arXiv: 2604.20987 · PDF
作者: Xiyang Wu, Zongxia Li, Guangyao Shi, Alexander Duffy, Tyler Marques, Matthew Lyle Olson, Tianyi Zhou, Dinesh Manocha
主分类: cs.AI · 全部: cs.AI
命中关键词: large language model, llm, agent, retrieval, rag, reasoning
TL;DR
COSPLAY 提出 LLM 决策 agent 与可学习 skill bank 协同演化的框架,在长时序游戏任务中让 8B 模型显著超越前沿 LLM baseline。
核心观点
- 长时序交互环境需要跨 episode 发现、保留、复用结构化技能,现有 LLM agent 缺乏这种机制。
- 提出 COSPLAY:决策 agent 从 skill bank 检索技能指导动作,skill bank agent 从未标注 rollout 中抽取并精炼技能。
- 两个 agent 协同演化:决策端学更好的检索与动作生成,bank 端持续更新技能及其 contract。
方法
双 agent 协同演化框架。决策 agent 在每步从 learnable skill bank 中检索相关技能,用于指导 action 选择;skill pipeline agent 消化 agent 的 unlabeled rollout,发现可复用 skill 并形成带 contract 的条目存入 bank。训练过程中两者互相反馈:决策端的行为质量驱动 bank 的抽取/精炼,bank 的质量又改善决策端的检索与执行。
实验
- 环境:六个游戏环境,涵盖单人 game benchmark 与多人 social reasoning game。
- Base model:8B 参数 LLM。
- Baseline:四个 frontier LLM。
- 指标:average reward。
结果
在单人 game benchmark 上,COSPLAY (8B) 相对四个 frontier LLM baseline 平均 reward 提升超过 25.1%;在多人社交推理游戏上保持 competitive。摘要未给出具体逐环境数字或消融,因此对各组件贡献的可验证性有限。
为什么重要
对 LLM agent 基础设施而言,这指出一条用小模型 + 外部可学习技能库 打败大模型的路径:把"技能记忆"外化成可检索、可更新的结构化 bank,而非依赖参数内的隐式能力。对长时序决策、游戏 AI、以及需要 cross-episode skill reuse 的 agent 系统有直接借鉴价值。
与已有工作的关系
延续 Voyager 等"LLM + 技能库"工作(Minecraft 中技能抽取复用),但强调决策 agent 与 bank 的 co-evolution 而非单向写入。与 ReAct、Reflexion 等自反思 agent 相比,COSPLAY 把经验沉淀为可检索 skill 而非文本记忆。也可视为 retrieval-augmented decision making 在 long-horizon RL-like 场景的实例。
尚未回答的问题
- Skill contract 的具体格式与质量评估机制?
- Skill bank 规模增长后的检索效率与遗忘/去重策略?
- 是否泛化到非游戏的真实长时序任务(机器人、软件 agent)?
- 对更强 base model (>8B) 是否仍有同等增益,还是收益递减?
- 多人社交推理上"competitive"的具体差距与失败模式?
论文图表
图 1: Figure 1 (extracted from PDF)
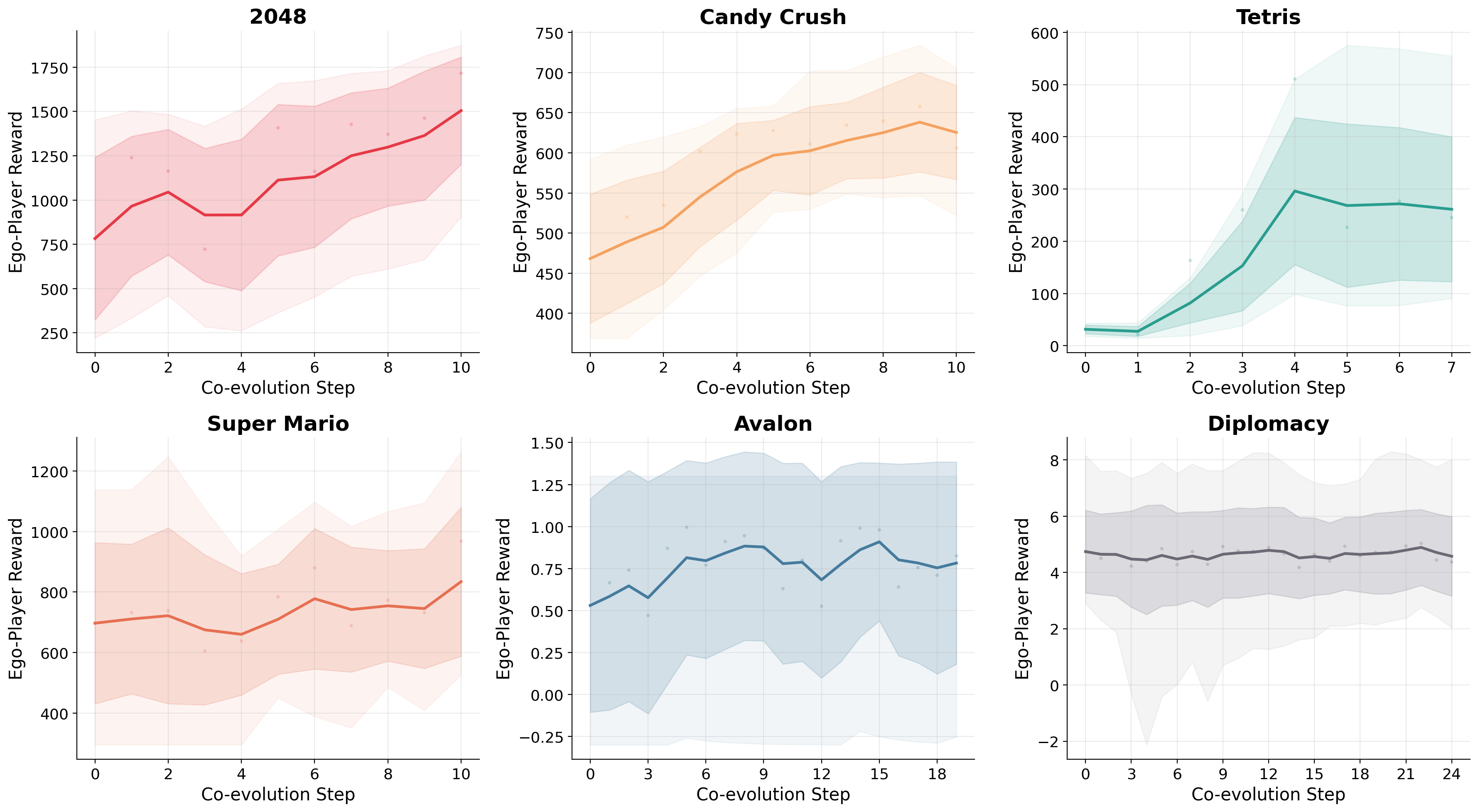
图 2: Figure 2 (extracted from PDF)
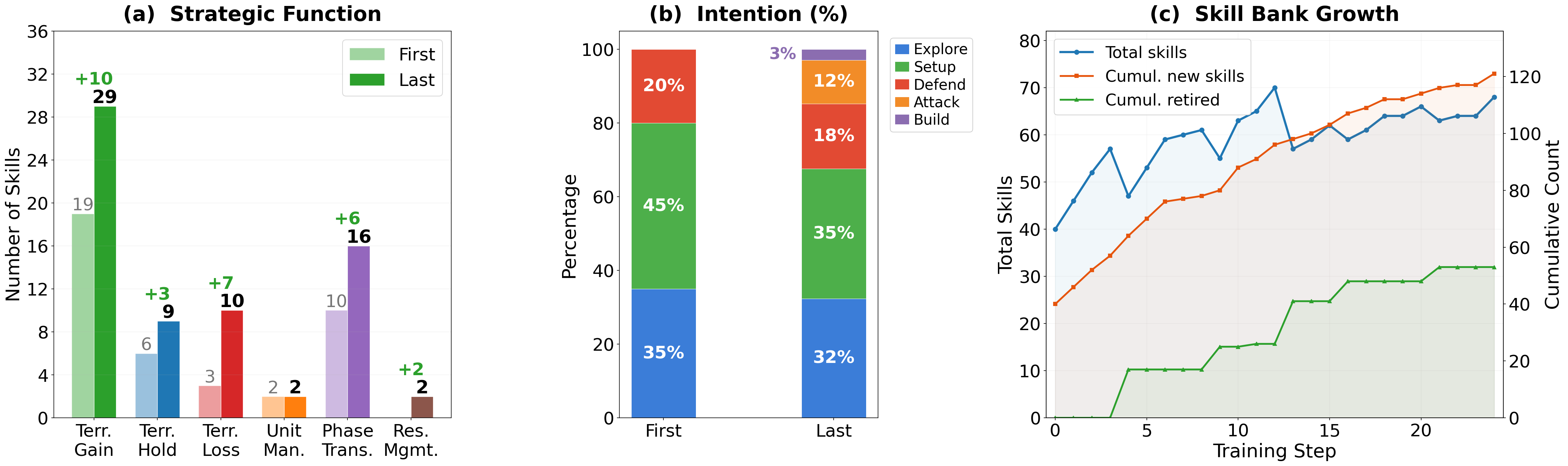
图 3: Figure 3 (extracted from PDF)

原始摘要
Long horizon interactive environments are a testbed for evaluating agents skill usage abilities. These environments demand multi step reasoning, the chaining of multiple skills over many timesteps, and robust decision making under delayed rewards and partial observability. Games are a good testbed for evaluating agent skill usage in environments. Large Language Models (LLMs) offer a promising alternative as game playing agents, but they often struggle with consistent long horizon decision making because they lack a mechanism to discover, retain, and reuse structured skills across episodes. We present COSPLAY, a co evolution framework in which an LLM decision agent retrieves skills from a learnable skill bank to guide action taking, while an agent managed skill pipeline discovers reusable skills from the agents unlabeled rollouts to form a skill bank. Our framework improves both the decision agent to learn better skill retrieval and action generation, while the skill bank agent continually extracts, refines, and updates skills together with their contracts. Experiments across six game environments show that COSPLAY with an 8B base model achieves over 25.1 percent average reward improvement against four frontier LLM baselines on single player game benchmarks while remaining competitive on multi player social reasoning games.