arXiv: 2604.21193 · PDF
作者: Vipula Rawte, Ryan Rossi, Franck Dernoncourt, Nedim Lipka
主分类: cs.AI · 全部: cs.AI
命中关键词: large language model, llm, retrieval, reasoning, inference, ai system
TL;DR
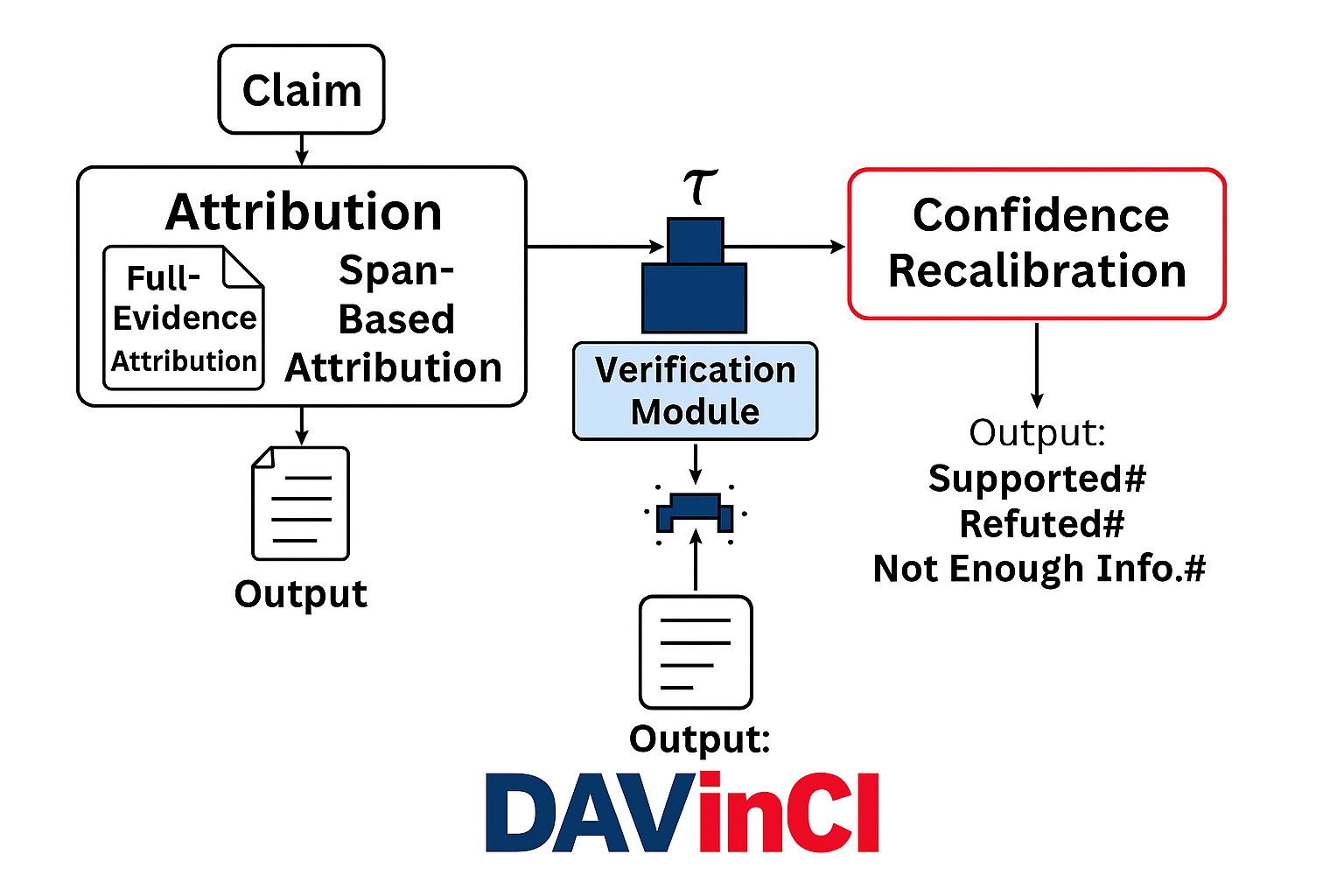
DAVinCI 是一个双阶段框架,把 LLM 生成的声明同时做"归因"和"验证",以提升事实可靠性与可审计性,在 FEVER 等数据集上各项指标提升 5–20%。
核心观点
- LLM 在高风险领域(医疗、法律、科研)因幻觉而缺乏可信度,需要归因与验证并重。
- 仅做验证(verification-only)不足以解释声明来源,归因是补齐可解释性的关键一环。
- 把归因(内部组件 + 外部来源)与基于 entailment 的验证结合,可同时提升准确性与可解释性。
- 提供模块化实现,便于插入现有 LLM pipeline,推动"可审计 AI"。
方法
DAVinCI 分两阶段:
- Attribution:将生成的每条 claim 归因到模型内部组件以及外部证据来源。
- Verification:对每条 claim 用 entailment-based reasoning 判断真假,并做 confidence calibration。 此外包含 evidence span selection、recalibration threshold、retrieval 质量等可调模块。摘要未详述具体架构细节与归因算法形式。
实验
- 数据集:FEVER、CLIMATE-FEVER 等多项事实核查数据集。
- 基线:standard verification-only 方法。
- 指标:分类准确率、归因 precision/recall/F1。
- 消融:逐一评估 evidence span 选择、重校准阈值、retrieval 质量的贡献。
结果
- 在分类准确率、归因 precision/recall/F1 上全面提升 5–20%。
- 消融实验显示三个模块(span 选择、阈值重校准、retrieval 质量)都有独立贡献。
- 摘要未给出具体数值表,仅给出相对提升区间。
为什么重要
- 对构建可信 LLM agent(特别是需要引用证据的 RAG、法律/医疗助手)提供了可直接接入的模块。
- 将"引用出处"和"蕴含验证"合流,降低幻觉风险,利于合规与审计。
- 开源实现降低了在现有 pipeline 中落地事实性保障的门槛。
与已有工作的关系
- 延续 FEVER 系 fact verification 路线,并与 CLIMATE-FEVER 等领域化扩展对齐。
- 与 RAG、self-consistency、self-RAG、以及近年 attribution(如 attributed QA、citation evaluation)工作互补。
- 在 hallucination mitigation 文献(SelfCheckGPT、FActScore 等)基础上,强调"归因 + 验证"的双轨。
尚未回答的问题
- 内部组件归因具体如何实现(attention、neurons、还是 logit-lens 类方法)?可解释性是否经过人工评估?
- 在开放域长文本、代码、多模态场景下是否仍然有效?
- 推理开销与延迟如何,是否适合在线 agent 场景?
- confidence calibration 是否会在分布外数据退化?
- 和更强的 retrieval(web-scale、结构化 KB)结合时,归因粒度能否继续细化?
- 对抗性或刻意误导证据下的鲁棒性未作评估。
论文图表
图 1: Figure 1 (extracted from PDF)
原始摘要
Large Language Models (LLMs) have demonstrated remarkable fluency and versatility across a wide range of NLP tasks, yet they remain prone to factual inaccuracies and hallucinations. This limitation poses significant risks in high-stakes domains such as healthcare, law, and scientific communication, where trust and verifiability are paramount. In this paper, we introduce DAVinCI - a Dual Attribution and Verification framework designed to enhance the factual reliability and interpretability of LLM outputs. DAVinCI operates in two stages: (i) it attributes generated claims to internal model components and external sources; (ii) it verifies each claim using entailment-based reasoning and confidence calibration. We evaluate DAVinCI across multiple datasets, including FEVER and CLIMATE-FEVER, and compare its performance against standard verification-only baselines. Our results show that DAVinCI significantly improves classification accuracy, attribution precision, recall, and F1-score by 5-20%. Through an extensive ablation study, we isolate the contributions of evidence span selection, recalibration thresholds, and retrieval quality. We also release a modular DAVinCI implementation that can be integrated into existing LLM pipelines. By bridging attribution and verification, DAVinCI offers a scalable path to auditable, trustworthy AI systems. This work contributes to the growing effort to make LLMs not only powerful but also accountable.