arXiv: 2604.20133 · PDF
作者: Aimin Zhang, Jiajing Guo, Fuwei Jia, Chen Lv, Boyu Wang, Fangzheng Li
主分类: cs.AI · 全部: cs.AI
命中关键词: large language model, llm, agent, multi-agent, rag
TL;DR
EvoAgent 提出可进化的 LLM agent 框架,通过结构化技能学习与分层子 agent 委派,使 GPT5.2 在外贸场景综合评分提升约 28%。
核心观点
- 将 skill 建模为带触发机制和进化元数据的多文件结构化能力单元
- 用户反馈驱动闭环,实现技能的持续生成与优化
- 引入三阶段技能匹配 + 三层记忆架构,支持动态任务分解与长期能力累积
- agent 系统性能不仅取决于底座模型能力,还取决于模型与 agent 架构的协同度
方法
EvoAgent 框架由三部分组成:
- 结构化 skill 单元:多文件封装,带 trigger 和 evolutionary metadata
- 分层 sub-agent delegation:对复杂任务做动态分解并委派子 agent 处理
- 三阶段 skill matching 匹配当前任务到合适技能
- 三层 memory 架构:支撑长期能力累积
- 闭环进化:以用户反馈为信号驱动技能生成与迭代优化
实验
- 场景:真实外贸(foreign trade)业务
- 底座:GPT5.2,并做跨模型迁移实验
- 评估:LLM-as-Judge 五维打分协议(含 professionalism、accuracy、practical utility 等)
- 摘要未披露具体数据集规模、基线对比方法与样本量
结果
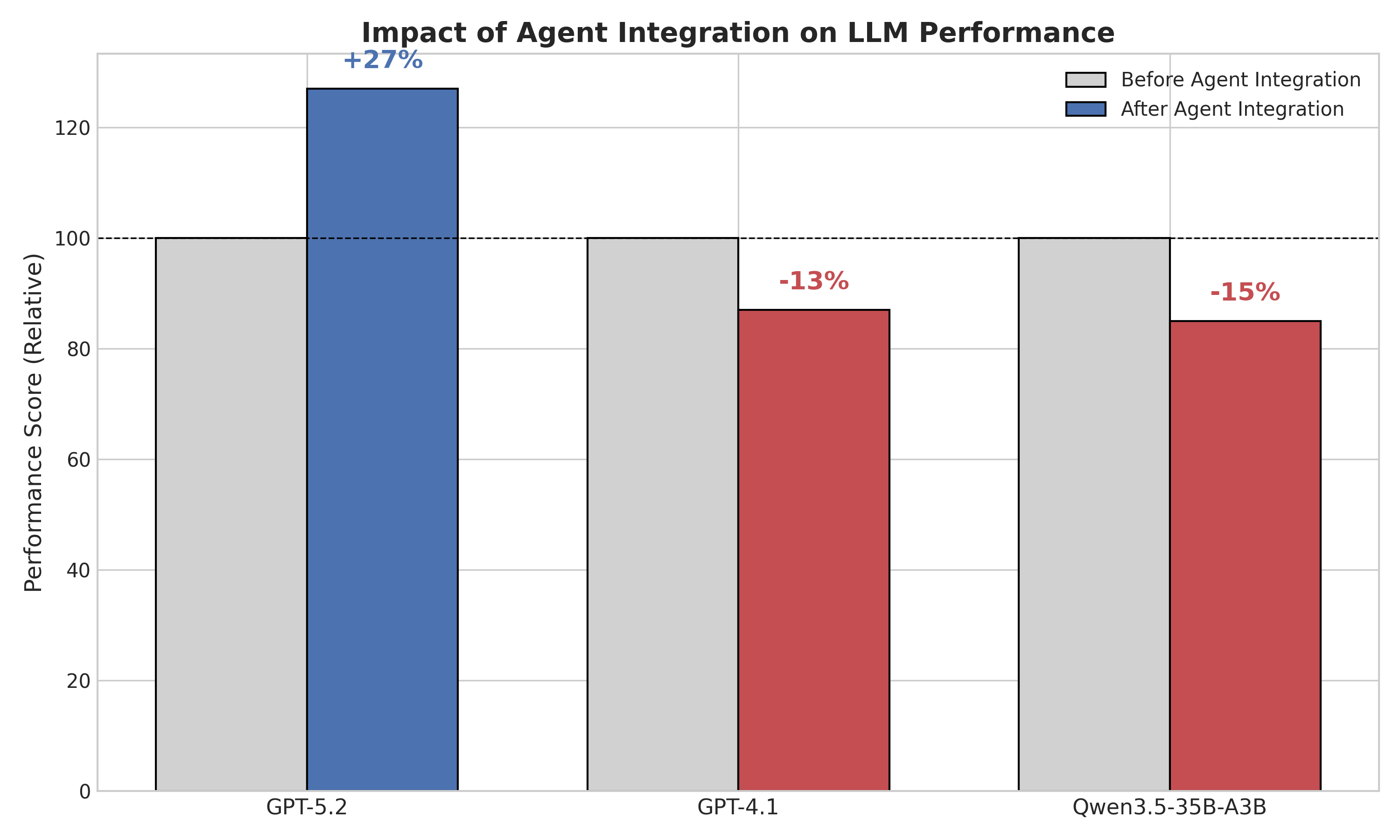
- GPT5.2 接入 EvoAgent 后,五维综合平均分提升约 28%
- 迁移实验显示不同模型获益幅度不同,佐证"模型-架构协同"的论点
- 具体分维度数字、置信区间、与其它 agent 框架的对比摘要中未给出,主张强度受限于 LLM-as-Judge 的主观性
为什么重要
对 agent 从业者而言,EvoAgent 给出了一条把"技能"当作一等公民、可版本化可进化的工程范式,而非只堆 prompt 或 tool。闭环反馈 + 分层 delegation 的组合对构建可长期积累能力的垂直领域 agent(如外贸、客服、法务)有借鉴价值,也提示选型时需同时评估底座模型与 agent 架构匹配度。
与已有工作的关系
- 技能学习延伸自 Voyager 等 skill library 思路,但强调结构化单元与进化元数据
- 分层委派与 AutoGen、MetaGPT、CAMEL 等 multi-agent 框架一脉相承
- 三层记忆延续 MemGPT、Generative Agents 的长期记忆研究
- LLM-as-Judge 评估沿用 MT-Bench、AlpacaEval 范式
尚未回答的问题
- 是否与 Voyager / AutoGen / MetaGPT 等有直接基线对比?
- 技能库规模扩大后是否出现匹配冲突或性能衰减?
- LLM-as-Judge 之外的客观指标(任务成功率、成本、延迟)表现如何?
- 外贸场景外(代码、科研、医疗)泛化性如何?
- 用户反馈闭环对反馈噪声/恶意反馈的鲁棒性未讨论
论文图表
图 1: Figure 1 (extracted from PDF)
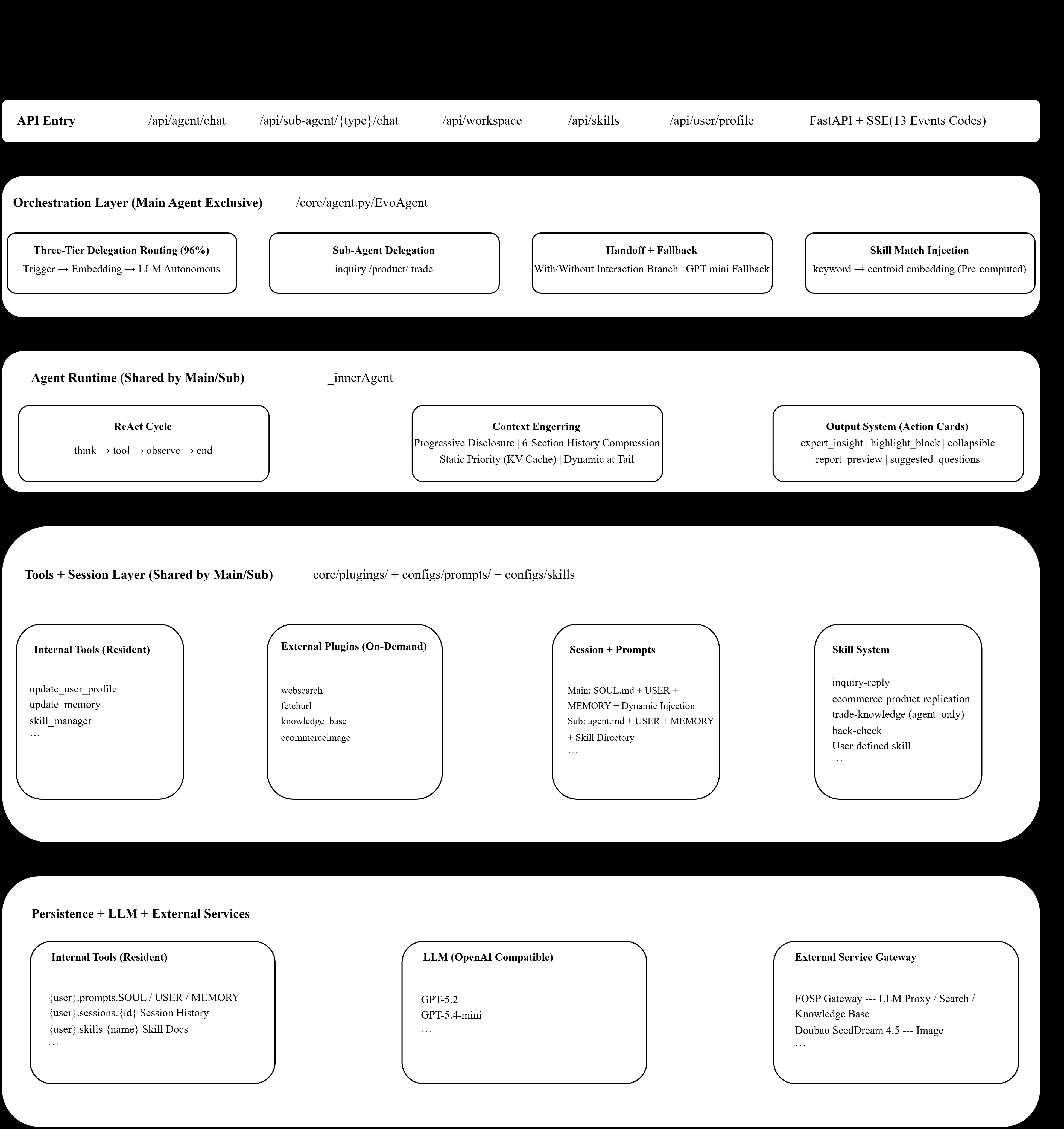
图 2: Figure 2 (extracted from PDF)
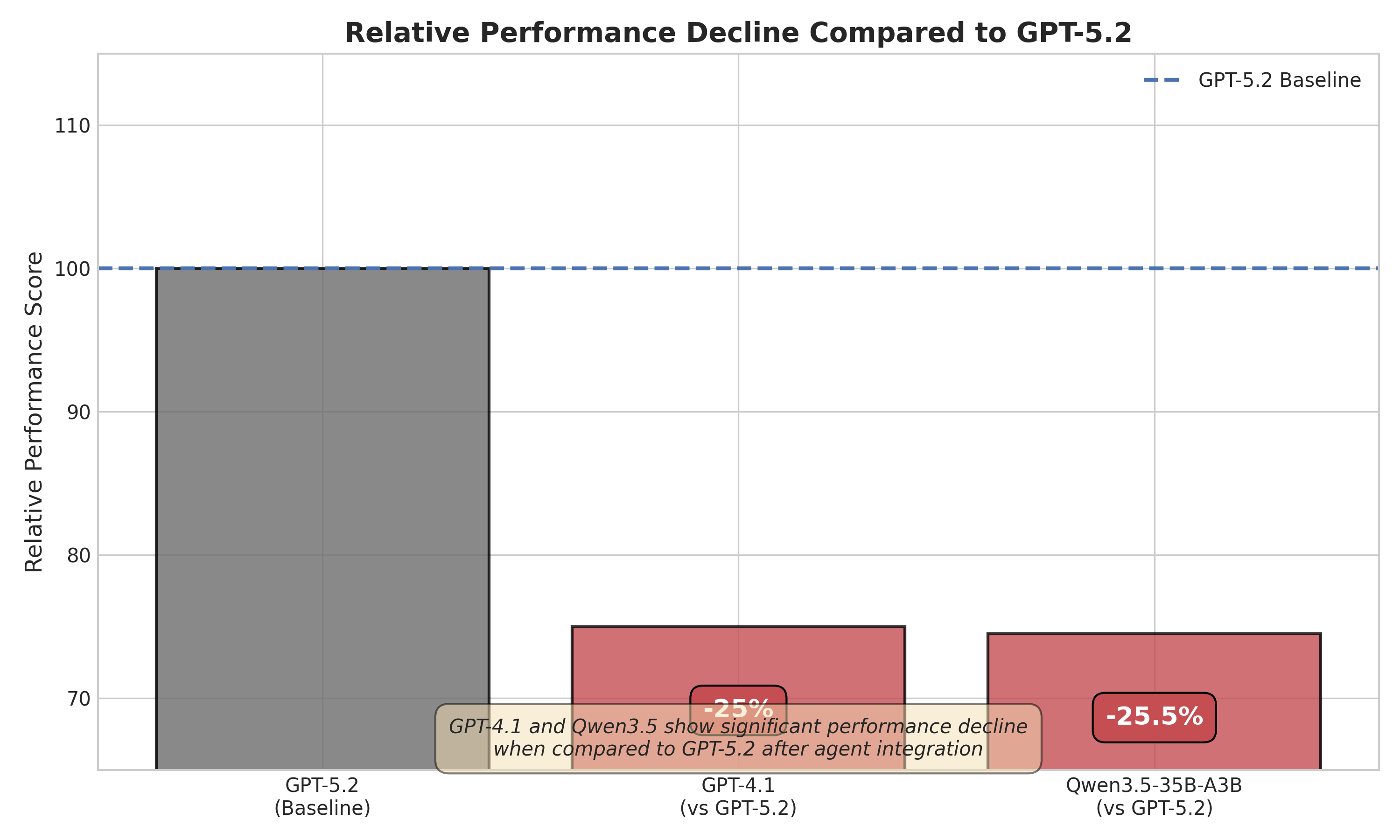
图 3: Figure 3 (extracted from PDF)
原始摘要
This paper proposes EvoAgent - an evolvable large language model (LLM) agent framework that integrates structured skill learning with a hierarchical sub-agent delegation mechanism. EvoAgent models skills as multi-file structured capability units equipped with triggering mechanisms and evolutionary metadata, and enables continuous skill generation and optimization through a user-feedback-driven closed-loop process. In addition, by incorporating a three-stage skill matching strategy and a three-layer memory architecture, the framework supports dynamic task decomposition for complex problems and long-term capability accumulation. Experimental results based on real-world foreign trade scenarios demonstrate that, after integrating EvoAgent, GPT5.2 achieves significant improvements in professionalism, accuracy, and practical utility. Under a five-dimensional LLM-as-Judge evaluation protocol, the overall average score increases by approximately 28%. Further model transfer experiments indicate that the performance of an agent system depends not only on the intrinsic capabilities of the underlying model, but also on the degree of synergy between the model and the agent architecture.