arXiv: 2604.21154 · PDF
作者: Abhishek Dharmaratnakar, Srivaths Ranganathan, Anushree Sinha, Debanshu Das
主分类: cs.AI · 全部: cs.AI
命中关键词: large language model, agent, agentic, multi-agent, rag
TL;DR
提出一个多智能体框架,用生成式视频和实时姿态估计为居家物理治疗提供个性化训练与反馈。
核心观点
- 居家物理治疗依从性低,现有方案依赖静态视频或通用 3D avatar,无法适配患者伤情与环境。
- 将 Generative AI 与 computer vision 结合成 Multi-Agent System,可闭合 tele-rehabilitation 回路。
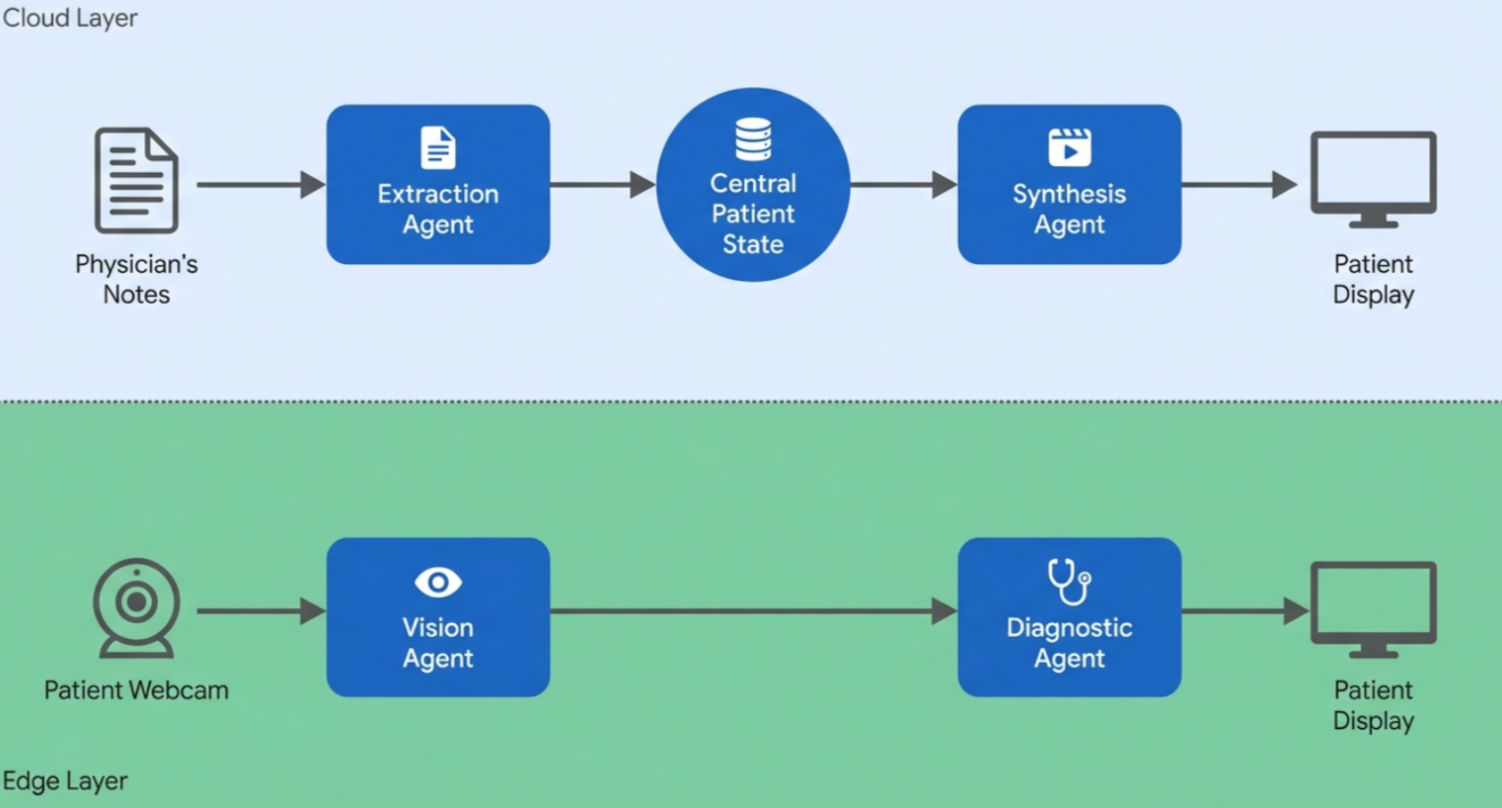
- 将临床笔记解析、视频合成、姿态识别、诊断反馈解耦为四个专用 micro-agent。
方法
框架由四个 agent 组成:
- Clinical Extraction Agent:用 LLM 解析非结构化医嘱为运动学约束。
- Video Synthesis Agent:调用 foundational video generation 模型,生成患者专属训练视频。
- Vision Processing Agent:基于 MediaPipe 做实时 pose estimation。
- Diagnostic Feedback Agent:根据姿态偏差下发纠正指令。 文中给出系统架构和原型 pipeline。
实验
论文仅描述原型 pipeline 与临床评估计划,未报告具体数据集、基线或量化指标。
结果
没有实验数据,作者只主张架构"可行"(feasibility),证据是系统搭建完成及评估方案的提出。
为什么重要
对 agent / LLM 从业者,展示了把生成式视频模型嵌入多智能体闭环的一种落地形态:LLM 做语义解析与决策,生成模型做内容合成,CV 做实时监测,agent 做编排。这种"感知—生成—反馈"范式对医疗、教育、体育等个性化指导场景具有参考价值,也暗示视频生成模型将成为 agent 工具链的一等公民。
与已有工作的关系
- Tele-rehabilitation 与 digital physiotherapy:超越静态视频库与通用 avatar 方案。
- Pose estimation:沿用 MediaPipe 系列工作。
- Generative video models:依赖 Sora / Runway 类 foundational 模型。
- Multi-Agent LLM Systems:延续 AutoGen、MetaGPT 等 micro-agent 分工思路。
尚未回答的问题
- 视频生成对特定伤情的医学准确性与安全性如何验证?
- 姿态纠正在复杂家居环境下的鲁棒性与延迟?
- 临床试验结果、依从性与疗效提升尚未给出。
- 如何防止 LLM 幻觉导致错误医学建议,责任与合规如何界定?
- 各 agent 间编排成本、隐私保护与在端侧部署的可行性未讨论。
论文图表
图 1: Figure 1 (extracted from PDF)

图 2: Figure 2 (extracted from PDF)
原始摘要
At-home physiotherapy compliance remains critically low due to a lack of personalized supervision and dynamic feedback. Existing digital health solutions rely on static, pre-recorded video libraries or generic 3D avatars that fail to account for a patient’s specific injury limitations or home environment. In this paper, we propose a novel Multi-Agent System (MAS) architecture that leverages Generative AI and computer vision to close the tele-rehabilitation loop. Our framework consists of four specialized micro-agents: a Clinical Extraction Agent that parses unstructured medical notes into kinematic constraints; a Video Synthesis Agent that utilizes foundational video generation models to create personalized, patient-specific exercise videos; a Vision Processing Agent for real-time pose estimation; and a Diagnostic Feedback Agent that issues corrective instructions. We present the system architecture, detail the prototype pipeline using Large Language Models and MediaPipe, and outline our clinical evaluation plan. This work demonstrates the feasibility of combining generative media with agentic autonomous decision-making to scale personalized patient care safely and effectively.