arXiv: 2604.20987 · PDF
Authors: Xiyang Wu, Zongxia Li, Guangyao Shi, Alexander Duffy, Tyler Marques, Matthew Lyle Olson, Tianyi Zhou, Dinesh Manocha
Primary category: cs.AI · all: cs.AI
Matched keywords: large language model, llm, agent, retrieval, rag, reasoning
TL;DR
COSPLAY is a co-evolution framework pairing an LLM decision agent with a learnable skill bank: the decision agent retrieves skills to act, while a skill-pipeline agent mines reusable skills from unlabeled rollouts. An 8B model beats four frontier LLM baselines by >25% average reward on six game environments.
Key Ideas
- Long-horizon agent quality hinges on discovering, retaining, and reusing structured skills across episodes.
- Co-evolve two agents: a decision agent and a skill-bank management agent.
- Skills are extracted from unlabeled rollouts and paired with contracts describing when/how to use them.
- Retrieval-guided action generation lets a small (8B) model outperform much larger frontier baselines.
Approach
Two interacting agents share a skill bank. The decision agent, given the current state, retrieves candidate skills from the bank to condition its action choice. A separate skill-pipeline agent mines trajectories from the decision agent’s rollouts to extract, refine, and update skill entries along with “contracts” (presumably preconditions/effects). The loop iterates: better skills improve decisions, better rollouts improve the bank.
Experiments
Six game environments spanning single-player long-horizon tasks and multi-player social-reasoning games. Base decision model: 8B LLM. Baselines: four frontier LLMs. Metric: average episode reward. Specific environments and frontier model names are not disclosed in the abstract.
Results
Headline: >25.1% average reward gain over four frontier baselines on single-player benchmarks; “competitive” on multi-player social reasoning. No per-game numbers, ablations, or compute costs are given in the abstract, so the robustness of the claim is hard to assess.
Why It Matters
Suggests that a modest open model plus a dynamically curated skill library can close the gap with frontier LLMs on long-horizon tasks, pointing toward memory/skill-centric agent designs rather than pure scaling — relevant for agent infra, game AI, and reinforcement-learning-from-rollouts workflows.
Connections to Prior Work
- Voyager’s lifelong skill library for Minecraft.
- Reflexion / self-refinement agents that learn from trajectories.
- Retrieval-augmented LLM agents and tool libraries (ToolLLM, MetaGPT).
- Skill discovery in hierarchical RL (options framework).
- LLM-as-policy work for text games (SPRING, AgentBench).
Open Questions
- How are skill “contracts” represented, verified, and prevented from drifting?
- Scaling behavior: does the gap narrow when baselines also get a skill bank?
- Transfer across environments vs. per-environment skill banks.
- Cost/latency of retrieval + skill maintenance at inference.
- Why only “competitive” on social reasoning — is skill abstraction ill-suited there?
- Reproducibility details (environments, frontier baselines, seeds) absent from the abstract.
Figures
Figure 1: Figure 1 (extracted from PDF)
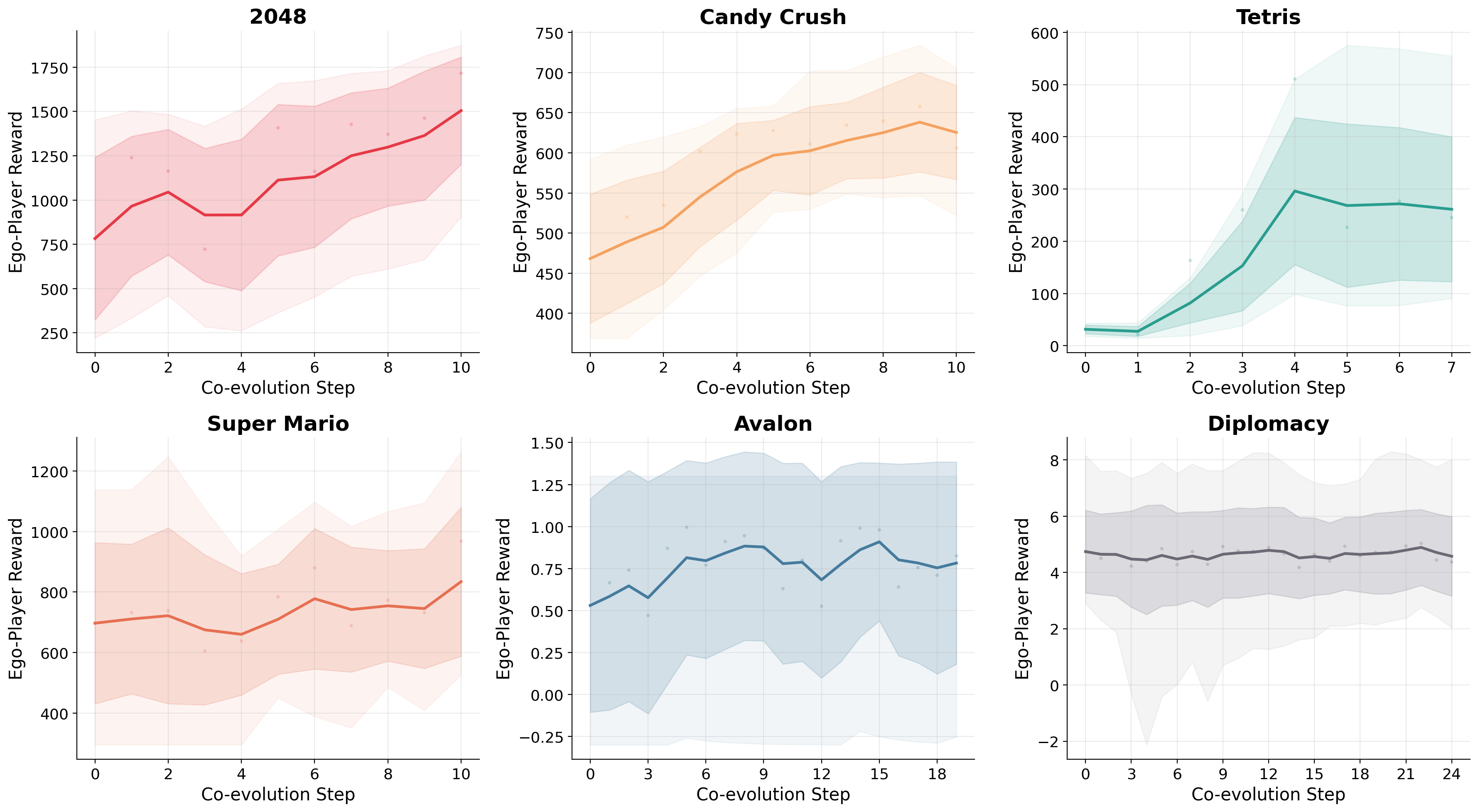
Figure 2: Figure 2 (extracted from PDF)
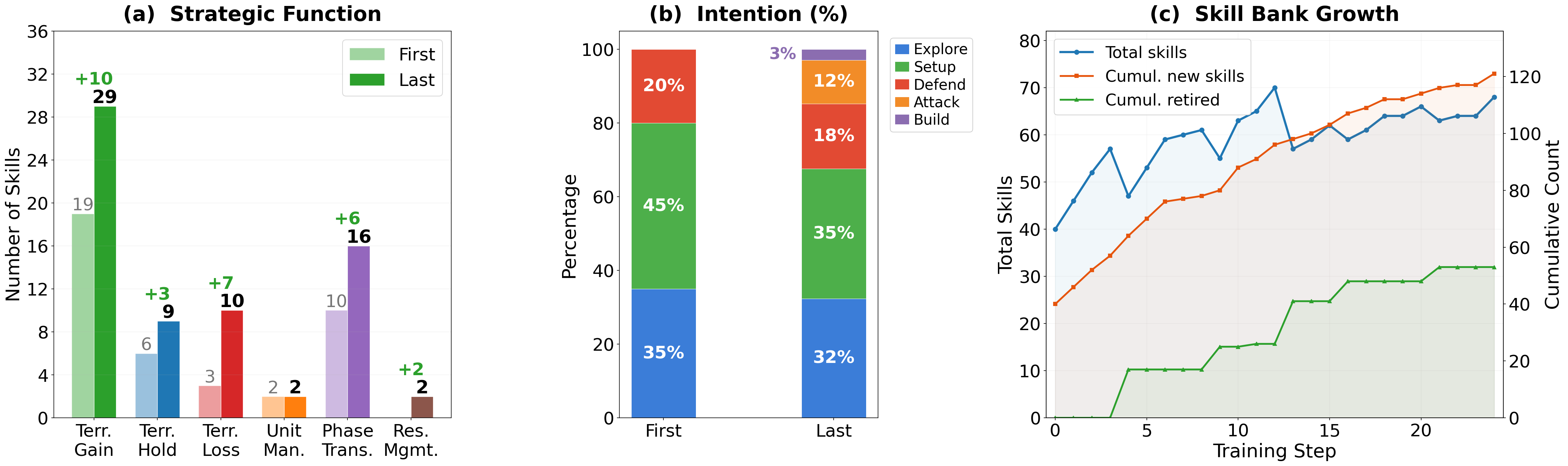
Figure 3: Figure 3 (extracted from PDF)

Original abstract
Long horizon interactive environments are a testbed for evaluating agents skill usage abilities. These environments demand multi step reasoning, the chaining of multiple skills over many timesteps, and robust decision making under delayed rewards and partial observability. Games are a good testbed for evaluating agent skill usage in environments. Large Language Models (LLMs) offer a promising alternative as game playing agents, but they often struggle with consistent long horizon decision making because they lack a mechanism to discover, retain, and reuse structured skills across episodes. We present COSPLAY, a co evolution framework in which an LLM decision agent retrieves skills from a learnable skill bank to guide action taking, while an agent managed skill pipeline discovers reusable skills from the agents unlabeled rollouts to form a skill bank. Our framework improves both the decision agent to learn better skill retrieval and action generation, while the skill bank agent continually extracts, refines, and updates skills together with their contracts. Experiments across six game environments show that COSPLAY with an 8B base model achieves over 25.1 percent average reward improvement against four frontier LLM baselines on single player game benchmarks while remaining competitive on multi player social reasoning games.