arXiv: 2604.21896 · PDF
Authors: Chee Wei Tan, Yuchen Wang, Shangxin Guo
Primary category: cs.AI · all: cs.AI
Matched keywords: large language model, llm, agent, agentic, rag, reasoning, fine-tun
TL;DR
Nemobot is an interactive agentic environment that uses LLMs to build and deploy game-playing agents across Shannon’s taxonomy, spanning dictionary-based, solvable, heuristic, and learning-based games, aiming toward self-programming AI.
Key Ideas
- Extends Shannon’s 1950 taxonomy of game-playing machines into an LLM era paradigm.
- Four game classes handled distinctly: dictionary, solvable, heuristic, learning-based.
- Agents combine minimax, crowd-sourced data, RLHF, and self-critique.
- Programmable environment for tool-augmented generation and fine-tuning.
- Positions user-in-the-loop customization as a route to self-programming.
Approach
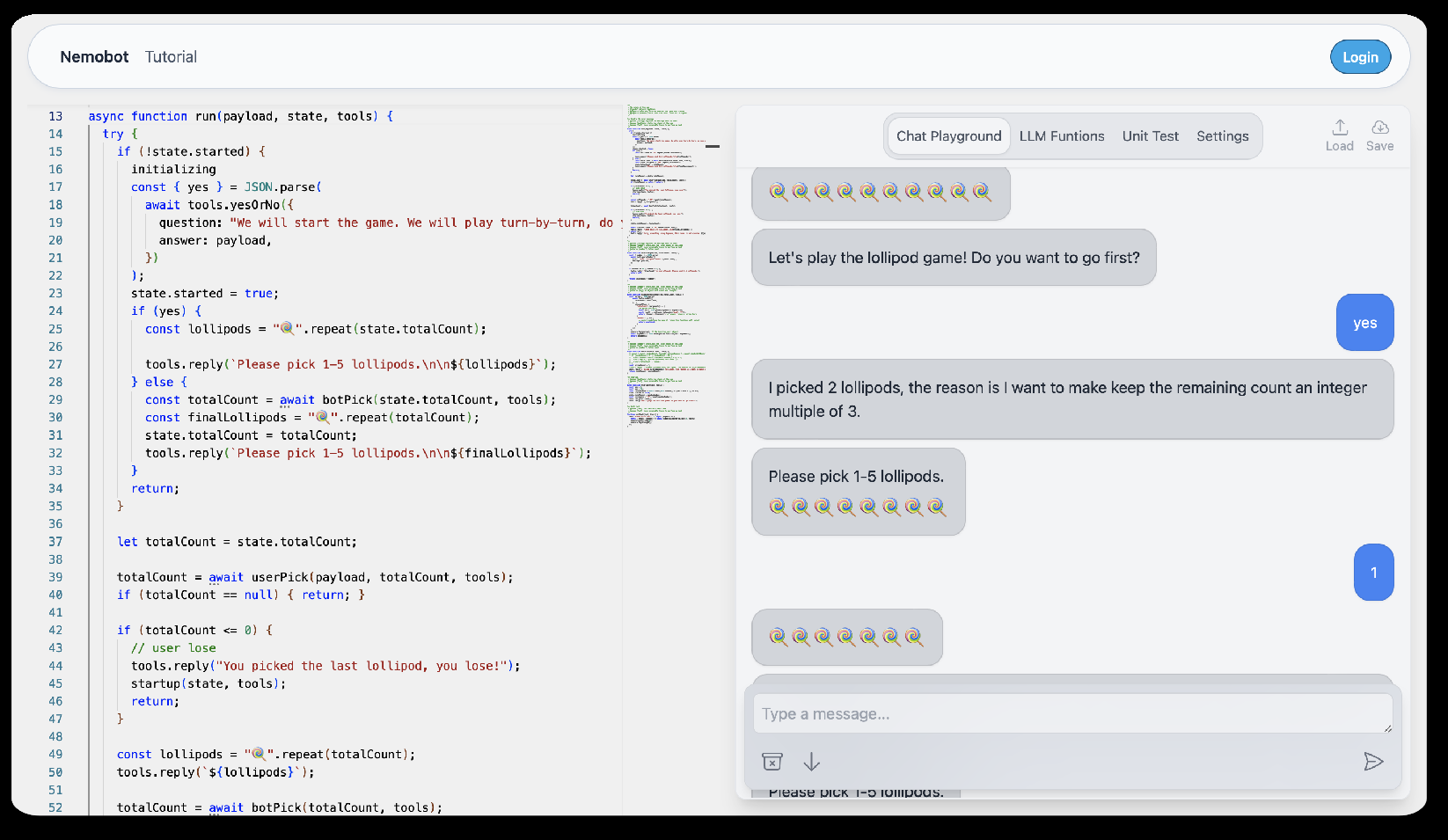
A chatbot-driven agentic engine routes game tasks by class: compressed state-action mappings for dictionary games; exact mathematical reasoning with human-readable explanations for solvable games; hybrid minimax-plus-crowd heuristics for heuristic games; RLHF with self-critique and imitation learning for learning-based games. Nemobot exposes these as programmable, tool-augmented workflows users can customize and fine-tune.
Experiments
The abstract does not specify datasets, baselines, or quantitative metrics. It only claims demonstrations across the four game classes and mentions strategic and role-playing games as illustrative domains. Evaluation details are thin.
Results
No headline numbers are reported in the abstract. Claims are qualitative: the system “demonstrates” capabilities across game classes and shows iterative refinement via human feedback. Strength of evidence cannot be judged from the abstract alone.
Why It Matters
For agent and LLM practitioners, it offers a unifying mental model for matching LLM techniques (retrieval, symbolic reasoning, heuristic search, RLHF) to problem structure. The programmable sandbox could become a teaching tool for strategy design and a testbed for tool-augmented agents and self-improving pipelines.
Connections to Prior Work
- Shannon’s 1950 taxonomy of chess-playing machines.
- Classical minimax and alpha-beta search.
- AlphaGo / AlphaZero lineage of learning-based game agents.
- RLHF and self-critique / self-refine literature.
- Tool-augmented LLMs (ReAct, Toolformer) and agentic frameworks.
- Voyager-style self-programming and skill-library agents.
Open Questions
- What quantitative benchmarks validate each game class?
- How does Nemobot compare against specialized engines (Stockfish, AlphaZero, MuZero)?
- How is “self-programming” operationalized and measured beyond iterative refinement?
- Scalability to partial-information or multi-agent games?
- Cost, latency, and reproducibility of LLM-in-the-loop strategies?
- Safety and reward-hacking risks under self-critique loops?
Figures
Figure 1: Figure 1 (extracted from PDF)
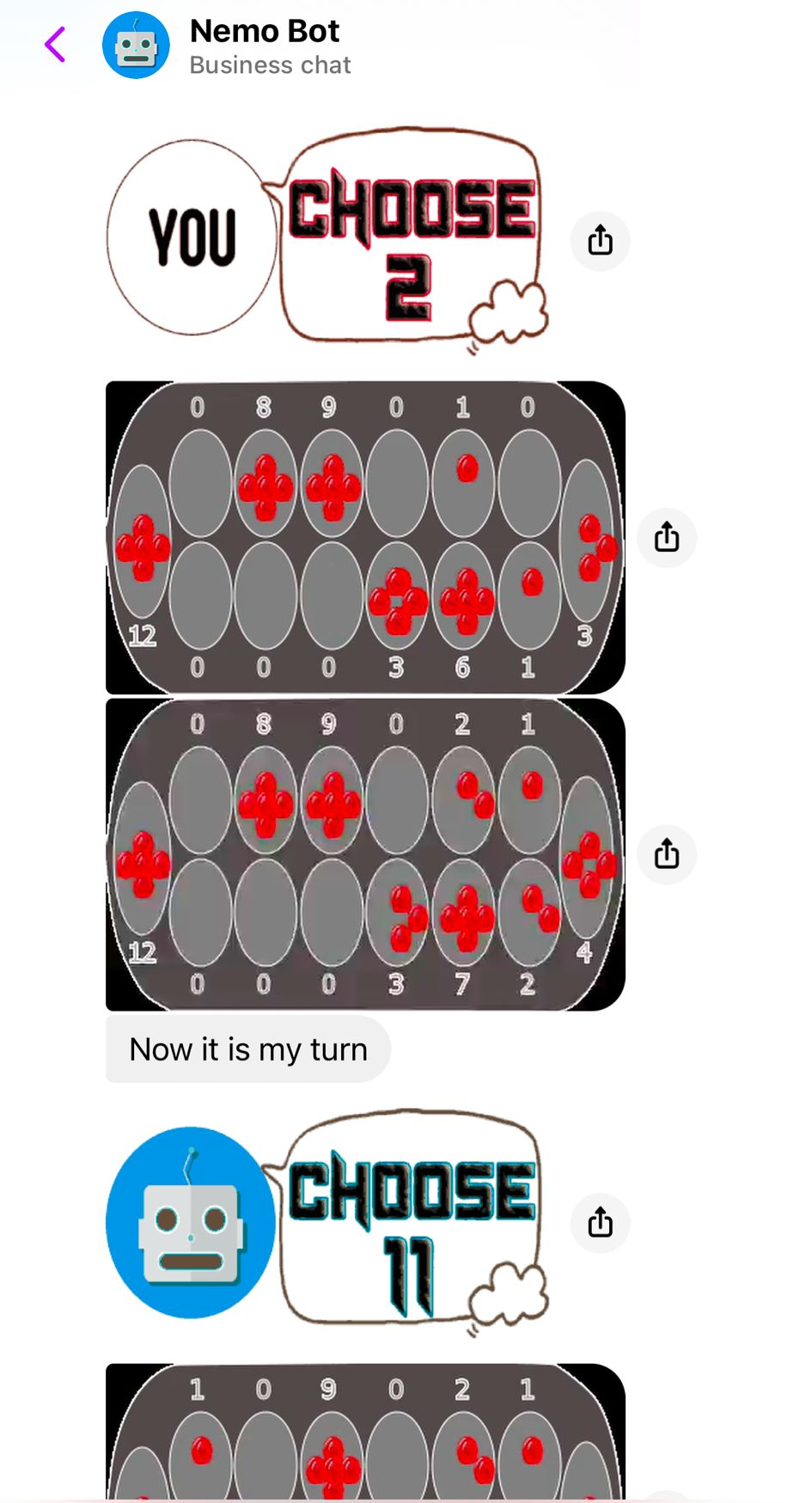
Figure 2: Figure 2 (extracted from PDF)

Figure 3: Figure 3 (extracted from PDF)
Original abstract
This paper introduces a new paradigm for AI game programming, leveraging large language models (LLMs) to extend and operationalize Claude Shannon’s taxonomy of game-playing machines. Central to this paradigm is Nemobot, an interactive agentic engineering environment that enables users to create, customize, and deploy LLM-powered game agents while actively engaging with AI-driven strategies. The LLM-based chatbot, integrated within Nemobot, demonstrates its capabilities across four distinct classes of games. For dictionary-based games, it compresses state-action mappings into efficient, generalized models for rapid adaptability. In rigorously solvable games, it employs mathematical reasoning to compute optimal strategies and generates human-readable explanations for its decisions. For heuristic-based games, it synthesizes strategies by combining insights from classical minimax algorithms (see, e.g., shannon1950chess) with crowd-sourced data. Finally, in learning-based games, it utilizes reinforcement learning with human feedback and self-critique to iteratively refine strategies through trial-and-error and imitation learning. Nemobot amplifies this framework by offering a programmable environment where users can experiment with tool-augmented generation and fine-tuning of strategic game agents. From strategic games to role-playing games, Nemobot demonstrates how AI agents can achieve a form of self-programming by integrating crowdsourced learning and human creativity to iteratively refine their own logic. This represents a step toward the long-term goal of self-programming AI.