial triggers (UAT)、prompt-level 对抗攻击思路相承,但作用域从 prompt 转到 tool schema。
尚未回答的问题
- 对抗函数在真实 MCP server、第三方工具市场下的可部署性和隐蔽性如何?
- 是否能被简单防御(schema 规范化、工具签名、ranking guardrail、LLM-as-judge)挫败?
- 对 reasoning / planner-executor 架构、多轮 tool use 的影响?
- 是否能迁移到闭源商用模型(GPT、Claude、Gemini)及其 function calling API?
- universal function 的可检测性与对抗训练能否提供稳健防护?
论文图表
图 1: Figure 1 (extracted from PDF)
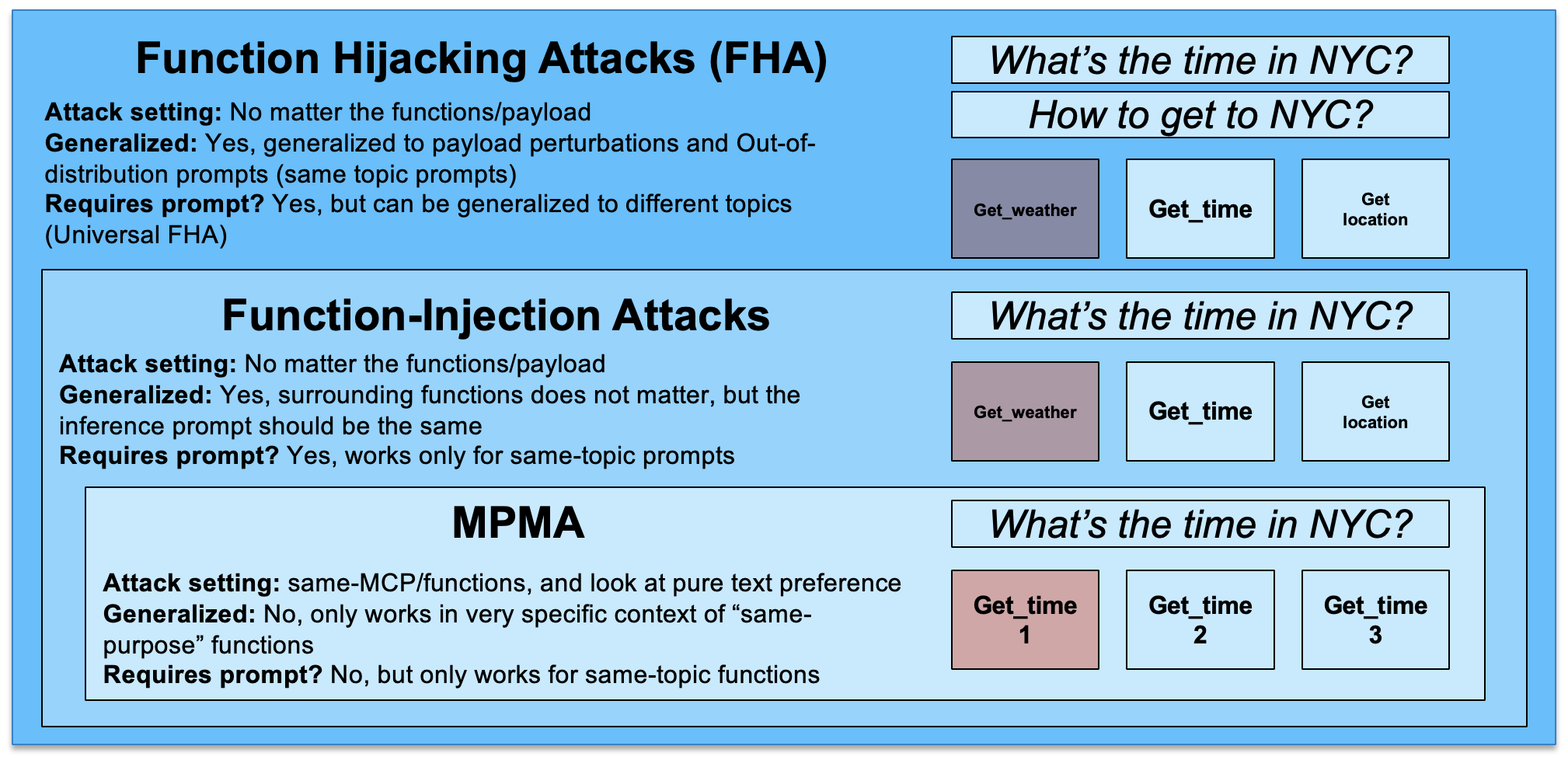
图 2: Figure 2 (extracted from PDF)
图 3: Figure 3 (extracted from PDF)
原始摘要
The growth of agentic AI has drawn significant attention to function calling Large Language Models (LLMs), which are designed to extend the capabilities of AI-powered system by invoking external functions. Injection and jailbreaking attacks have been extensively explored to showcase the vulnerabilities of LLMs to user prompt manipulation. The expanded capabilities of agentic models introduce further vulnerabilities via their function calling interface. Recent work in LLM security showed that function calling can be abused, leading to data tampering and theft, causing disruptive behavior such as endless loops, or causing LLMs to produce harmful content in the style of jailbreaking attacks. This paper introduces a novel function hijacking attack (FHA) that manipulates the tool selection process of agentic models to force the invocation of a specific, attacker-chosen function. While existing attacks focus on semantic preference of the model for function-calling tasks, we show that FHA is largely agnostic to the context semantics and robust to the function sets, making it applicable across diverse domains. We further demonstrate that FHA can be trained to produce universal adversarial functions, enabling a single attacked function to hijack tool selection across multiple queries and payload configurations. We conducted experiments on 5 different models, including instructed and reasoning variants, reaching 70% to 100% ASR over the established BFCL dataset. Our findings further demonstrate the need for strong guardrails and security modules for agentic systems.