arXiv: 2604.20133 · PDF
Authors: Aimin Zhang, Jiajing Guo, Fuwei Jia, Chen Lv, Boyu Wang, Fangzheng Li
Primary category: cs.AI · all: cs.AI
Matched keywords: large language model, llm, agent, multi-agent, rag
TL;DR
EvoAgent is an evolvable LLM agent framework combining structured skill learning, hierarchical sub-agent delegation, and a three-layer memory. On real-world foreign-trade tasks with GPT5.2, it lifts a five-dimensional LLM-as-Judge score by ~28%.
Key Ideas
- Skills modeled as multi-file structured capability units with triggers and evolutionary metadata.
- User-feedback-driven closed loop for continuous skill generation and optimization.
- Three-stage skill matching plus three-layer memory architecture for long-term accumulation.
- Hierarchical sub-agent delegation enabling dynamic task decomposition.
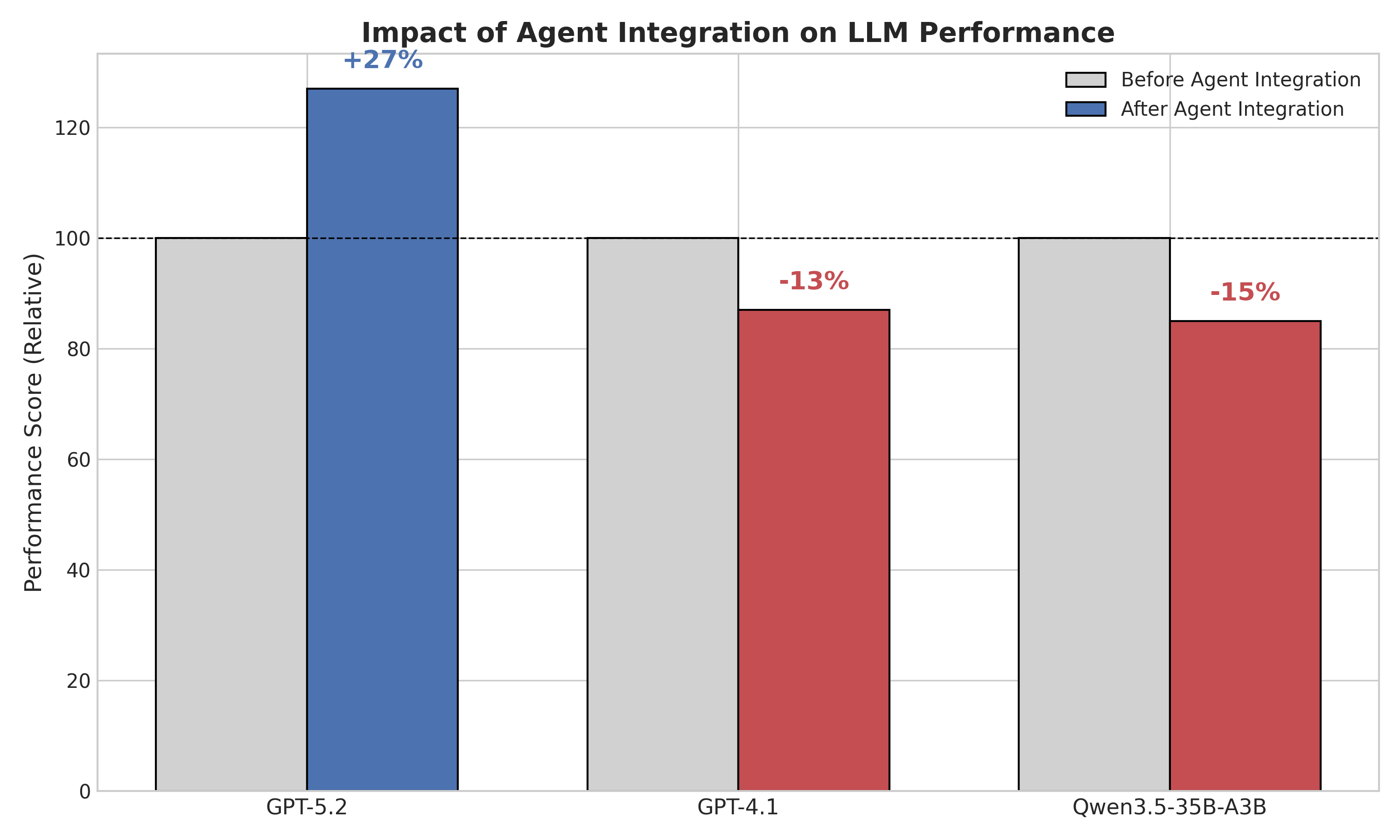
- Agent performance depends on model–architecture synergy, not just base model strength.
Approach
Each skill is a structured artifact (multiple files) carrying triggering logic and evolutionary metadata, so the system can decide when to invoke it and how to mutate it over time. A three-stage matcher selects skills for an incoming task; a three-layer memory separates short-term, working, and long-term context. A hierarchical delegation mechanism spawns sub-agents for decomposed subtasks, and a user-feedback closed loop drives skill creation and refinement.
Experiments
Evaluation is on real-world foreign-trade scenarios using GPT5.2 as the base model, scored under a five-dimensional LLM-as-Judge protocol (professionalism, accuracy, practical utility among them). Model-transfer experiments swap the underlying LLM to test architecture–model synergy. Specific datasets, baselines, or sample sizes are not detailed in the abstract.
Results
Integrating EvoAgent raises the overall average LLM-as-Judge score by roughly 28% over the bare GPT5.2 baseline, with gains reported in professionalism, accuracy, and practical utility. Transfer experiments show gains vary across base models, supporting the synergy claim. Absolute numbers and per-dimension breakdowns are not given in the abstract.
Why It Matters
Offers a concrete blueprint for building agents that accumulate reusable, versioned skills from user feedback rather than relying solely on bigger base models—useful for vertical deployments (e.g., trade, ops) where domain know-how compounds over time and LLM-as-Judge is a pragmatic eval.
Connections to Prior Work
Builds on Voyager-style skill libraries, Generative Agents’ memory stratification, AutoGen/MetaGPT hierarchical multi-agent delegation, Reflexion/self-refine feedback loops, and retrieval-augmented tool selection. The evolutionary metadata angle echoes automatic prompt/skill optimization lines like Promptbreeder.
Open Questions
- What exact datasets, task counts, and baselines underlie the 28% gain?
- How is LLM-as-Judge bias controlled when GPT-class models both act and grade?
- Does skill evolution converge or drift/bloat over long horizons?
- How well does it generalize beyond foreign-trade to other verticals?
- Cost and latency overhead of three-stage matching plus sub-agent delegation?
Figures
Figure 1: Figure 1 (extracted from PDF)
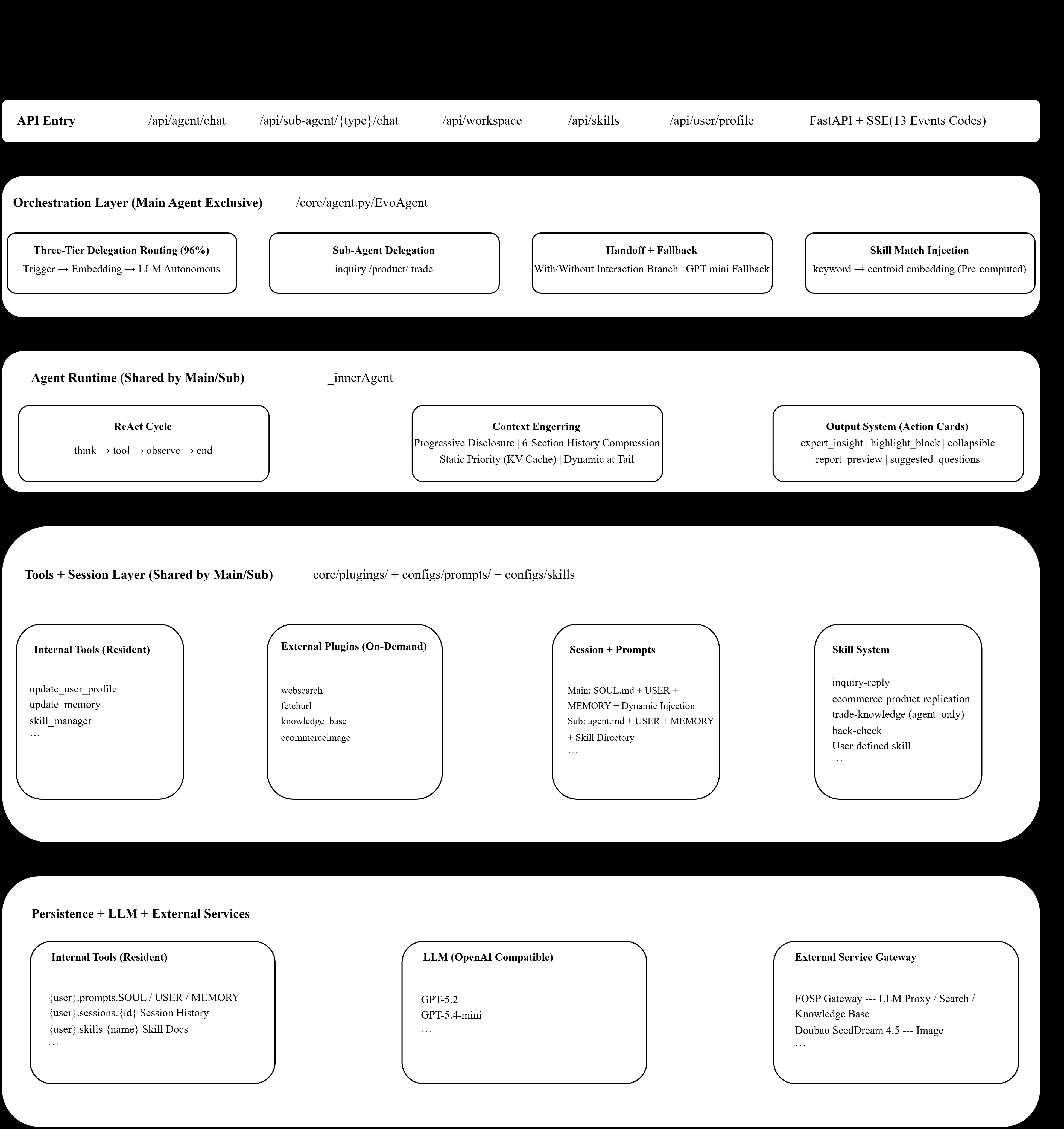
Figure 2: Figure 2 (extracted from PDF)
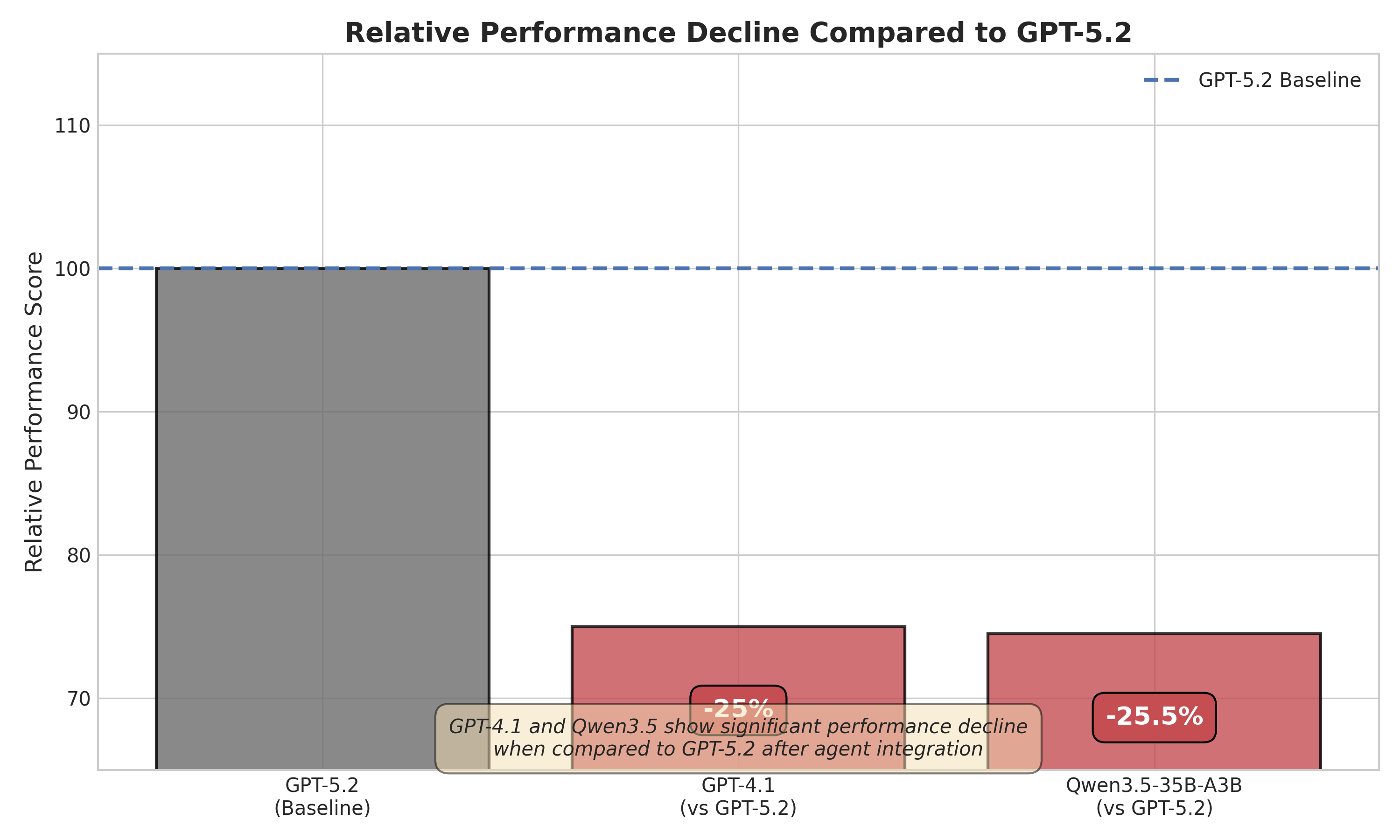
Figure 3: Figure 3 (extracted from PDF)
Original abstract
This paper proposes EvoAgent - an evolvable large language model (LLM) agent framework that integrates structured skill learning with a hierarchical sub-agent delegation mechanism. EvoAgent models skills as multi-file structured capability units equipped with triggering mechanisms and evolutionary metadata, and enables continuous skill generation and optimization through a user-feedback-driven closed-loop process. In addition, by incorporating a three-stage skill matching strategy and a three-layer memory architecture, the framework supports dynamic task decomposition for complex problems and long-term capability accumulation. Experimental results based on real-world foreign trade scenarios demonstrate that, after integrating EvoAgent, GPT5.2 achieves significant improvements in professionalism, accuracy, and practical utility. Under a five-dimensional LLM-as-Judge evaluation protocol, the overall average score increases by approximately 28%. Further model transfer experiments indicate that the performance of an agent system depends not only on the intrinsic capabilities of the underlying model, but also on the degree of synergy between the model and the agent architecture.