arXiv: 2604.20503 · PDF
作者: Wenyan Chen, Chengzhi Lu, Yanying Lin, Dmitrii Ustiugov
主分类: cs.DC · 全部: cs.DC
命中关键词: llm, inference, serving, speculative decoding, gpu, throughput, latency
TL;DR
FASER 通过细粒度的推测解码阶段管理(动态投机长度、早剪枝、draft/verify 重叠),在 vLLM 中实现最高 53% 吞吐提升与 1.92× 延迟降低。
核心观点
- 现有 SD 系统对整批次设定统一投机长度并串行执行 draft/verify,难以应对动态在线负载。
- 低负载下 GPU 闲置、高负载下大量拒绝 token 浪费算力。
- 需要请求级细粒度 SD 管理 + 阶段重叠以兼顾延迟与吞吐。
方法
- 动态投机长度:在 continuous batching 中按请求调整 speculative length。
- 早剪枝:在 verification 阶段内部尽早丢弃被拒绝 token,避免后续浪费。
- Frontier 分块 verify:把 verification 切成 chunks,与 draft 阶段通过细粒度 spatial multiplexing 重叠执行,降低资源干扰。
- 在 vLLM 上实现原型。
实验
摘要未披露具体数据集、模型规模或基线名称,仅指出对比对象为 state-of-the-art SD 系统,指标为吞吐与延迟。
结果
- 吞吐最多提升 53%。
- 延迟最多降低 1.92×。
- 摘要未给出负载区间、模型尺寸等细节,主张需看正文验证。
为什么重要
对 LLM serving 基础设施而言,FASER 把 SD 从"批级旋钮"升级为"请求级+阶段级"调度,能在流量波动下稳定收益,是在线推理系统进一步压榨 GPU 的实用方向。
与已有工作的关系
承接 speculative decoding(Leviathan、Medusa、EAGLE 等)加速思路,延伸 vLLM 的 continuous batching 调度与 SpecInfer/SpS 等系统级 SD 管理工作;与 GPU spatial multiplexing(MPS、Salus)理念相通。
尚未回答的问题
- 在何种模型规模与 draft/target 组合下收益最大?
- 细粒度 spatial multiplexing 的干扰边界与调度开销?
- 对长上下文、prefill 密集或混合工作负载是否同样有效?
- 与 tree-based 或 multi-draft SD 的组合收益尚待验证。
论文图表
图 1: Page 2 (rendered)

图 2: Page 3 (rendered)
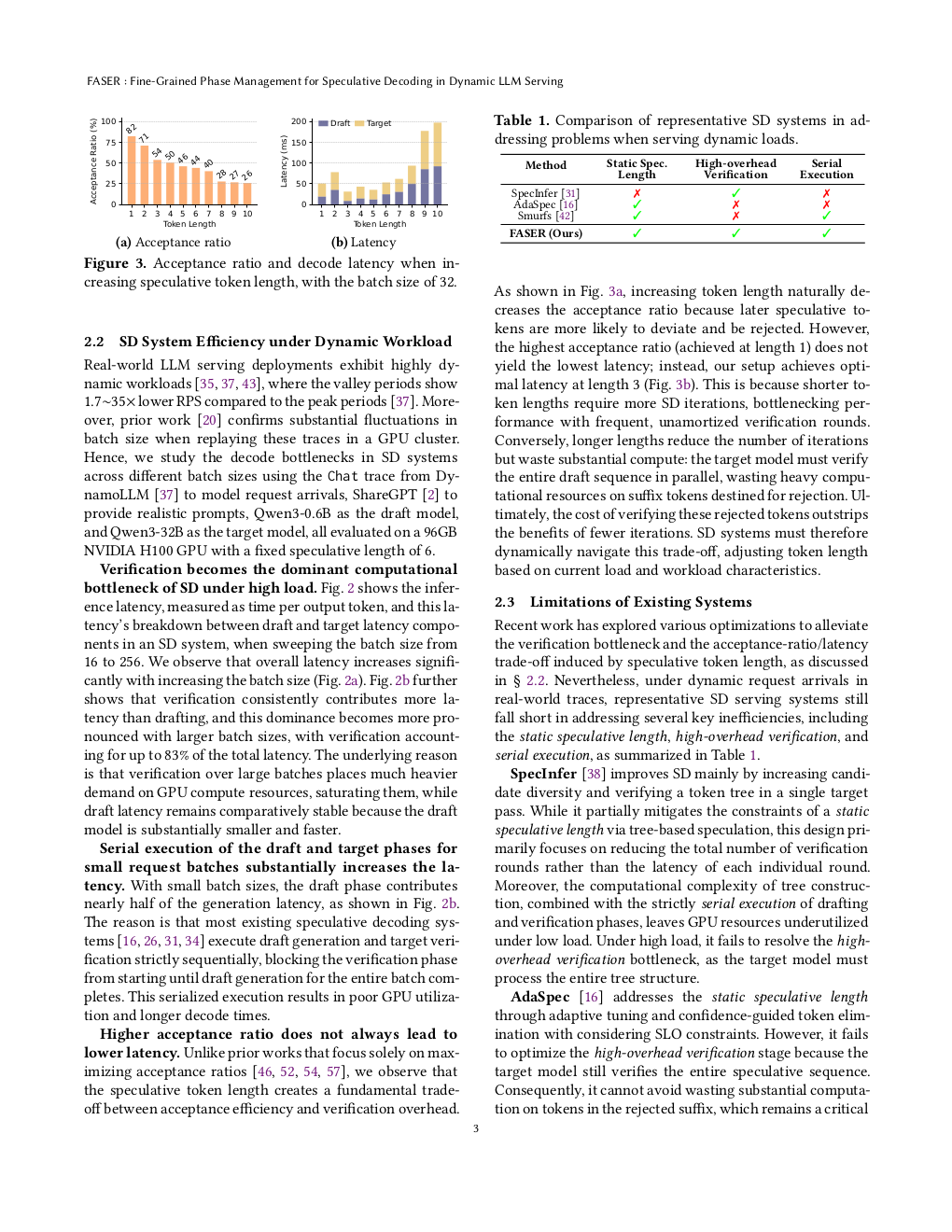
图 3: Page 4 (rendered)

原始摘要
Speculative decoding (SD) is a widely used approach for accelerating decode-heavy LLM inference workloads. While online inference workloads are highly dynamic, existing SD systems are rigid and take a coarse-grained approach to SD management. They typically set the speculative token length for an entire batch and serialize the execution of the draft and verification phases. Consequently, these systems fall short at adapting to volatile online inference traffic. Under low load, they exhibit prolonged latency because the draft phase blocks the verification phase for the entire batch, leaving GPU computing resources underutilized. Conversely, under high load, they waste computation on rejected tokens during the verification phase, overloading GPU resources. We introduce FASER, a novel system that features fine-grained SD phase management. First, FASER minimizes computational waste by dynamically adjusting the speculative length for each request within a continuous batch and by performing early pruning of rejected tokens inside the verification phase. Second, FASER breaks the verification phase into frontiers, or chunks, to overlap them with the draft phase. This overlap is achieved via fine-grained spatial multiplexing with minimal resource interference. Our FASER prototype in vLLM improves throughput by up to 53% and reduces latency by up to 1.92$\times$ compared to state-of-the-art systems.