arXiv: 2604.20503 · PDF
Authors: Wenyan Chen, Chengzhi Lu, Yanying Lin, Dmitrii Ustiugov
Primary category: cs.DC · all: cs.DC
Matched keywords: llm, inference, serving, speculative decoding, gpu, throughput, latency
TL;DR
FASER is a fine-grained speculative-decoding scheduler for dynamic LLM serving that tunes speculative length per request, prunes rejected tokens early, and spatially overlaps draft and verification phases, yielding up to 53% higher throughput and 1.92× lower latency over SOTA in vLLM.
Key Ideas
- Coarse-grained, batch-level speculative decoding (SD) wastes GPU cycles under both low and high load.
- Speculative length should be a per-request knob inside a continuous batch, not a global constant.
- Verification can be chunked into “frontiers” and overlapped with drafting via spatial multiplexing.
- Rejected tokens can be pruned mid-verification to avoid wasted compute.
Approach
FASER extends vLLM with three mechanisms: (1) dynamic per-request speculative length based on acceptance behavior within a continuous batch; (2) early pruning that terminates verification for tokens already rejected, reclaiming GPU work; (3) frontier-based verification that splits the verify pass into chunks and co-executes them with draft kernels using fine-grained spatial multiplexing for low interference.
Experiments
Prototype built on vLLM and compared against state-of-the-art SD systems. The abstract does not name datasets, models, baseline systems, or metric definitions beyond throughput and latency — details are thin.
Results
- Up to 53% throughput improvement over SOTA SD systems.
- Up to 1.92× latency reduction.
- Gains attributed to eliminating draft/verify serialization and reducing rejected-token compute; no breakdown shown in the abstract.
Why It Matters
For LLM serving infra, SD is already standard, but rigid batch-level scheduling caps its benefit under bursty online traffic. Fine-grained phase management offers a path to keep GPUs saturated at low load and avoid wasted verification at high load — directly improving $/token and tail latency for production inference stacks.
Connections to Prior Work
- Speculative decoding lineage: Leviathan et al., Medusa, EAGLE, SpecInfer.
- Continuous batching / serving: vLLM, Orca.
- GPU spatial multiplexing and kernel overlap: REEF, Paella, NVIDIA MPS/Streams-based schedulers.
- Adaptive speculative length: SpecDec++, dynamic-γ variants.
Open Questions
- Which draft/target model pairs and workloads were evaluated? Does the win hold for long-context or MoE models?
- How is per-request speculative length predicted — heuristic, learned, or feedback-based?
- What is the overhead and interference profile of spatial multiplexing on modern GPUs (H100/B200)?
- Interaction with prefill-heavy traffic and chunked prefill scheduling.
- Robustness when draft-target acceptance rate shifts mid-stream.
Figures
Figure 1: Page 2 (rendered)

Figure 2: Page 3 (rendered)
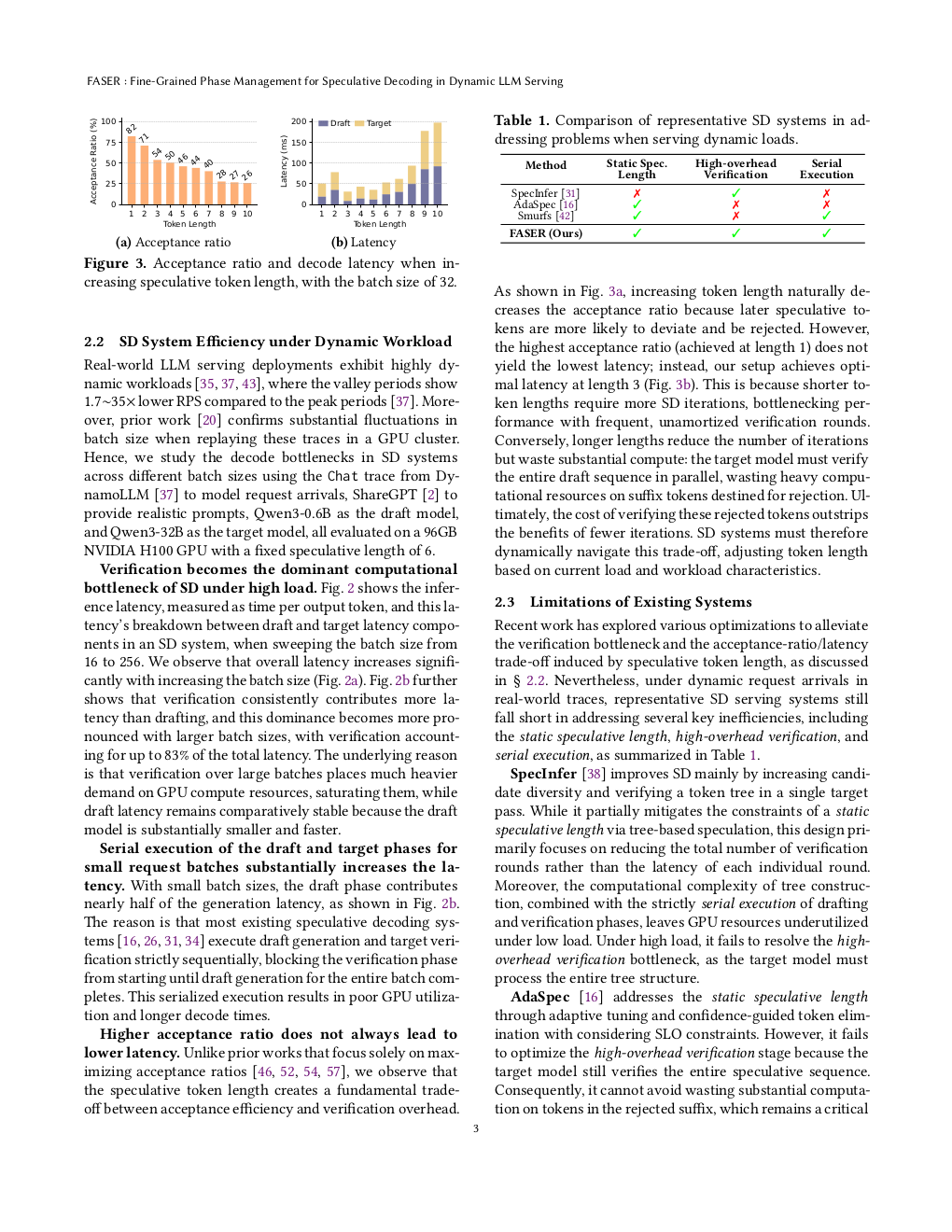
Figure 3: Page 4 (rendered)

Original abstract
Speculative decoding (SD) is a widely used approach for accelerating decode-heavy LLM inference workloads. While online inference workloads are highly dynamic, existing SD systems are rigid and take a coarse-grained approach to SD management. They typically set the speculative token length for an entire batch and serialize the execution of the draft and verification phases. Consequently, these systems fall short at adapting to volatile online inference traffic. Under low load, they exhibit prolonged latency because the draft phase blocks the verification phase for the entire batch, leaving GPU computing resources underutilized. Conversely, under high load, they waste computation on rejected tokens during the verification phase, overloading GPU resources. We introduce FASER, a novel system that features fine-grained SD phase management. First, FASER minimizes computational waste by dynamically adjusting the speculative length for each request within a continuous batch and by performing early pruning of rejected tokens inside the verification phase. Second, FASER breaks the verification phase into frontiers, or chunks, to overlap them with the draft phase. This overlap is achieved via fine-grained spatial multiplexing with minimal resource interference. Our FASER prototype in vLLM improves throughput by up to 53% and reduces latency by up to 1.92$\times$ compared to state-of-the-art systems.