arXiv: 2604.21896 · PDF
作者: Chee Wei Tan, Yuchen Wang, Shangxin Guo
主分类: cs.AI · 全部: cs.AI
命中关键词: large language model, llm, agent, agentic, rag, reasoning, fine-tun
TL;DR
论文提出 Nemobot,一个基于 LLM 的交互式 agentic 游戏编程环境,按 Shannon 博弈机分类法在四类游戏中构建可自我精炼的策略 agent。
核心观点
- 将 Shannon 的博弈机分类法用 LLM 重新"操作化",作为 AI 游戏编程新范式。
- 提出 Nemobot:一个可编程、交互式的 agentic 工程环境,用户可创建、定制、部署 LLM 游戏 agent。
- 覆盖四类游戏(字典型、可严格求解型、启发式、学习型),展示不同策略生成路径。
- 通过众包学习 + 人类创造力迭代精炼 agent 逻辑,指向"自编程 AI"长期目标。
方法
- Dictionary-based games:把 state-action 映射压缩成泛化模型,便于快速适配。
- Rigorously solvable games:用数学推理算最优策略,并生成人类可读解释。
- Heuristic-based games:结合经典 minimax(Shannon 1950)与众包数据合成策略。
- Learning-based games:用 RLHF + self-critique,以试错和模仿学习迭代精炼。
- Nemobot 提供 tool-augmented generation 与 fine-tuning 的可编程接口。
实验
摘要未给出具体数据集、基线或量化指标,只说"跨四类游戏"进行了 demo 式展示。
结果
摘要无具体数字或对照实验结论,只是定性声明 LLM 能在四类游戏里生成可解释策略并迭代改进。
为什么重要
对 agent / LLM 从业者,它示范了一个按"问题结构"选择推理路径(压缩 / 精确求解 / 启发式 / RL)的 agentic 设计模板,并把人类教学与 crowdsourcing 纳入 agent 自我改进循环,适合教育与策略 agent 原型开发。
与已有工作的关系
- 延续 Shannon 1950 博弈机分类与 minimax 传统。
- 与 RLHF、self-critique、tool-use agent(如 ReAct、Voyager 等 LLM agent 工作)同脉。
- 在"交互式 AI 教学/游戏平台"上与 OpenAI Gym、MiniHack、LLM-as-coach 类工作相邻。
尚未回答的问题
- 缺定量评测:与专用求解器、AlphaZero 类方法相比胜率 / 样本效率如何?
- 四类分类对复杂/混合型游戏(部分可观测、多智能体)是否仍成立?
- “自编程"闭环在多轮迭代后是否稳定,会不会退化或过拟合众包数据?
- 安全与版权:众包策略数据来源与偏差如何治理?
论文图表
图 1: Figure 1 (extracted from PDF)
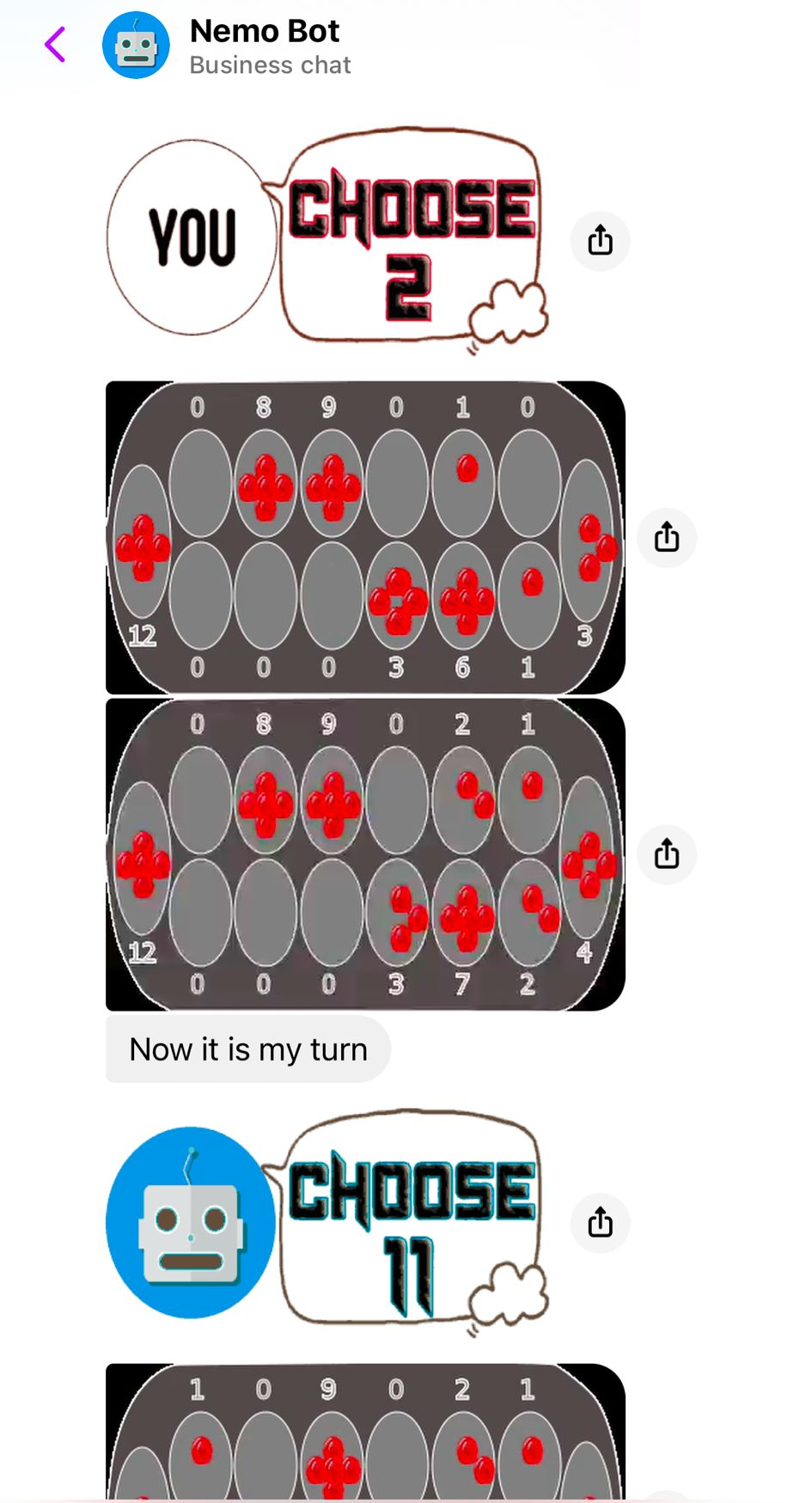
图 2: Figure 2 (extracted from PDF)

图 3: Figure 3 (extracted from PDF)
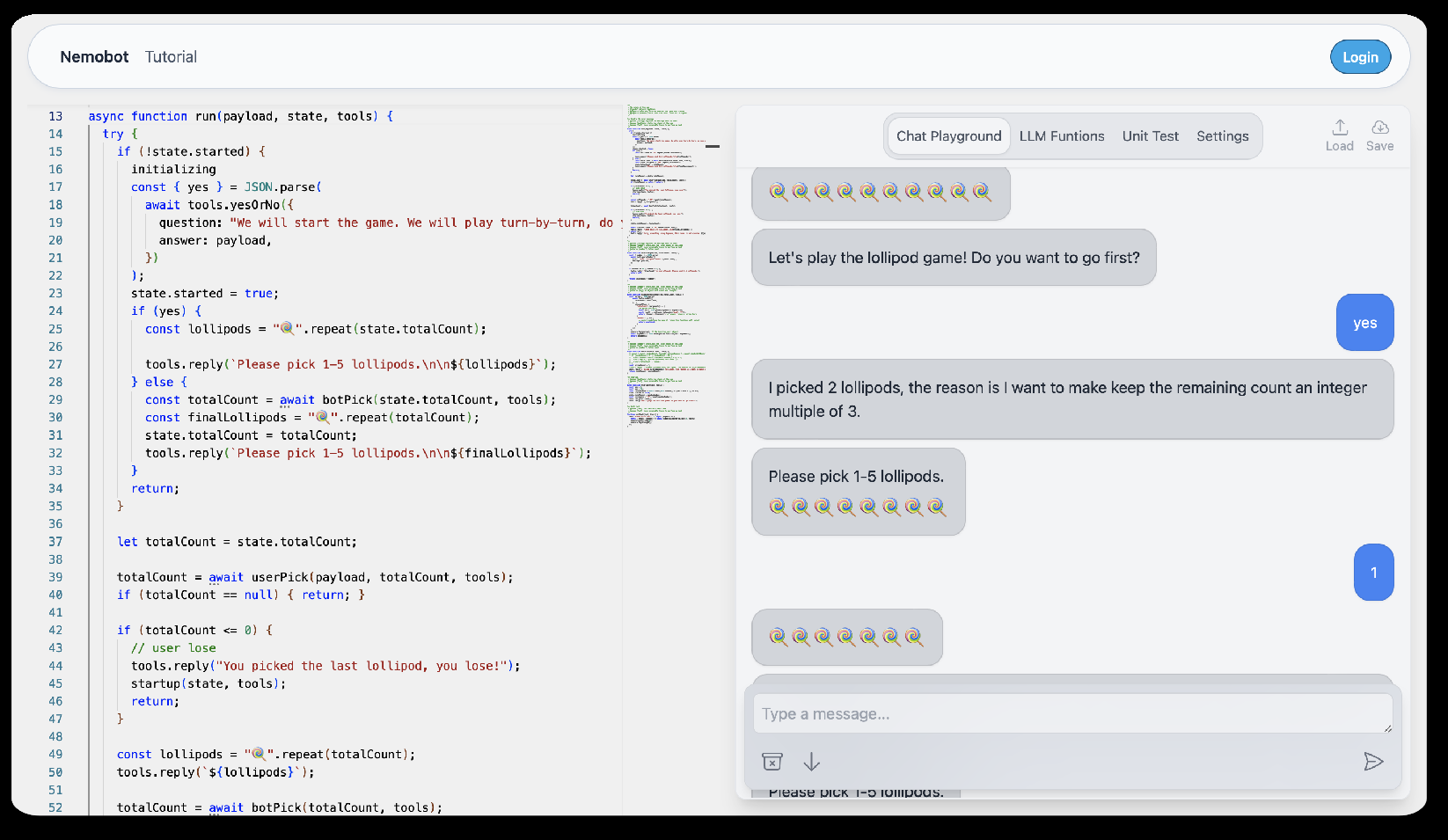
原始摘要
This paper introduces a new paradigm for AI game programming, leveraging large language models (LLMs) to extend and operationalize Claude Shannon’s taxonomy of game-playing machines. Central to this paradigm is Nemobot, an interactive agentic engineering environment that enables users to create, customize, and deploy LLM-powered game agents while actively engaging with AI-driven strategies. The LLM-based chatbot, integrated within Nemobot, demonstrates its capabilities across four distinct classes of games. For dictionary-based games, it compresses state-action mappings into efficient, generalized models for rapid adaptability. In rigorously solvable games, it employs mathematical reasoning to compute optimal strategies and generates human-readable explanations for its decisions. For heuristic-based games, it synthesizes strategies by combining insights from classical minimax algorithms (see, e.g., shannon1950chess) with crowd-sourced data. Finally, in learning-based games, it utilizes reinforcement learning with human feedback and self-critique to iteratively refine strategies through trial-and-error and imitation learning. Nemobot amplifies this framework by offering a programmable environment where users can experiment with tool-augmented generation and fine-tuning of strategic game agents. From strategic games to role-playing games, Nemobot demonstrates how AI agents can achieve a form of self-programming by integrating crowdsourced learning and human creativity to iteratively refine their own logic. This represents a step toward the long-term goal of self-programming AI.