arXiv: 2604.21957 · PDF
作者: Aladin Djuhera, Haris Gacanin, Holger Boche
主分类: cs.IT · 全部: cs.AI, cs.IT, cs.LG, eess.SP
命中关键词: large language model, llm, inference, attention, transformer, throughput, latency
TL;DR
MambaCSP 用混合注意力的 selective SSM 替代 LLM 做信道状态预测,精度提升 9-12% 的同时吞吐快 3 倍、显存降 2.6 倍。
核心观点
- Transformer/LLM 做 CSP 精度高但受限于序列长度的二次复杂度,难以部署到实时无线场景。
- Selective SSM(Mamba)提供线性时间替代,但纯 SSM 只有局部依赖。
- 周期性注入轻量 patch-mixer attention,可以补齐长上下文建模能力。
- 在 MISO-OFDM 仿真下同时取得精度与硬件效率双优。
方法
提出 MambaCSP:以线性时间的 Mamba 作为预测主干,替换原本基于 LLM 的 backbone;在 SSM 栈中周期性插入轻量的 patch-mixer attention 层,用于跨 token 的交互,从而在保持线性开销的同时捕获长程 CSI 依赖。整体为 hybrid-attention SSM 架构,面向 CSI 序列预测。
实验
场景:MISO-OFDM 仿真下的 CSI 预测任务。基线:基于 attention/LLM 的 CSP 方法。指标:预测精度、吞吐率、VRAM 占用、推理延迟。摘要未给出具体数据集名称与超参。
结果
相较 LLM-based 方法,精度提升 9-12%;吞吐最高 3.0×,VRAM 占用降至 1/2.6,推理速度提升 2.9×。摘要未披露绝对数值与置信区间,主张成立性依赖作者仿真设置。
为什么重要
对无线 AI-native 基础设施从业者,提供了在边缘/实时约束下替代 Transformer CSP 的可行路径:保留长上下文能力的同时显著降低显存与延迟,利于大规模 MIMO/OFDM 部署。也为 SSM 在信号处理领域的落地提供样例。
与已有工作的关系
延续 Mamba / selective SSM 线性时序建模方向;对标 LLM4CSI、Transformer-based CSP 工作;patch-mixer attention 思想接近 Hybrid Mamba-Attention(如 Jamba、Zamba)在 NLP 领域的混合架构,只是迁移到 wireless CSI 场景。
尚未回答的问题
- 真实硬件(FPGA/基带芯片)落地与能耗表现如何?
- 在 MIMO、mmWave、高移动性等更复杂信道下的泛化性?
- patch-mixer 注入频率、位置的设计空间是否已充分探索?
- 与量化、蒸馏等压缩技术的组合收益?
- 数据集规模与分布外鲁棒性尚未公开。
论文图表
图 1: Figure 1 (extracted from PDF)
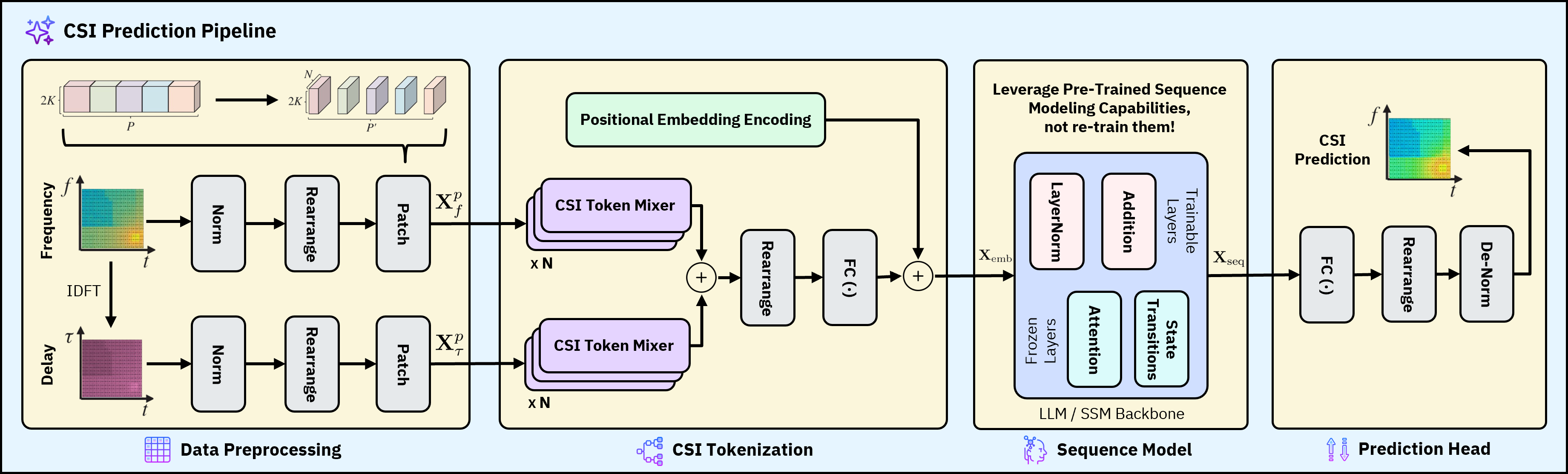
图 2: Figure 2 (extracted from PDF)
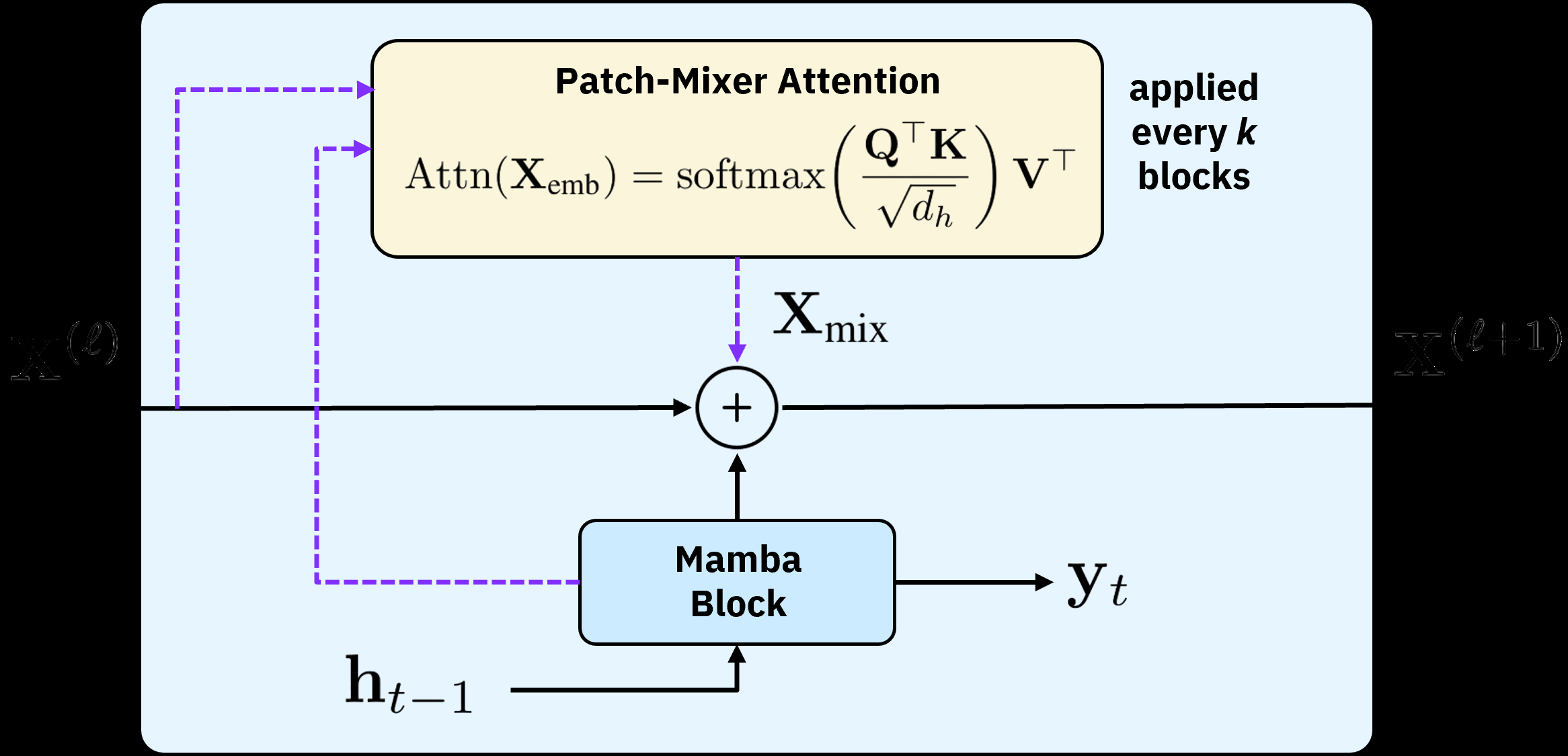
图 3: Figure 3 (extracted from PDF)
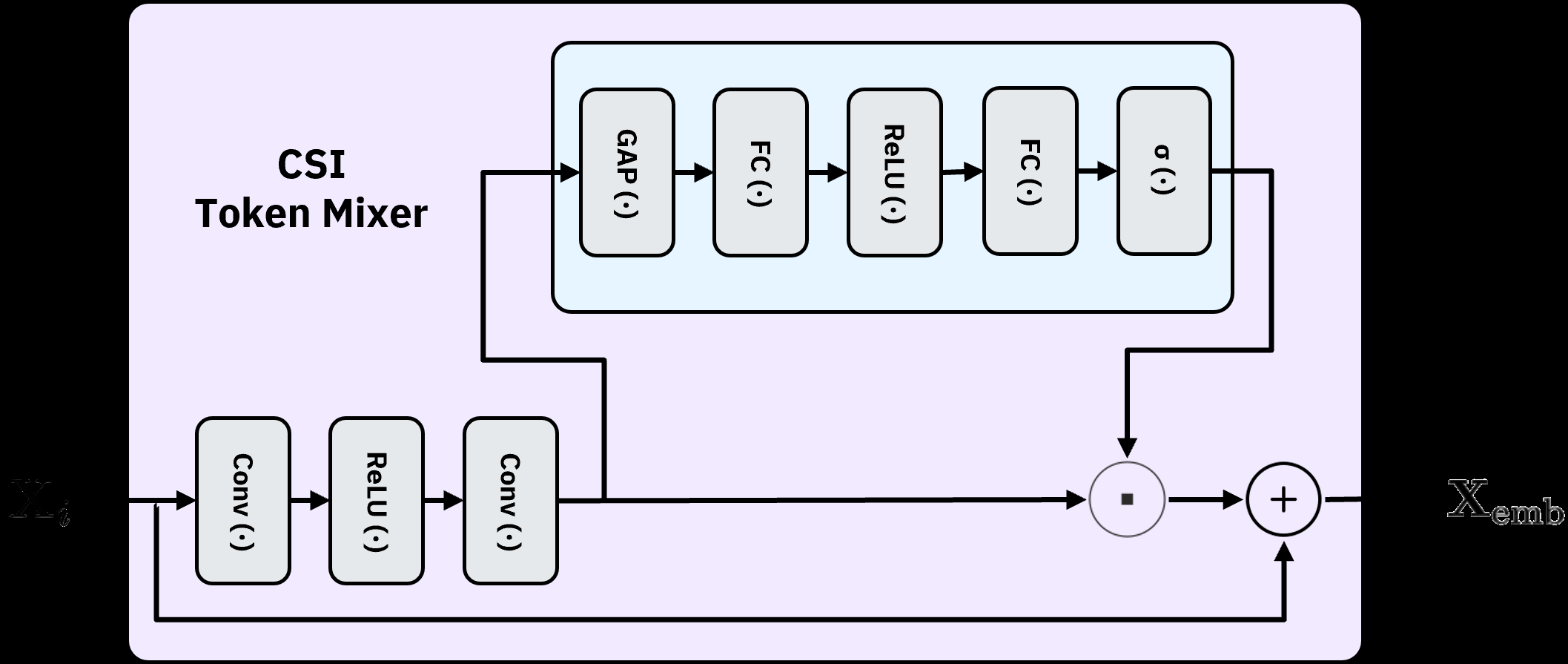
原始摘要
Recent works have demonstrated that attention-based transformer and large language model (LLM) architectures can achieve strong channel state prediction (CSP) performance by capturing long-range temporal dependencies across channel state information (CSI) sequences. However, these models suffer from quadratic scaling in sequence length, leading to substantial computational cost, memory consumption, and inference latency, which limits their applicability in real-time and resource-constrained wireless deployments. In this paper, we investigate whether selective state space models (SSMs) can serve as a hardware-efficient alternative for CSI prediction. We propose MambaCSP, a hybrid-attention SSM architecture that replaces LLM-based prediction backbones with a linear-time Mamba model. To overcome the local-only dependencies of pure SSMs, we introduce lightweight patch-mixer attention layers that periodically inject cross-token attentions, helping with long-context CSI prediction. Extensive MISO-OFDM simulations show that MambaCSP improves prediction accuracy over LLM-based approaches by 9-12%, while delivering up to 3.0x higher throughput, 2.6x lower VRAM usage, and 2.9x faster inference. Our results demonstrate that hybrid state space architectures provide a promising direction for scalable and hardware-efficient AI-native CSI prediction in future wireless networks.