arXiv: 2604.21154 · PDF
Authors: Abhishek Dharmaratnakar, Srivaths Ranganathan, Anushree Sinha, Debanshu Das
Primary category: cs.AI · all: cs.AI
Matched keywords: large language model, agent, agentic, multi-agent, rag
TL;DR
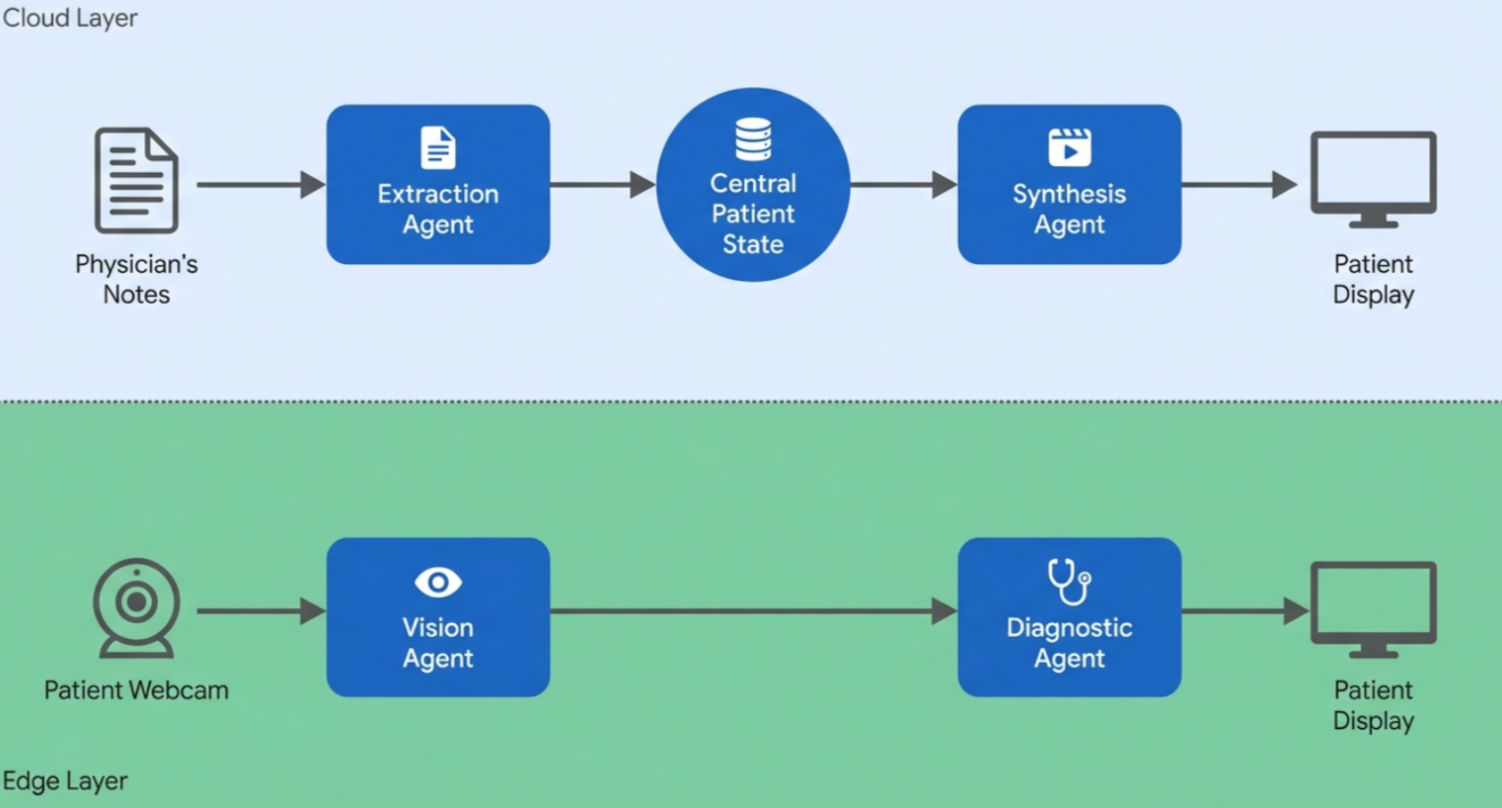
Proposes a four-agent system that parses clinical notes, generates patient-specific exercise videos, tracks poses in real time, and delivers corrective feedback for at-home physiotherapy. The paper is largely architectural, presenting a prototype and evaluation plan rather than clinical results.
Key Ideas
- Tele-rehabilitation gap stems from static video libraries and generic avatars ignoring patient-specific constraints.
- A Multi-Agent System (MAS) can close the loop by combining generative video, pose estimation, and autonomous feedback.
- Four specialized micro-agents cover extraction, synthesis, vision, and diagnostics.
- Unstructured clinical notes can be turned into kinematic constraints that condition downstream generation.
Approach
Four micro-agents pipeline:
- Clinical Extraction Agent — LLM parses medical notes into structured kinematic constraints (ROM, contraindications).
- Video Synthesis Agent — foundational video generation models produce personalized exercise demos conditioned on those constraints.
- Vision Processing Agent — MediaPipe-based real-time pose estimation of the patient.
- Diagnostic Feedback Agent — compares observed vs. prescribed kinematics and issues corrective instructions.
Prototype uses off-the-shelf LLMs plus MediaPipe; orchestration details between agents are only sketched.
Experiments
The abstract does not report experiments. Authors “outline a clinical evaluation plan” but provide no datasets, baselines, or quantitative metrics in the abstract.
Results
No headline numbers are reported. Claims are feasibility-level: the system architecture is presented and a prototype pipeline is described, but clinical efficacy, generation quality, and pose-correction accuracy are not quantified in the abstract.
Why It Matters
If realized, patient-specific generative video + agentic feedback could move tele-rehab beyond canned libraries, potentially improving home-exercise adherence and outcomes. For LLM/agent practitioners, it is another concrete template for MAS designs that couple generative media with perception and decision loops in a safety-sensitive domain.
Connections to Prior Work
- Multi-agent LLM orchestration frameworks (AutoGen, MetaGPT-style role decomposition).
- Text/image-to-video foundation models (Sora, VideoPoet, Stable Video Diffusion).
- Clinical NLP / information extraction from unstructured notes.
- Pose estimation tooling (MediaPipe, OpenPose) and vision-based rehab/coaching systems.
- Digital therapeutics and tele-rehabilitation literature on exercise adherence.
Open Questions
- How accurate is the clinical extraction on real, messy notes, and who verifies safety of derived constraints?
- Can current video generators produce anatomically faithful, constraint-respecting exercise demonstrations reliably?
- Latency and robustness of MediaPipe-based feedback across home camera setups.
- Failure modes and liability when the Diagnostic Agent issues incorrect corrections.
- Clinical validation: patient outcomes, adherence uplift, and comparison against therapist-supervised baselines.
- Privacy and on-device vs. cloud deployment trade-offs for video of patients at home.
Figures
Figure 1: Figure 1 (extracted from PDF)

Figure 2: Figure 2 (extracted from PDF)
Original abstract
At-home physiotherapy compliance remains critically low due to a lack of personalized supervision and dynamic feedback. Existing digital health solutions rely on static, pre-recorded video libraries or generic 3D avatars that fail to account for a patient’s specific injury limitations or home environment. In this paper, we propose a novel Multi-Agent System (MAS) architecture that leverages Generative AI and computer vision to close the tele-rehabilitation loop. Our framework consists of four specialized micro-agents: a Clinical Extraction Agent that parses unstructured medical notes into kinematic constraints; a Video Synthesis Agent that utilizes foundational video generation models to create personalized, patient-specific exercise videos; a Vision Processing Agent for real-time pose estimation; and a Diagnostic Feedback Agent that issues corrective instructions. We present the system architecture, detail the prototype pipeline using Large Language Models and MediaPipe, and outline our clinical evaluation plan. This work demonstrates the feasibility of combining generative media with agentic autonomous decision-making to scale personalized patient care safely and effectively.