arXiv: 2604.21957 · PDF
Authors: Aladin Djuhera, Haris Gacanin, Holger Boche
Primary category: cs.IT · all: cs.AI, cs.IT, cs.LG, eess.SP
Matched keywords: large language model, llm, inference, attention, transformer, throughput, latency
TL;DR
MambaCSP replaces Transformer/LLM backbones for channel state prediction with a hybrid Mamba SSM augmented by lightweight patch-mixer attention, achieving 9–12% accuracy gains and up to 3× throughput over LLM baselines in MISO-OFDM simulations.
Key Ideas
- Pure attention-based CSP suffers quadratic sequence cost, limiting real-time wireless use.
- Selective SSMs (Mamba) offer linear-time alternatives but lack long-range cross-token mixing.
- Hybrid design: Mamba backbone + periodic patch-mixer attention layers recovers global context cheaply.
- Hardware efficiency (VRAM, latency, throughput) is treated as a first-class objective alongside accuracy.
Approach
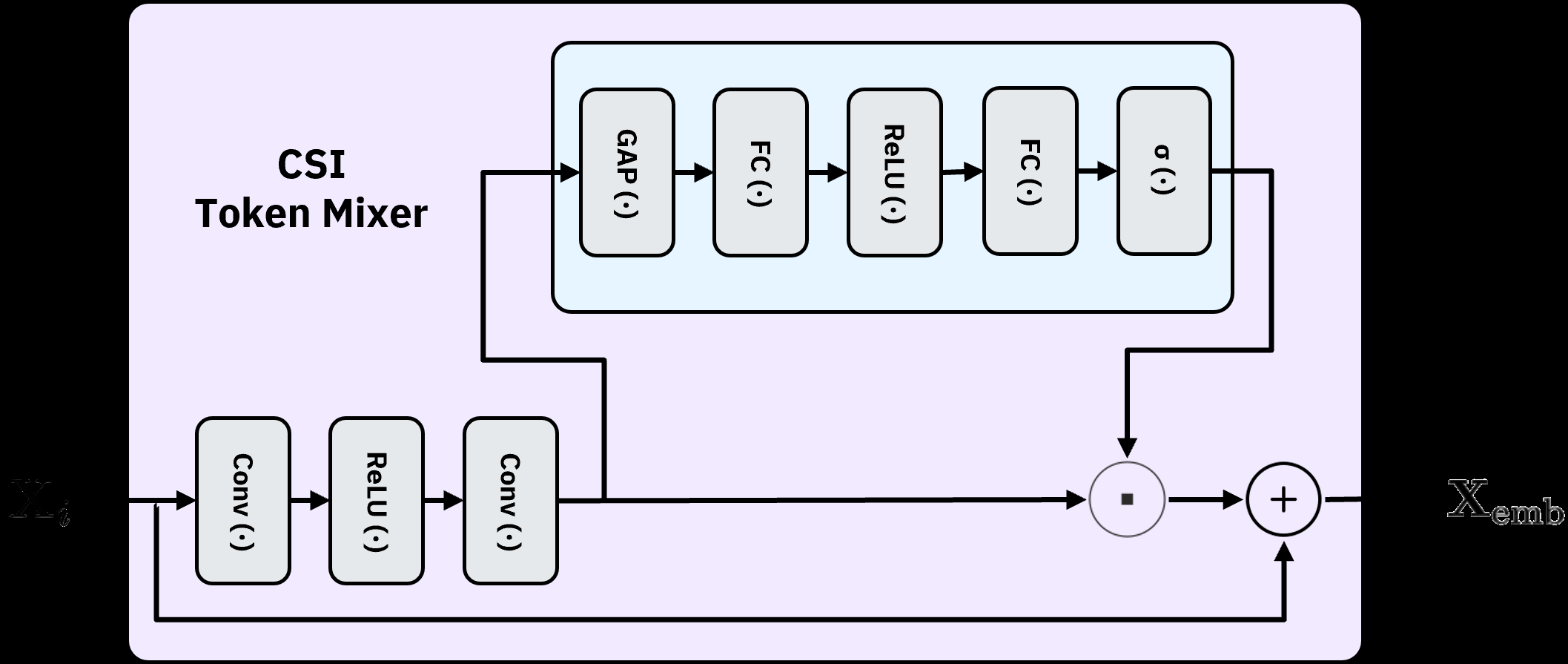
MambaCSP swaps the LLM prediction backbone for a linear-time Mamba selective SSM operating on CSI sequences. Because pure SSMs capture mostly local dependencies, the authors periodically insert lightweight “patch-mixer” attention layers that inject cross-token interactions across patched CSI tokens. The architecture thus alternates SSM blocks (cheap sequential mixing) with sparse attention (global context), targeting MISO-OFDM channel prediction.
Experiments
- Setting: MISO-OFDM wireless channel simulations.
- Task: channel state information (CSI) sequence prediction.
- Baselines: LLM/transformer-based CSP predictors.
- Metrics: prediction accuracy, throughput, VRAM usage, inference latency.
- Specific datasets, SNR ranges, and model scales are not detailed in the abstract.
Results
- Prediction accuracy: +9–12% over LLM-based approaches.
- Throughput: up to 3.0× higher.
- Memory: 2.6× lower VRAM.
- Latency: 2.9× faster inference. Claims are internally consistent; abstract does not report ablations isolating the patch-mixer contribution.
Why It Matters
For AI-native RAN and wireless infra, this suggests SSM-based predictors can replace heavyweight LLM CSP stacks on edge/base-station hardware, enabling low-latency beamforming and link adaptation without GPU-scale budgets. Also a useful datapoint for practitioners evaluating Mamba+sparse-attention hybrids in other long-sequence signal domains.
Connections to Prior Work
- Mamba / selective state space models (S4, S5, Mamba) for long-sequence modeling.
- Transformer- and LLM-based CSI/channel predictors (e.g., LLM4CP-style approaches).
- Hybrid SSM-attention architectures (Jamba, Zamba, Griffin) that mix linear-time cores with sparse attention.
- Patch-based tokenization from time-series forecasting (PatchTST).
- Classical CSI prediction via Kalman filters, AR models, and RNN/LSTM baselines.
Open Questions
- How does MambaCSP perform under real hardware measurements vs. simulation, and on MIMO (not just MISO)?
- Sensitivity to mobility, Doppler, and non-stationary channels.
- Ablation: how much of the gain is from Mamba vs. the patch-mixer attention?
- Scaling behavior with longer CSI horizons and larger antenna arrays.
- Robustness to quantization and deployment on actual RAN accelerators.
Figures
Figure 1: Figure 1 (extracted from PDF)
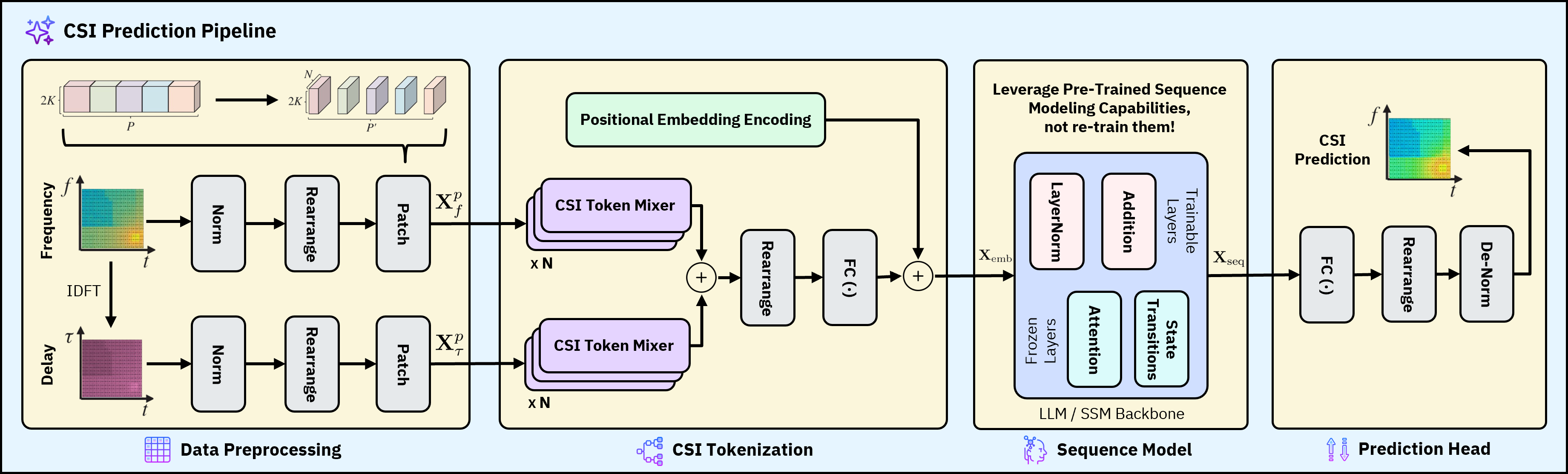
Figure 2: Figure 2 (extracted from PDF)
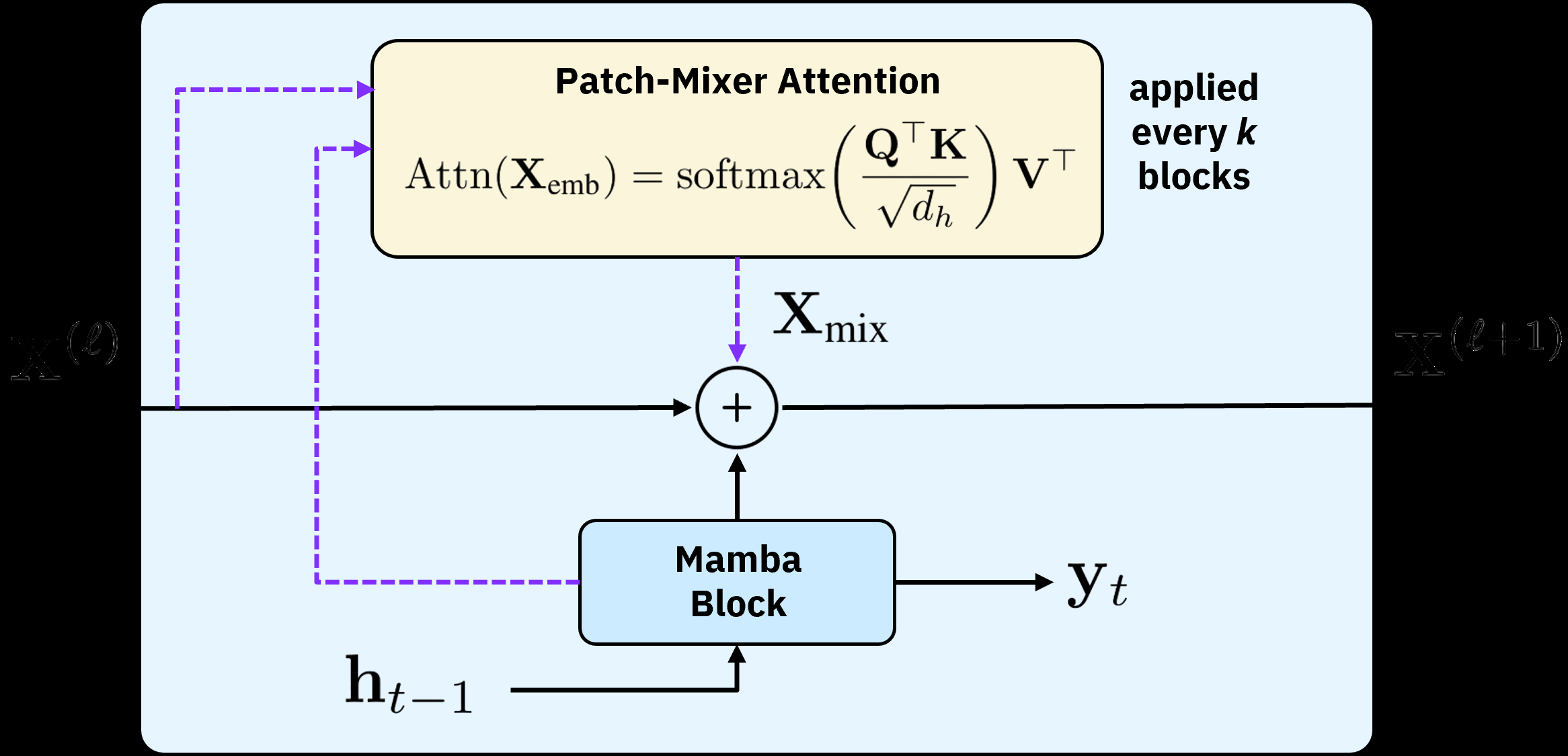
Figure 3: Figure 3 (extracted from PDF)
Original abstract
Recent works have demonstrated that attention-based transformer and large language model (LLM) architectures can achieve strong channel state prediction (CSP) performance by capturing long-range temporal dependencies across channel state information (CSI) sequences. However, these models suffer from quadratic scaling in sequence length, leading to substantial computational cost, memory consumption, and inference latency, which limits their applicability in real-time and resource-constrained wireless deployments. In this paper, we investigate whether selective state space models (SSMs) can serve as a hardware-efficient alternative for CSI prediction. We propose MambaCSP, a hybrid-attention SSM architecture that replaces LLM-based prediction backbones with a linear-time Mamba model. To overcome the local-only dependencies of pure SSMs, we introduce lightweight patch-mixer attention layers that periodically inject cross-token attentions, helping with long-context CSI prediction. Extensive MISO-OFDM simulations show that MambaCSP improves prediction accuracy over LLM-based approaches by 9-12%, while delivering up to 3.0x higher throughput, 2.6x lower VRAM usage, and 2.9x faster inference. Our results demonstrate that hybrid state space architectures provide a promising direction for scalable and hardware-efficient AI-native CSI prediction in future wireless networks.