arXiv: 2604.21193 · PDF
Authors: Vipula Rawte, Ryan Rossi, Franck Dernoncourt, Nedim Lipka
Primary category: cs.AI · all: cs.AI
Matched keywords: large language model, llm, retrieval, reasoning, inference, ai system
TL;DR
DAVinCI is a two-stage framework that combines claim attribution (to internal model components and external sources) with entailment-based verification and confidence calibration, improving factual reliability of LLM outputs by 5–20% over verification-only baselines on FEVER and CLIMATE-FEVER.
Key Ideas
- Dual approach: pair attribution with verification rather than treating them independently.
- Attribute claims both to internal LLM components and external retrieved sources.
- Use entailment reasoning plus confidence recalibration for claim checking.
- Release a modular implementation pluggable into existing LLM pipelines.
Approach
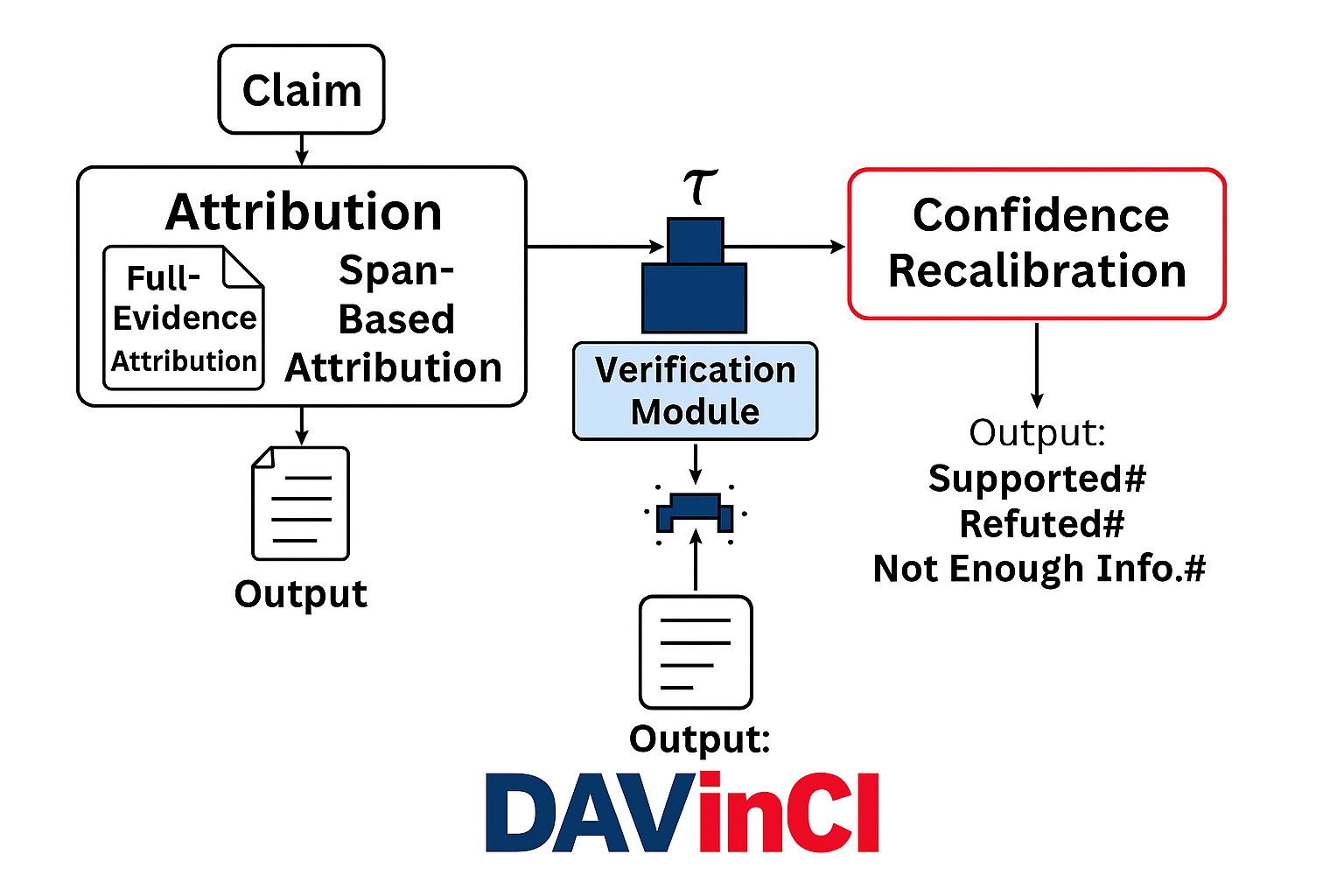
DAVinCI runs in two stages. Stage 1 attributes each generated claim to (a) internal model components and (b) external evidence sources. Stage 2 verifies each claim via entailment-based reasoning, then recalibrates confidence scores. The abstract does not specify the exact attribution mechanism (e.g., attention tracing, gradient-based, or retrieval citation) or which entailment model is used.
Experiments
- Datasets: FEVER and CLIMATE-FEVER (fact-verification benchmarks).
- Baselines: “standard verification-only” systems (names not given in abstract).
- Metrics: classification accuracy, attribution precision/recall/F1.
- Ablations: evidence span selection, recalibration thresholds, retrieval quality.
Results
Reported 5–20% improvement across classification accuracy and attribution P/R/F1 versus verification-only baselines. No absolute numbers, model sizes, or per-dataset breakdowns are disclosed in the abstract, so headline-number scrutiny is limited.
Why It Matters
For practitioners deploying LLMs in regulated domains (healthcare, law, scientific comms), bolt-on attribution+verification is increasingly mandatory. A modular, pipeline-friendly tool that jointly grounds where a claim came from and whether it holds could shorten the path to auditable systems and reduce hallucination risk at serving time.
Connections to Prior Work
- Retrieval-augmented verification: FEVER/CLIMATE-FEVER pipelines, GEAR, KGAT.
- Hallucination detection & mitigation: SelfCheckGPT, FActScore, RARR.
- Citation/attribution for LLMs: WebGPT, Gopher Cite, “Attributed QA” line.
- Confidence calibration: temperature scaling, selective prediction for LLMs.
Open Questions
- What exactly is “attribution to internal model components” — attention, neurons, or something else? The abstract is thin here.
- Does the 5–20% gain hold on open-ended generation (beyond closed-world FEVER-style claims)?
- Cost/latency overhead of the two-stage pipeline versus verification-only.
- Robustness to retrieval failure or adversarial evidence.
- Cross-lingual and domain-shift generalisation (medical, legal corpora are mentioned as motivation but not evaluated).
- How does calibration quality translate to downstream user trust or selective abstention?
Figures
Figure 1: Figure 1 (extracted from PDF)
Original abstract
Large Language Models (LLMs) have demonstrated remarkable fluency and versatility across a wide range of NLP tasks, yet they remain prone to factual inaccuracies and hallucinations. This limitation poses significant risks in high-stakes domains such as healthcare, law, and scientific communication, where trust and verifiability are paramount. In this paper, we introduce DAVinCI - a Dual Attribution and Verification framework designed to enhance the factual reliability and interpretability of LLM outputs. DAVinCI operates in two stages: (i) it attributes generated claims to internal model components and external sources; (ii) it verifies each claim using entailment-based reasoning and confidence calibration. We evaluate DAVinCI across multiple datasets, including FEVER and CLIMATE-FEVER, and compare its performance against standard verification-only baselines. Our results show that DAVinCI significantly improves classification accuracy, attribution precision, recall, and F1-score by 5-20%. Through an extensive ablation study, we isolate the contributions of evidence span selection, recalibration thresholds, and retrieval quality. We also release a modular DAVinCI implementation that can be integrated into existing LLM pipelines. By bridging attribution and verification, DAVinCI offers a scalable path to auditable, trustworthy AI systems. This work contributes to the growing effort to make LLMs not only powerful but also accountable.